
目次
- 1 データコンサルタント視点から見るHPE Intelligent Data Platformとデータ管理戦略
- 2 データコンサルタント視点から見るクラウド利用の進化とオンプレミスクラウドの台頭
- 3 データコンサルタント視点から見るSpectrum Virtualizeによるハイブリッド・マルチクラウド環境のデータ管理
- 4 データに基づくインフラ戦略の再考:TCOとワークロード分析から見る「オンプレミス回帰」
- 5 データドリブンな変革プロセス:成熟度アセスメントと継続的改善
- 6 ワークロード分析とTCOに基づくクラウド戦略:ノード課金(VMC on AWS)の最適配置
- 7 データで解明するクラウド移行の障壁:TCOと移行工数の定量的課題
データコンサルタント視点から見るHPE Intelligent Data Platformとデータ管理戦略
データコンサルタントの視点から見ると、HPEは年間の売上高310億ドルというデータに基づき、サーバー、ストレージ、ネットワーク、インフラストラクチャソフトウェア、および技術サポートとコンサルティングサービスといったデータインフラストラクチャおよびデータ管理ソリューションを提供する主要ベンダーです。HPEはストレージの実装に関して顧客に幅広い選択肢を提供しており、これはデータコンサルタントがお客様のデータ保護、データ管理、およびデータ活用戦略を策定する上で重要な要素となります。そのストレージポートフォリオは、プライマリーおよびセカンダリーデータストレージ、ブロックベース、ファイルベース、およびオブジェクトベースといった多様なデータタイプのサポート、スケールアップおよびスケールアウトといったデータアーキテクチャ、さらにInfoSightのようなクラウドベースの予測分析プラットフォーム(運用データ分析にAI/MLを活用)を含んでいます。ストレージアプライアンス、ソフトウェア定義のハイパーコンバージドインフラストラクチャ(HCI)、コンバージドインフラストラクチャ(CI)、およびクラウドベースのサービスといった製品形態は、異なるデータ管理ニーズやデータ処理要件に対応するための柔軟性を提供します。1939年に設立されたHPEは、あらゆる規模の企業に対して実績のある信頼できるサプライヤーであり、「99.9999%以上」という高いデータ可用性保証は、データ保護とBCPにおけるその信頼性データを示すものです。オールフラッシュアレイ(AFA)の売上がこの市場のリーダー企業の一つに数えられる規模であるというデータは、高性能なデータ処理を支えるプライマリーデータストレージ市場におけるHPEのプレゼンスを裏付けています。
HPE Intelligent Data Platformは、エンタープライズインフラストラクチャ基盤を起点とし、ミッションクリティカル、汎用、セカンダリー、およびビッグデータ/AIといった多様なアプリケーションワークロード(大量データの分析処理、トランザクション処理など)間でデータフローとデータ処理リソースの「最適化コンポーザブルシステム」として調整・最適化を図るデータ管理プラットフォームです。HPEブランドのストレージ製品には、ミッションクリティカル、汎用、およびセカンダリーストレージ向けのHPE 3PAR StoreServ、HPE Nimble Storage、HPE Nimble Storage Hybrid、およびHPE StoreOnceなどがあり、これらの異なるデータ重要度(ミッションクリティカル性)やデータタイプ(プライマリー、セカンダリー)に対応するデータ保管機能を提供します。
BlueData Software(どこでも稼働可能)と一体になったHPE Apolloシステムは、AI/ML駆動型のビッグデータ分析(大量データの分析処理)のためのデータ基盤を提供するソリューションです。HPE SimpliVity、HPE Synergy(ストレージと接続)、およびHPE ProLiant(ストレージと接続)は、プライベートクラウド(データ処理環境)の基盤を提供します。さらに、HPEはアマゾン、マイクロソフト、グーグルなどの主要パブリッククラウドもサポートしており、HPEクラウドベースのストレージサービス(HPE Cloud Volumes、HPE Cloud Bank)も提供している点は、ハイブリッド・マルチクラウド環境におけるデータ連携とデータ保管の柔軟性を示唆し、データ管理戦略における多様な選択肢を提供します。
これらの独立したシステム間での「ネイティブデータの移動性」は、それらがクラウド環境と非クラウド環境のどちらに導入されているかを問わず、データのライフサイクル管理(データ保管、保持、アーカイブ、消去)、ハイブリッド開発とテスト(異なる環境間でのデータコピー、データ同期)、ハイブリッド分析(分散データの分析処理)、最新のデータ保護ソリューション(バックアップ、リカバリ)に至るまで、さまざまなデータ関連ユースケースのためのデータやアプリケーションの移動を可能にします。これは、ハイブリッド環境におけるデータモビリティとデータ連携の重要性を示唆するものです。
これらの独立したシステム(データ基盤)のそれぞれに、システムとワークロードの状態を包括的に監視し、相当量の遠隔測定データ(運用データ、パフォーマンスデータ、健全性データ)を生成するセンサーが備わっています。そのすべてのデータは収集され、HPEのクラウドベースのGlobal Intelligence Engine(GIE)に安全に送信されます。このプロセスは、ハイブリッド環境全体からの運用データ収集とデータ統合、および中央集権的なデータ分析プラットフォームによる運用データ分析を示唆します。GIEにおけるAI/MLを活用したデータ分析は、運用データに基づいた異常検知、パフォーマンスボトルネックの特定、および将来的なリソース需要の予測といったデータインテリジェンスを提供することを意味し、データ駆動型運用を支援します。データコンサルタントとして、HPE Intelligent Data Platformがお客様のデータ管理、データ保護、データ活用戦略にどのように貢献できるかをデータ分析に基づき評価し、最適なソリューション導入を支援します。
データコンサルタント視点から見るクラウド利用の進化とオンプレミスクラウドの台頭
データコンサルタントの視点から見ると、Amazon Web Services (AWS)、Google Cloud Platform (GCP)、Microsoft Azureといった主要クラウドサービスは、現在のデータインフラストラクチャにおける主要な選択肢の一つとなっています。しかし、データ保護要件、コストデータ、既存システムとのデータ連携、運用体制といった様々なデータ関連の理由から、全てのワークロード(特定のデータ処理タスクやアプリケーション)をこれらのクラウドサービスに移行させたいと考えるユーザー企業は多くないのが現状です。
このような状況を踏まえ、IT企業やそのパートナーは、「オンプレミスクラウド」、すなわちクラウドサービスのメリット(データ処理リソースの柔軟な調達、スケーラビリティ、運用効率など)をオンプレミスインフラでも実現するための構築サービスに注力する必要があるとデータコンサルタントは提言します。IT企業Leidos傘下のMSPである1901 Groupの最高成長責任者を務めるポール・ウィルキンソン氏が指摘するように、「オンプレミスクラウドのニーズは高まり続ける」という発言は、このようなデータ管理の柔軟性に対する市場の需要がデータに基づき上昇していることを示唆しています。
「オンプレミスクラウド」が求められる背景:データ管理とコストの課題
「オンプレミスクラウド」が求められる背景には、オンプレミスインフラを構築する際にユーザー企業がサーバーやストレージといったデータ保管・処理リソースをデータに基づき過剰に購入しがちであるというコストデータ上の課題があります。クラウドサービスであれば、使用したデータ処理リソースやデータ保管量といったデータ利用量に基づいた従量課金となるため、設備投資(CapEx)が不要である点が対照的です。ただし、システムインテグレーターであるInsight Enterprisesのクラウドおよびデータセンター変革部門のプラクティスディレクターを務めるケント・クリステンセン氏が説明するように、「クラウドサービスは必ずしも安価になるとは限らず、オンプレミスインフラより高額になることもある」というコストデータ上の現実も存在し、ワークロード特性やデータ利用量に基づいた慎重なコスト分析が重要であることを示唆します。Insight Enterprisesにおけるオンプレミスクラウド事業が「年間数百パーセント規模で成長している」というデータや、「オンプレミスクラウドを手に入れようとするユーザー企業は爆発的に増えている」というクリステンセン氏のコメントは、特定のデータ管理要件やコスト要件を持つ企業がオンプレミス環境でのクラウド的なデータ管理アプローチを求めている現状をデータに基づき裏付けています。
「オンプレミス回帰」トレンドとデータ分析
システムのパブリッククラウド移行が進む一方で、パブリッククラウドからオンプレミスに戻る「オンプレミス回帰」を選ぶ企業が相次いでいるという市場トレンドデータも観測されています。このオンプレミス回帰の背景と原因をデータコンサルタントの視点から分析します。調査会社IDCが2022年に発表した調査データによると、パブリッククラウドを利用している回答企業の71%が、パブリッククラウドに配置しているアプリケーションの一部または全てを、2023年末までにオンプレミスに移行することを計画している点は、このトレンドの規模を定量的に示すものとして非常に重要です。
企業がパブリッククラウドからオンプレミスに戻る主な理由は、データ管理、コスト、セキュリティ、運用といったデータ関連の側面に関連しており、これらの理由の詳細は以降の分析で明らかになります。データコンサルタントとして、これらの市場トレンドデータと個別企業のデータ保護要件、コスト構造、運用能力を総合的に分析し、最適なIT基盤戦略の意思決定を支援します。
データコンサルタント視点から見るSpectrum Virtualizeによるハイブリッド・マルチクラウド環境のデータ管理
データコンサルタントの視点から、ローエンドからミッドレンジストレージを含む様々な環境でハイブリッドクラウドを実現するためのデータ管理ソリューションとして、Spectrum Virtualizeのデータプール機能によるパフォーマンス・コスト最適化
Spectrum Virtualizeには、複数のストレージボリューム(異なる性能やタイプのストレージリソース)を束ねて使用するデータプール機能があります。SV4PCにも、クラウド側の用意するボリューム(クラウドストレージリソース)を束ねて使用する同様の機能があります。これは、パフォーマンスを要求するアプリケーションに対して、後から高速な区分(例えば、SSDベースのボリューム)のストレージ・ボリュームを追加可能にし、データアクセスパターンに関するデータ分析に基づき、アクセスの多い「ホットデータ」部分だけに高速なストレージを使えるようにするデータ階層化機能を利用することで、ストレージにかかるコストデータダウンを実現します。データコンサルタントとして、このデータプール機能は、データ量やアクセス頻度といった運用データに基づいてストレージリソースを効率的に利用し、パフォーマンスとコストのバランスを最適化するための重要な機能であると評価します。
データコンサルタントおよびデータアナリストの視点から、マルチクラウド環境におけるデータセキュリティ、特にゼロトラストモデル導入に伴うデータアクセス管理の課題、およびソブリンクラウドのような選択肢の意義について分析します。
マルチクラウド環境におけるデータセキュリティ、特にゼロトラストモデルの実現においては、データアクセス管理の変革が重要な課題となります。従来のセキュリティソリューションでは、データ資産へのアクセス保護の基盤としてIPアドレスに基づく制御が不可欠でした。データベースと通信するアプリケーション、ホストやサービスにアクセスするユーザー、そしてクラウド内で通信するサーバーなど、データへのアクセスはIPアドレスに基づいて許可または制限されてきました。しかし、企業がクラウドへ移行し、インフラやデータへのアクセスがより動的になりIPアドレスが頻繁に変更される環境では、このIPアドレスに依存した管理手法は維持することが非常に困難になり、運用が複雑化します。データコンサルタントとしては、データ資産へのセキュアなアクセス制御を維持するためには、IPアドレスだけでなく、ユーザーID、デバイスの状態、アクセス元のコンテキスト、取り扱うデータの感度といった多様な要素に基づいた、よりきめ細やかなアクセス制御設計が必要であると認識しています。
データパイプラインや分散データ処理ワークロードにおいて、システム間(マシン間)の通信セキュリティ確保はゼロトラスト環境の中核要素となります。データ収集、前処理、分析、そして結果のデプロイといった一連のデータ処理プロセスでは、多くのシステムが相互に通信します。チケットシステムへの依存といった旧来型のITILベースの手法は、今日の動的なクラウド環境におけるデータ処理ワークロードの迅速なデプロイやスケーリングに伴うセキュリティ要件(セキュアなマシン間通信設定、API連携における認証・認可など)に対応するにはスピードが遅く、手間がかかり、柔軟性に欠けます。セキュアかつ効率的なマシン間通信の確立は、データフロー全体のセキュリティと整合性を保つ上で不可欠です。
また、ユーザーやデータ処理を行うマシンの数が数百、数千と増加するにつれて、手動プロセスに依存した従来のアイデンティティおよびアクセス管理(認証、認可、プロビジョニング)はスピードが遅く、非効率となり、データへのセキュアなアクセスを大規模に管理する上で効果が上がりません。トークン、キーカード、パスワードといった従来のセキュリティ対策は、ITスタッフの直接的な介入を必要とし、これは特に大規模なデータ環境におけるアクセス管理や定期的なアクセス権限の棚卸しにおいて膨大なリソースと時間を消費する課題となります。自動化されたID・アクセス管理(IAM)ソリューションの導入は、データへのセキュアかつ効率的なアクセスを提供し、データ管理リソースの負担を軽減する上で不可欠です。
このようなデータセキュリティおよびガバナンスの要求が高まる中、ソブリンクラウドのようなクラウド形態が注目されています。例えば、「Fujitsu クラウドサービス powered by Oracle Alloy」のようなソブリンクラウドは、国内データセンターでのサービスの運用・管理を行うことから、運用の透明性を担保し、データとその保存場所を国内で制御できるという重要な特徴を持ちます。これにより、「データ主権」「運用主権」「法的主権」「セキュリティ主権」の4つの主権を確保できると謳われています。特に、内閣府の経済安全保障推進法における特定社会基盤役務の安定的な提供確保に関する制度や、重要情報を扱うシステムの要求策定ガイドなど、特定の法規制への対応能力は、データコンサルタント/アナリストが重要システムに蓄積された機密性の高いデータをクラウド化し、データに基づいた経営改革を推進する際に重要な考慮事項となります。
ソブリンクラウド上で、特定の主権要件を満たしつつ、生成AIを含む150以上のOracle Cloud Infrastructure (OCI) のサービスを利用できることは、データ分析、MLモデル開発、そして新しいデータ駆動型アプリケーション構築において大きなメリットとなります。重要システムに蓄積されたデータを、こうした特定の主権要件を満たしながらクラウド上で安全に活用できることは、データに基づいた意思決定の迅速化や、ビジネスプロセスの効率化に貢献するポテンシャルを持っています。
結論として、マルチクラウド環境におけるデータセキュリティ、特にゼロトラストの実現には、従来のIPベースのアクセス管理手法の限界を理解し、データ主権や法規制遵守といった要件を満たす基盤(ソブリンクラウドなど)を検討しつつ、ユーザーやマシンに対する自動化されたきめ細かいデータアクセス管理と、データ処理ワークロード間のセキュアな通信確保を組み合わせた多角的なアプローチが不可欠です。これにより、データに関わるリスクを低減し、安全な環境でデータ活用のポテンシャルを最大限に引き出すことが可能となります。
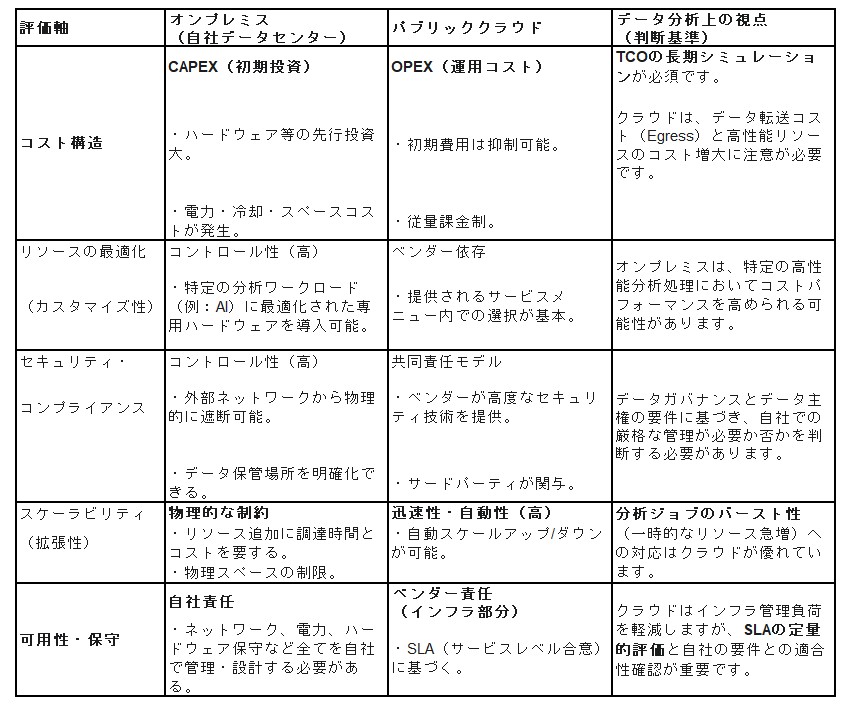
データに基づくインフラ戦略の再考:TCOとワークロード分析から見る「オンプレミス回帰」
企業がアプリケーションを稼働させるインフラとして、オンプレミス、パブリッククラウド、あるいは両者を併用するハイブリッドクラウドという選択肢が存在します。市場のトレンドとしてはパブリッククラウドの採用が加速していることは事実です。
しかし、2022年に発表した在る調査会社のデータによれば、パブリッククラウド利用企業の約7割程度が、クラウド上のアプリケーションの全部または一部をオンプレミスへ移行する計画(2023年末まで)を立てていました。
この「オンプレミス回帰」とも呼べる動向は、単なる揺り戻しではなく、企業が初期のクラウド移行(リフト&シフト)を経て、よりデータドリブン(データに基づいた)な視点でインフラの最適配置を再評価し始めた結果と分析できます。
本稿では、この回帰の背景にある要因を、特にデータとコストの観点から分析し、オンプレミスとパブリッククラウドの特性をTCO(総所有コスト)とワークロードの視点で比較・整理します。
📥 なぜ「オンプレミス回帰」がデータ分析の対象となるのか
企業がパブリッククラウドからオンプレミスへの移行を検討する主な要因は、定性的な理由と定量的なデータ(数値)に基づいています。
TCO(総所有コスト)の再評価とコスト削減: クラウドの利用料(OPEX)は、特にデータ転送量(Egress Fee)や高性能リソースの利用が増加するにつれ、当初の試算を上回り、予測が困難になるケースがあります。オンプレミス回帰は、この「変動コストの可視化と制御」、および「長期的なTCOの最適化」を目指す動きと分析できます。
データの局所性(Data Gravity)とネットワーク遅延: AI/MLやビッグデータ分析の進展により、処理対象のデータ量が爆発的に増大しています。大量のデータをクラウドに転送・処理する際の**ネットワーク遅延(レイテンシー)**が、リアルタイム分析などのパフォーマンス要件を満たせないボトルネックとなるため、「データ発生源の近く(オンプレミスやエッジ)」での処理が見直されています。
セキュリティとデータガバナンス(法令順守): 銀行口座情報や事業秘密のような機密データ、あるいは特定の規制(データ主権)対象となるデータは、その保管場所やアクセス制御を厳格に管理する必要があります。パブリッククラウドの共同責任モデルでは要件を満たせないと判断される場合、コントロール性の高いオンプレミスが選択されます。
初期の移行計画とワークロード分析の不備: 「クラウドサービスに関する知見の不足」や「移行計画の不備」の根本には、「アプリケーションとデータの特性(ワークロード)」を事前に十分分析せず、画一的にクラウドへ移行した課題が潜んでいます。
📊 インフラ選定の判断軸:ワークロード・アセスメント
インフラを決定する際、従来は「リソース調達」と「インフラ管理」の容易さが重視されがちでした。しかし、データ中心の意思決定では、以下の2点を最優先で分析・評価する必要があります。
ワークロード特性の分析:
アプリケーションが求めるコンピューティングリソース(CPU, GPU, メモリ)は何か。
処理のバースト性(常時稼働か、一時的な高負荷か)はどうか。
パフォーマンス要件(求められるレイテンシー)はどの程度か。
データ特性の分析:
扱うデータの量、機密性、保存期間、更新頻度はどうか。
データ転送の頻度と方向(流入か流出か)はどうか。
これらの分析に基づき、「どのワークロードを、どこに配置する(Right Placement)」かを定量的に判断することが、ハイブリッドクラウド戦略の核心です。
「オンプレミス回帰」とは、単にクラウド化の失敗を意味するのではなく、企業がデータとワークロードの特性を定量的に分析し、TCO、パフォーマンス、ガバナンスの観点からインフラの「最適配置」を再定義するプロセスです。
重要なのは二者択一ではなく、両者のメリットを活かし、自社のビジネス要件に最適なハイブリッド戦略を設計・実行することです。
データドリブンな変革プロセス:成熟度アセスメントと継続的改善
テクノロジーの導入は、単一のタイムラインで完了するものではなく、データに基づき継続的に評価・改善されるプロセスとして捉える必要があります。
特定の組織において、あるテクノロジーが導入されていない状況は、単なる「遅れ」ではなく、その組織の現在の「成熟度フェーズ」を反映しています。各フェーズは、データガバナンスポリシー、実装されている機能、そしてデータに基づく意思決定のレベルによって定義されます。
実際、導入したテクノロジーやソリューションが、運用データの分析結果(パフォーマンス、利用率、ROIなど)に基づき、**再加工や再実装(チューニング)を必要とするケースは少なくありません。したがって、導入プロセス自体に、これらのデータに基づく評価と軌道修正のための時間(フィードバックループ)**を設計段階から組み込むことが不可欠です。
📉 ビッグバンアプローチの非現実性とデータ分析の重要性
大規模で複雑なIT組織において、全てのシステム、プロセス、戦略的方向性を一度に、あるいは組織全体で足並みを揃えて変革(ビッグバンアプローチ)しようと期待することは非現実的です。
むしろ、データ(メトリクス)に基づかない一律の変更は、既存のシステム(特にデータ基盤や基幹システム)を不安定化させ、実装しようとしているソリューションの価値そのものを損なうリスクを内包しています。
変革のプロセスと依存関係をデータモデリングや依存関係マップとして可視化することは、論理的な改善の順序性を明確にします。さらに重要なのは、アプリケーション環境全体を単一のエコシステムとして捉え、データ分析の視点を持つことです。
改善はどの部門、どのフェーズでも実行可能ですが、その変更がもたらす影響を定量的に評価・予測することが重要です。
その変更は、他のシステムやプロセスに良い影響として波及する(スケールする)でしょうか?
それとも、特定の部門内に留まり(サイロ化し)、全体最適には寄与せずに消失するのでしょうか?
📊 「技術的負債」のデータ分析とサイロ化の課題
「断片化した官僚主義」という表現は、組織に対する批判的な描写に聞こえるかもしれません。しかし、データコンサルタントの視点から分析すると、これは多くのIT組織が直面する現実的な状態を示しています。
現在のITシステムの複雑性は、過去の世代(前任者)によるアーキテクチャの選択、プロセスのルール、導入技術の積み重ねによって形成されています。これらの過去の意思決定が「技術的負債」として蓄積され、現在の組織構造やデータの流れ(データリネージ)に色濃く反映されています。
事実、ある調査データでは23%を超える企業が、「技術的負債」をデジタルトランスフォーメーション(DX)の成功を妨げる最大の障壁であると回答しています。これは、データ活用の速度(Time to Insight)や、新しいソリューション導入のROIに直接的な悪影響を与えていることを示唆しています。
IT組織は単にアプリケーションを実装しているのではなく、潜在的に数十年の寿命を持つ、**複雑な「データエコシステム」**を構築・運用しているのです。 完璧なシステム(=変化が不要な状態)は存在せず、その瞬間(例:リリース時)の完璧さは、次のビジネス要件やデータ量の増大によって時代遅れになります。
🚀 継続的改善のためのデータ戦略(DataOps)
重要なのは、「官僚主義」や「サイロ化」といったラベルを貼ることではなく、組織構造とデータアーキテクチャを継続的に前進・改善させるメカニズムを構築することです。
官僚主義的な仕組みや組織の分断(フラグメンテーション)は、大規模で複雑なシステムを運用する上で、ある程度のガバナンスや専門性を担保するために必要悪である側面もあります。
私たちは、以下の問いに対する答えを、データに基づいて導き出す必要があります。
現状の有効性評価(As-Is分析): 現在の組織構造と、それが運用するアプリケーション環境(データプラットフォーム)は、ビジネス上の意思決定やデータ活用にどれだけ貢献していますか?(KPI、メトリクスによる評価)
将来の方向性(To-Be設計): データエコシステム全体を改善し続けるために、最もインパクト(ROI)の大きい変革の方向性と、それを実現するメカニズム(例:DataOpsの導入、データガバナンス体制の刷新)は何ですか?
☁️ ハイブリッドクラウド環境におけるデータ戦略
多くのIT組織にとって、複数のデータセンター(オンプレミス)と複数のパブリッククラウドプロバイダーを併用する「ハイブリッド/マルチクラウド」環境は、すでに日常的な現実です。
この環境は、データ管理の複雑性を飛躍的に増大させます。データコンサルタントとしては、この複雑な環境をより管理しやすくするために、テクノロジーの観点から以下のようなデータ戦略を追求することが求められます。
データ配置(Data Placement)の最適化
データガバナンスとセキュリティの担保
データ転送コスト(Egress Fee)を含むTCOの最適化
ワークロード分析とTCOに基づくクラウド戦略:ノード課金(VMC on AWS)の最適配置
クラウド移行におけるコスト削減を実現するためには、データに基づくクラウドサービスの「最適配置(Right Placement)」が不可欠です。
VMC on AWS(VMware Cloud on AWS)の活用においても、一般的に言われる「2:8の法則(パレートの法則)」に類似した傾向がデータ分析から見られます。
重要なのは、移行対象となる仮想マシン群のワークロード・アセスメント(事前分析)です。ストレージサイズ、CPU/メモリ使用率(平均・ピーク)、I/O特性といった定量的な指標に基づき、仮想マシンをセグメント化します。
例えば、以下のようなデータドリブンなアプローチが考えられます。
ワークロード分析: 全仮想マシン(例:500台)の稼働データを分析します。
セグメンテーション:
高リソース(高稼働)群(例:100台): リソースを常時8割使用している、高負荷・特定ミッションクリティカルなマシン。
低リソース(低稼働)群(例:400台): リソース使用率が2割程度の、集約可能なマシン。
最適配置の決定:
高リソース群: インスタンス単位の課金(Amazon EC2など)や、特性に合わせたSaaSの利用がTCO最適化に繋がるか、コストシミュレーションを実施します。
低リソース群: VMC on AWS(ノード単位課金)へ高集積で移行し、ノード課金のメリットを最大化します。
このように、インスタンス単位で課金されるIaaS/SaaSと、ノード単位の課金で多数の仮想マシンを集約可能なVMC on AWSの特性をデータに基づいて見極め、使い分けることで、最もコスト効果の高いクラウド導入が可能になります。
📈 定量的な移行成果:コスト削減のデータ分析
実際、関西のある企業の事例では、100システムのクラウド移行検討時に、当初の試算(移行作業3億円、5年間の利用料15億円)というデータが存在しました。
ここでVMC on AWSを採用し、既存インフラチームが保有するスキル(ライブマイグレーション技術)を活用する戦略に切り替えた結果、クラウド利用料を試算の3分の1に圧縮するという定量的な成果を出しています。
これは、ヴイエムウェアの高集約技術が、ノード課金モデルにおいてコスト削減に直結することを実証したデータと言えます。VMC on AWSをオンプレミスとパブリッククラウドの中間に位置する戦略的選択肢としてポートフォリオに組み込み、TCOとSLA(サービスレベル合意)に基づき最適配置することで、従来のコストの壁を突破し、大幅なコスト削減が実現します。
📊 長期的なゴール設定がTCOシミュレーションを変える
VMware Cloudの活用は、クラウド化への技術的なハードルを下げ、より戦略的な議論を可能にします。ここで重要になるのが、5年、10年といった長期的な視点でのゴール設定と、それに基づくTCO(総所有コスト)シミュレーションです。
ゴール設定(KPI)を明確にすることで、クラウド利用のコスト評価(損得勘定)の算定方法そのものが変わります。
例えば、ゴールが「注力分野へのエンジニアリソースの『選択と集中』」である場合、クラウド活用は単なるインフラコストの変動ではなく、「人的資本(エンジニア工数)の再配置」という経営効果として定量化されます。既存インフラの運用保守から解放されたエンジニアを、事業変革プロジェクトへ振り向けることが可能になるためです。
TCOシミュレーションにおいても、仮にVMC on AWSの採用が、オンプレミスのシステム更改と比較して初期コスト(例:2倍)がかかったとしても、長期的な累計コストのシミュレーションでは、数年後にコストが逆転する(クラウドの方が安価になる)ケースが予測される場合があります。
従来の5年単位といったハードウェアの拡張タイミングに縛られないインフラの柔軟性(スケーラビリティ)がもたらすビジネス価値を定量化できれば、クラウド導入は積極的に検討すべき戦略となります。
📉 リスクの定量化としての災害対策(DR)
TCOの算出によるコスト削減効果は、どのような場合でも必要とされる基本的な定量的評価要素です。
その中でも「災害対策(DR)」は、コスト削減策として打ち出しやすいテーマです。なぜなら、DRは「リスクの最小化」というビジネスインパクトと、「注力分野へのビジネスシフト(DRサイトの有効活用)」といった戦略的な側面を定量的に関連付けやすいためです。
DRコストの最適化は、TCO分析とリスク分析(RPO/RTO)の双方からアプローチできるため、データに基づいた検討を進めやすいテーマと言えます。
データで解明するクラウド移行の障壁:TCOと移行工数の定量的課題
企業がクラウド利用を検討する背景には、TCO(総所有コスト)の最適化、CAPEX(資本的支出)からOPEX(事業運営費)への転換によるキャッシュフローの平準化、開発スピード向上といった定量的な経営目標が存在します。
しかし、実際のクラウド化プロジェクトが計画通りに進まないという現実があります。この遅延要因をデータ分析の視点から分解すると、大きく2つの障壁に集約されます。
移行プロジェクト工数の肥大化(Time to Valueの遅延): 既存システムのアーキテクチャ見直し(リファクタリング)、クラウド特有のスキルセット習得、OSやライセンスの互換性問題への対応など、移行に必要な工数(人月)が当初の試算を大幅に超過し、価値創出までの時間が長期化する問題です。
TCO(総所有コスト)の不確実性と増大リスク: スキル習得コスト、想定外のデータ転送費用、従量課金モデルのコスト予測の難易度により、移行後のランニングコストがオンプレミス(既存環境)のTCOを上回るリスクです。
これらの課題に対し、「VMC on AWS」が移行プロジェクトのコスト構造にどのような影響を与えるか、特にコストの観点から分析します。
VMC on AWS:ハイブリッド戦略におけるデータ分析の起点
VMC on AWSは、AWSのグローバルインフラ上で稼働するVMware SDDC(Software-Defined Data Center)サービスです。ハイパーバイザー以上のスタックはオンプレミスと同一のVMwareソフトウェアで構成されています。
データコンサルタントの視点では、これは以下の3つの重要な価値を持ちます。
運用データとプロセスの一貫性: オンプレミスと同一のアーキテクチャ(vSphere)であるため、既存の運用監視プロセスや取得データをそのまま活用でき、運用の一貫性が担保されます。
低工数での移行(リフト&シフト): アプリケーションの改修(リファクタリング)を最小限に抑え、移行工数を大幅に削減します。
データ連携の優位性: AWSのネイティブサービス(データウェアハウス、分析基盤など)へ直接アクセス可能であり、オンプレミスのデータを分析基盤へシームレスに連携できます。
インフラの変遷と「ハイブリッド」の現実:データから見る最適配置
インフラのトレンドを時系列データとして分析すると、vSphereの登場による仮想化(P2V)が急速に進んだ後、クラウドが採用されました。しかし、クラウドが仮想サーバーを完全に置き換えるのではなく、両者は「併用(すみ分け)」されています。
このデータが示す現実は、多くの基幹システム(SoR)が仮想サーバー基盤上で稼働しており、その複雑な依存関係やパフォーマンス要件から、短期間でのパブリッククラウド(IaaS/PaaS)への移行が困難であるということです。この結果、ハイブリッド環境が常態化し、クラウドへの移行スピード(月次移行VM数など)は徐々に鈍化する傾向が見られます。
「移行時間の壁」がもたらすTCOへの悪影響
移行プロジェクトが長期化する(時間がかかる)場合、データ分析の観点から最も問題視すべきは「TCOの非効率」です。
移行が遅れると、既存のオンプレミスハードウェアの保守切れ(EoL)のタイミングで、不必要なハードウェア更新投資(CAPEX)が発生します。
この投資は、数年後のクラウド移行を見越して「ピーク時に合わせた余裕を持ったサイジング」で行われがちですが、クラウド移行が進むにつれてオンプレミス側は「過剰なリソース(遊休資産)」となり、深刻なコストの無駄を発生させます。
この「5年ごとの過剰投資サイクル」が、フルクラウド化に至らない限り繰り返され、TCO削減の大きな足かせとなります。
📊 事例分析(ゼンリンデータコム):移行リードタイム短縮の定量的効果
この「移行時間の壁」を突破した事例として、ゼンリンデータコムが挙げられます。同社はITインフラのフルクラウド化に向け、700台の仮想サーバーをVMC on AWSへ移行しました。
VMC on AWSの採用により、アプリケーションの修正・開発工数ゼロを実現し、オンプレミスと同一の運用プロセスを継続できました。
結果として、移行にかかる総コストと管理工数を大幅に削減し、想定スケジュールを前倒しで完了させています。これは、VMC on AWSが移行のリードタイムを劇的に短縮し、TCOの非効率なサイクルを断ち切ることを示す実データです。
「コストの壁」の突破:課金モデルのデータ分析と最適化
では、「コストの壁」自体はどのように突破すべきでしょうか。 完全クラウド化後のステージでは、ワークロードの特性(データ)に基づき、ネイティブなAWSサービスとVMC on AWS(仮想サーバー)間での最適配置の**再調整(チューニング)**が継続的に発生すると想定されます。
この理由は、ネイティブ・クラウドサービス(一般的にインスタンス単位の従量課金)と、VMC on AWS(ノード単位の課金)の料金構造が根本的に異なるためです。
VMC on AWSは、ホスト(物理サーバー)単位(最低2ノードから)で購入するサービスです。 コスト削減の最大のポイントは、「仮想マシンの集約度」というKPI(重要業績評価指標)を最大化することにあります。
高集約度の場合(コスト効率◎): 1ノード(ホスト)に多くの仮想マシンを詰め込む(高密度で稼働させる)ことができれば、仮想マシン1台あたりのコスト単価は相対的に劇的に安くなります。特にWindows Serverライセンス(Option)などが必要な場合、この効果はさらに大きくなる可能性があります。
低集約度の場合(コスト効率×): 逆に、事前のサイジングを誤り集約度が上がらない(ノードが低稼働の)場合、リソースの無駄がそのままコスト増となり、インスタンス課金より割高になります。
したがって、VMC on AWSへの移行は、事前のワークロード・アセスメント(現状の稼働データ分析)と、適切なサイジング(将来の需要予測)が、TCO削減の成否を分ける鍵となります。