目次
- 1 Google Cloudのデータオペレーション最適化
- 2 データコンサルタント視点からの改善提案: 適切なデータウェアハウスインフラストラクチャの選択
- 3 データコンサルタント視点での改善提案: データウェアハウスのスケーラビリティと最新ニーズへの対応
- 4 理想的なクラウドデータウェアハウスモダナイゼーションアーキテクチャ
- 5 データウェアハウスは賞味期限切れか?
- 6 脱構築型データウェアハウスの設計: 柔軟性とリアルタイム処理の実現
- 7 データウェアハウスとデータレイクが抱える新時代への適応課題
- 8 従来型データウェアハウスを超える次世代ツールの「分析対象」
- 9 クラウドデータウェアハウスのモダナイゼーションが求められる背景
- 10 既存のデータインフラストラクチャの課題
Google Cloudのデータオペレーション最適化
1. システムエンジニアリングの自動化による効率向上 Google Cloudは、データ分析の業務負荷を軽減するため、システムエンジニアリングのタスクを自動化し、データオペレーションをシンプルにするアプローチを採用しています。特に、BigQueryのようなクラウドデータウェアハウスは、データベース管理者(DBA)の負担を大幅に軽減し、従来のような定期的なメンテナンスの必要がないため、イノベーションと戦略的計画に時間を割けるようになります。これにより、導入やスケールアップが迅速かつシームレスになります。
データコンサルタントの推奨アプローチ:
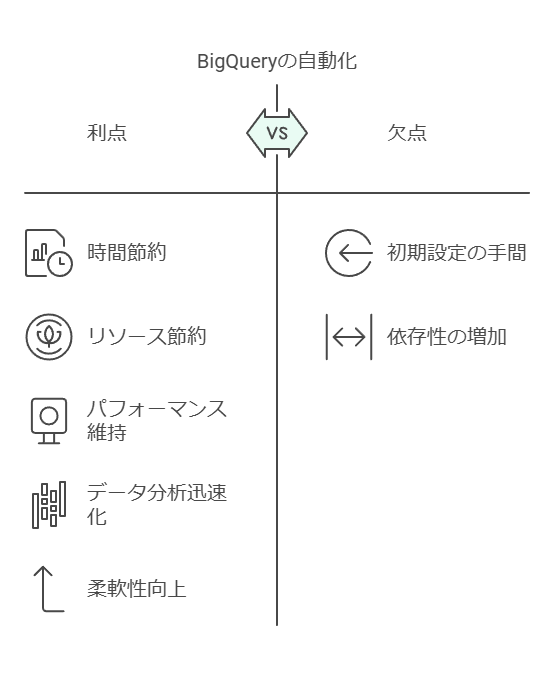
自動化による時間の最適化: システムエンジニアリングの自動化により、DBAやIT部門はメンテナンスから解放され、戦略的な活動に集中できます。特に、データ分析やAI/MLモデルの導入など、付加価値の高い活動に注力することが可能です。
迅速なスケーラビリティ: 自動スケール機能により、急速な需要の変化に対しても柔軟に対応でき、事前の複雑な設定や管理が不要です。
2. コストとインフラ管理の最適化 Google Cloudのデータウェアハウスは、パフォーマンスの自己管理とスケーラビリティに優れており、基盤インフラに対する費用や管理の負担が軽減されます。特に、従来のノードベースのシステムやオンプレミスの大規模並列処理(MPP)システムに比べ、コンピューティングとストレージを分離し、独立してスケール可能なモデルがビジネスのアジリティを向上させます。
データコンサルタントの推奨アプローチ:
コストの柔軟性向上: コンピューティングリソースを必要な時にのみ使用し、無駄な稼働を避けることで、コストを大幅に抑えることが可能です。これは、従来型のクラウドやオンプレミスのシステムに比べ、費用対効果が高くなります。
オンデマンドでのリソース管理: ストレージとコンピューティングのレイヤを分離することで、リソースの最適な割り当てが可能となり、業務ニーズに応じた柔軟な対応が実現します。
3. BigQueryのサーバーレスモデルとクエリパフォーマンスの自動化 Google CloudのBigQueryは、サーバーレスのデータウェアハウスとして、クエリのパフォーマンスを自動で管理し、オンデマンドでリソースをプロビジョニングします。このアプローチは、オンプレミスや他のクラウド環境に比べ、ノードやクラスタの管理が不要で、データ量に応じたスケールと最適なパフォーマンスを提供します。
データコンサルタントの推奨アプローチ:
パフォーマンスの自動管理: データ量に応じてクエリのパフォーマンスを自動で最適化するため、手動の調整が不要となり、時間とリソースの節約が可能です。
クエリ最適化の負担軽減: 複数のデータコピーやウェアハウスの作成に費やす時間を削減し、ビジネスに必要なデータ分析を迅速に提供できます。特に、過去にアクセスされていないデータに対しても同等のパフォーマンスを維持する点は、データ活用の柔軟性を大幅に向上させます。
Google Cloudによるデータオペレーションの自動化と柔軟なインフラ設計
Google Cloudの自動化されたデータオペレーションとサーバーレスアプローチは、企業のデータ管理に大きな変革をもたらします。これにより、DBAの作業負担が軽減され、ビジネスの迅速なスケーラビリティを実現しつつ、コストとリソースの最適化が可能です。また、BigQueryの自動クエリパフォーマンス管理により、データ分析の効率を最大化し、柔軟かつ効率的なデータ運用が可能となります。
データコンサルタント視点からの改善提案: 適切なデータウェアハウスインフラストラクチャの選択
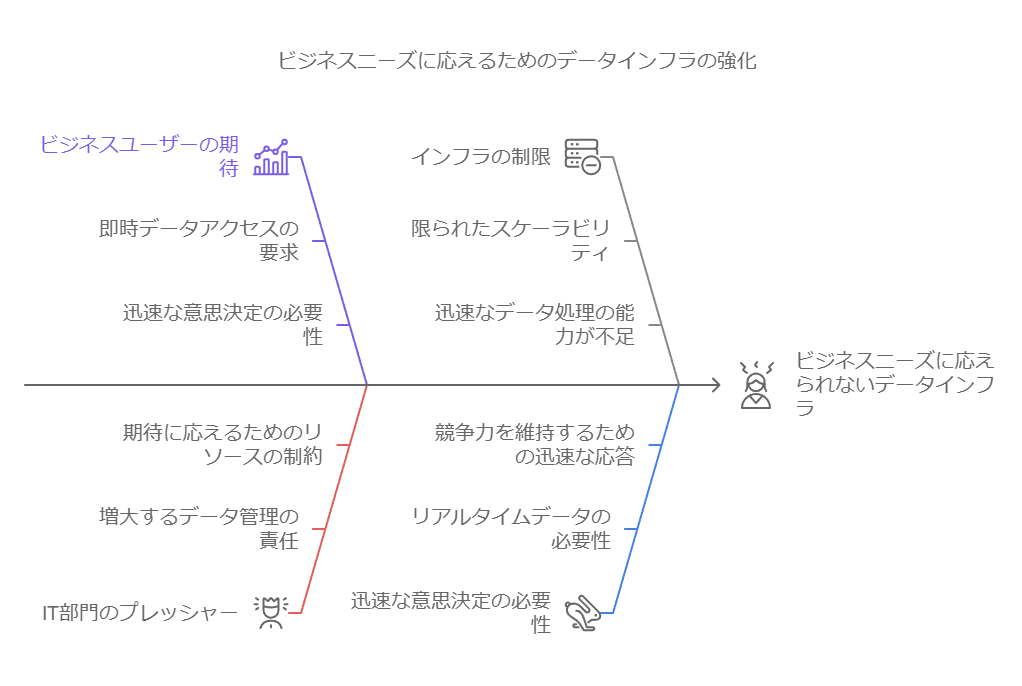
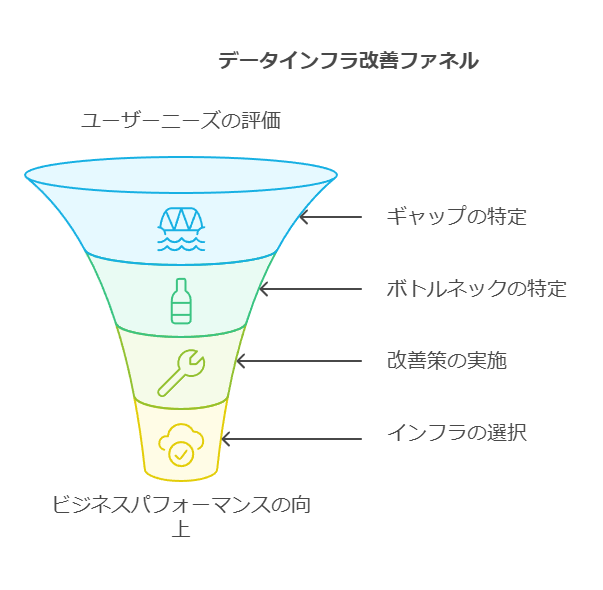
1. データインフラへのプレッシャー増大と課題認識 ビジネスユーザーがデータの価値と分析の可能性を理解し始めると、IT部門にはその期待に応えるプレッシャーが増します。すべてのユーザーが最新のデータへ即時アクセスし、迅速な意思決定を行うことを望んでいます。しかし、多くの企業はこれをサポートするためのインフラが未整備です。
データコンサルタントの推奨アプローチ:
ユーザーのニーズと現行システムのギャップを可視化: IT部門がデータの提供と分析環境を迅速に提供するためには、現行インフラのボトルネックを特定し、改善策を明確にする必要があります。データアクセスのタイムリーさがビジネスパフォーマンスにどれだけ影響を与えているかを評価し、最適なデータウェアハウスインフラを選定することが重要です。
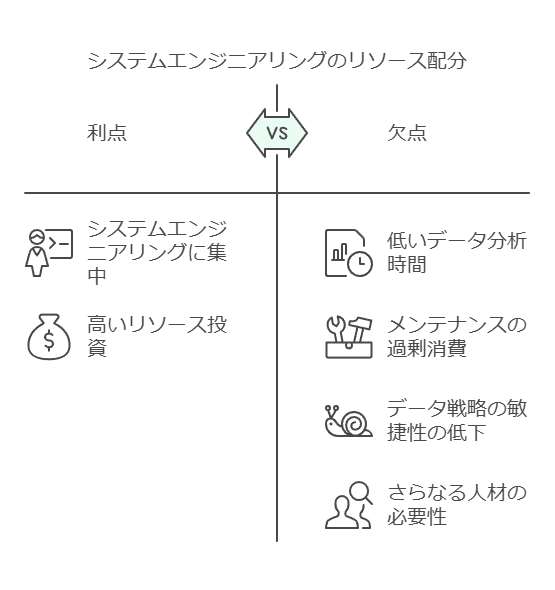
2. システムエンジニアリングにおける非効率性 Googleが関わった多くの企業では、システムエンジニアリングに大半のリソースが費やされており、データ分析に充てられる時間は15%程度という調査結果が出ています。これは、メンテナンス作業が過剰にリソースを消費している現状を示しています。時代遅れのシステムに依存し続けることで、データ戦略のアジリティは阻害され、さらなる人材投入が必要になるという悪循環に陥ります。
データコンサルタントの推奨アプローチ:
リソース割り当ての再評価: システムエンジニアリングやメンテナンスに費やす時間とリソースを再評価し、非効率を排除する手法を検討します。クラウドネイティブなソリューションへの移行や、自動化されたツールの導入により、メンテナンスにかける工数を削減し、データ活用に割ける時間を増やすことが鍵となります。
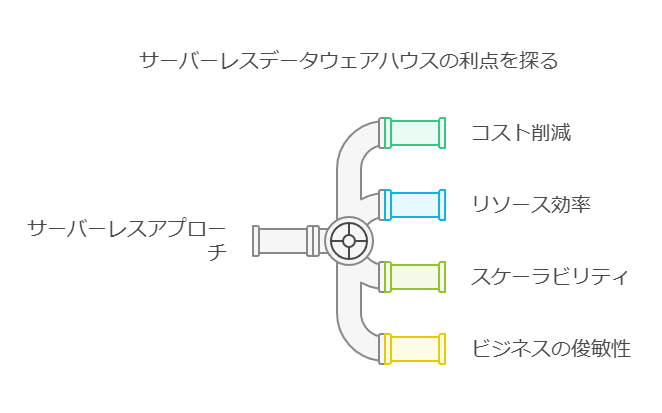
3. クラウドデータウェアハウスの潜在的なメリット 従来のハードウェア依存のデータウェアハウスは、調整や維持管理に時間がかかり、アジリティの向上を阻害してきました。サーバーレスモデルを採用すれば、これまで手動で行っていたメンテナンス作業が不要になり、ビジネスにとって新たな可能性が開かれます。
データコンサルタントの推奨アプローチ:
サーバーレスアプローチの導入検討: サーバーレス型データウェアハウスは、運用コストとリソースの効率化に大きな影響を与えます。クラウドでの柔軟なスケーリングとリソース管理が可能となり、これにより、ビジネスに迅速に対応できるアーキテクチャへと移行できます。
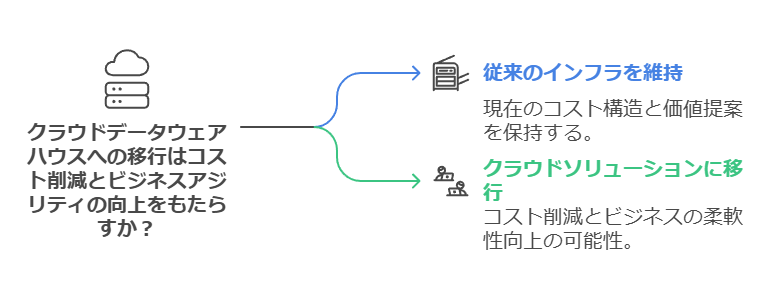
4. インフラ選択の際に考慮すべき要素 新しい分析戦略を効果的に実行するためには、適切なデータウェアハウスインフラを選択することが不可欠です。しかし、従来の非効率的なアーキテクチャをパブリッククラウドへそのまま移行するケースも多く見受けられます。そのような移行を避けるためには、TCO(総所有コスト)の評価が重要です。従来のシステムに多額のコストをかけているにもかかわらず、それに見合ったビジネスのアジリティが得られていないことを把握する必要があります。
データコンサルタントの推奨アプローチ:
TCOの評価と最適化: 従来型インフラストラクチャのTCOを再評価し、コストに見合った価値が得られているかを検討することで、クラウドデータウェアハウスへの移行の必要性を判断します。例えば、BigQueryのようなクラウドソリューションへの移行は、単なるクラウド化にとどまらず、コスト削減とビジネスアジリティの向上をもたらす可能性があります。
適切なインフラストラクチャ選定によるデータ戦略の強化
企業がビジネスニーズに迅速に対応できるデータウェアハウスインフラを選定することは、持続可能なデータ戦略を実現する上で非常に重要です。システムエンジニアリングやメンテナンスに時間を取られている現状を打破し、サーバーレスモデルやTCOを考慮したクラウドソリューションへの移行を検討することで、データのアジリティとコスト効率を最大化することができます。
データコンサルタント視点での改善提案: データウェアハウスのスケーラビリティと最新ニーズへの対応
1. データ基盤の重要性と課題認識 データウェアハウスにおけるデータ量の急増や、顧客が求めるリアルタイムのエクスペリエンスに対応するには、強力かつ拡張可能なデータ基盤が必要不可欠です。多くの企業が抱えるデータ関連の問題には、次のような共通点があります。
従来型データウェアハウスのキャパシティ不足:膨大なデータ流入により、従来のインフラが処理限界に達しているケース。
満たされていない分析ニーズ:社内に点在する分析ニーズが、既存システムで対応できていない。
最新技術の導入遅延:AIや機械学習のような最新ツールへの移行が遅れ、競争力が低下している。
データコンサルタントの推奨アプローチ:
データインフラの再構築: データ量の増加や高度化する分析ニーズに対応できるよう、企業は最新のクラウドデータウェアハウスを導入する必要があります。特に、スケーラビリティが容易なインフラを採用することで、リアルタイム処理の要求や多様なデータ分析タスクに対応する柔軟性が得られます。
2. アジリティの重要性と従来型データウェアハウスの制約 今日のビジネス環境では、膨大なデータストリームやグローバルなビジネス要件に迅速に対応することが求められます。しかし、多くの企業ではデータ分析が依然として従来型のデータウェアハウスに依存しており、これがアジリティを阻害しています。IT部門は、新しい技術要求に適応するための準備ができておらず、従来のシステムが最新のデータ戦略の構築において足かせとなっています。
データコンサルタントの推奨アプローチ:
クラウドネイティブなソリューションへの移行: アジリティを高めるためには、従来のデータウェアハウスから脱却し、クラウドベースのデータウェアハウスを採用する必要があります。これにより、スピーディーなスケーリングが可能となり、ビジネスニーズに迅速に対応できる体制を整えることができます。
3. データ分析とシステムエンジニアリングの分離による効率化 データ分析タスクとシステムエンジニアリングの作業を分離し、自動化することがデータウェアハウスのスケーリングにおいて重要です。この点で、Google BigQueryのようなサーバーレスのクラウドデータウェアハウスは大きな利点を提供します。BigQueryを利用することで、ユーザーが管理者に依存する度合いが低くなり、ITチームのリソースを効率的に活用できます。
データコンサルタントの推奨アプローチ:
自動化とユーザーの独立性向上: BigQueryの自動化機能を活用することで、システムの運用管理の負担が軽減され、データ分析に注力することが可能になります。また、ユーザーは自律的にデータ分析やレポート作成を行えるため、データインフラ管理にかかるリソースを削減できます。
4. クラウドデータウェアハウスの採用に関する考慮事項 クラウドデータウェアハウスを採用する際には、次の要素を考慮する必要があります。第一に、スケーラビリティとパフォーマンスの要件を満たすためのインフラ設計が重要です。Google BigQueryのようなサーバーレスソリューションは、必要に応じてスケールし、パフォーマンスを自動的に最適化することで、従来型ウェアハウスのような運用負荷を軽減します。
データコンサルタントの推奨アプローチ:
クラウドウェアハウスの主要コンポーネント評価: BigQueryのサーバーレスアーキテクチャが、ビジネスに必要な拡張性とコスト効率を提供することを確認します。また、TCO(総所有コスト)を分析し、クラウド移行によるコスト削減効果とビジネスのアジリティ向上を総合的に判断します。
クラウドデータウェアハウスの採用によるビジネス価値の最大化
企業が直面するデータ管理の課題に対処するためには、クラウドデータウェアハウスを活用したスケーラブルなデータ基盤の構築が必要です。従来型インフラに伴う制約を克服し、Google BigQueryのような自動化されたサーバーレスソリューションを採用することで、データ分析に注力できる環境を整え、ビジネス価値を最大化することが可能です。このホワイトペーパーでは、クラウドデータウェアハウス導入にあたっての主要なポイントや、BigQueryがどのように企業の最新ニーズに対応するかを詳しく解説します。
理想的なクラウドデータウェアハウスモダナイゼーションアーキテクチャ
このアーキテクチャの青写真は、エンタープライズクラウドデータ管理のソリューションと原則を基に、クラウドデータウェアハウスを導入し、データ活用を強化するための包括的なフレームワークです。以下の手順に基づき、効率的で拡張性の高いデータウェアハウス基盤を構築します。
データカタログ・品質向上・ガバナンスの適用
クラウドデータウェアハウスのモダナイゼーションの第一歩として、データのカタログ化、品質の向上、セキュリティ強化およびデータ制御を適用します。データカタログは移行対象データの探索、キュレーション、管理、優先順位付けを行い、クラウド環境でのデータガバナンスと保護を可能にします。また、AIとMLの導入により、生産性の向上、インテリジェントな提案、データディスカバリ、非構造化データのオンボーディング自動検出などの機能を拡充します。
大量取り込みとデータ複製の効率化
データの大量取り込みとクラウドオブジェクトストアへの効率的なデータ移行により、スピードとスケーラビリティを確保し、データ量が増加しても安定したパフォーマンスを維持します。
ストリーミングデータの収集とメッセージングシステム
Apache Kafka、AWS Kinesis、Azure Event Hubなどの高スループットなメッセージングシステムを活用してストリーミングデータを効率的に収集・提供し、リアルタイムのアナリティクス環境に貢献します。
APIおよびアプリケーション統合
APIとSaaSアプリケーションが各種システム(例:NetSuiteからSalesforce)とシームレスに接続され、リアルタイムのプロセスオーケストレーションやAPI統合によってデータの同期と管理を容易にします。
クラウドデータ統合と同期
多様なクラウドプラットフォーム間でのデータ統合・同期により、クラウド間でのシームレスなデータ連携を実現し、データの一元管理をサポートします。
価値あるデータへの変換
各種ソースから取り込んだデータをクレンジング・統合し、価値ある情報へと変換することで、ビジネスの意思決定に必要なデータの信頼性と価値を向上させます。
高度なデータキュレーションと下流アプリケーションへの提供
キュレーションされたデータがクラウドデータウェアハウスに保存され、ビジネスレポートやダッシュボードなどの下流アプリケーションに入力できる状態に整備されます。これにより、データ駆動型の意思決定を促進します。
柔軟性を持ったコンピューティングと高度なアナリティクスの拡張
クラウドデータレイクやML(機械学習)機能を含むアーキテクチャを構築し、従来のデータウェアハウスを超えた高度なアナリティクスにも対応できる柔軟性を持たせ、全社的なデータ戦略を支援します。
このアーキテクチャは、迅速で確実なデータ活用の土台を提供し、企業が高度なアナリティクスを活用して競争力を強化するための鍵となります。
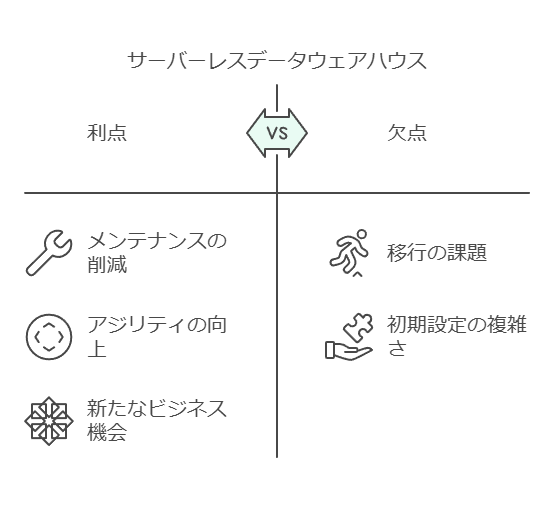
データウェアハウスは賞味期限切れか?
データ量の急増や利用方法の多様化により、従来のデータウェアハウスの限界が見え始めています。しかし、企業におけるデータ活用のあるべき姿は、単にデータウェアハウスからの移行ではなく、必要なデータソリューションを適材適所で組み合わせることにあります。次世代型データウェアハウスは、柔軟性・コスト効率・クエリ管理において大きな進化を遂げ、従来のデータウェアハウスが抱える問題を解決する新たなアプローチを提供します。
次世代データウェアハウスが備える特徴
クエリ管理とコスト効率の向上
近年、Snowflakeなどのクラウド分析プラットフォームは、クエリの効率とコスト管理の最適化に大きく貢献しています。これにより、従来型データウェアハウスが抱えていた非効率なクエリ実行に伴うコスト課題を軽減し、高頻度クエリに対応できる基盤が構築されつつあります。
データウェアハウスとデータレイクの役割分担
データウェアハウスとデータレイクは、異なるデータ要件に応じた特化型ソリューションとして補完し合います。高品質な構造化データで定期的に実行されるバッチ処理にはデータウェアハウスが適しており、柔軟性の高い「仮説検証型」分析にはデータレイクが有用です。
多様なクエリニーズの対応
「What-if」クエリなどの探索的分析には、データレイクやドキュメント管理システムが有効とされています。Pure Storageのマクマラン氏が述べるように、データウェアハウスが「農業型」すなわち定型的なクエリ分析に優れる一方で、データレイクは「狩猟採取型」のような、問いを探索し、仮説を検証するプロセスをサポートする役割を担います。
次世代データプラットフォームの方向性
業界が目指すべきは、リアルタイム処理やストリーミングデータの弾力的な対応力を備え、データウェアハウスとデータレイクの利点を統合した単一プラットフォームの実現です。複数のデータ処理ニーズを一元化し、迅速な意思決定支援を可能にするデータ基盤を構築することで、企業はさらなる競争力を得ることができるでしょう。
脱構築型データウェアハウスの設計: 柔軟性とリアルタイム処理の実現
従来のデータウェアハウスの枠を超え、より柔軟でリアルタイムに対応可能な「脱構築型データウェアハウス」を構築するため、オンプレミスとクラウド、オープンソースと専用ソフトウェアの組み合わせによるハイブリッドモデルが求められています。多くの業界関係者も、この多様化が進む傾向を支持しており、単一技術がデータ管理の全てを担うことは現実的ではなく、さまざまなシステムや技術が共存する環境が増えると見られます。当面の間、データウェアハウスは企業における「ゴールドコピー」としての役割を持ち続けるでしょう。
未来のデータ活用と構築への対応
今後のデータ活用の要件は多様化し、データセットの更新性や処理速度といった技術要件が進化する中で、データウェアハウスやデータレイクといった異なるデータプラットフォームを組み合わせて、さまざまな視点からデータを可視化することが求められています。このような要件の増加により、従来の物理インフラの制限を超えたクラウド環境への移行が重要です。
クラウドデータウェアハウスのモダナイゼーション設計時に検討すべき要素
以下のポイントを考慮することで、クラウドデータウェアハウスのモダナイゼーションの基盤を強化できます。
利害関係者のニーズの把握
利害関係者が絶対に必要としている要件(ニーズ)と望む機能(ウォンツ)を明確にし、プライオリティをつけて設計に反映させましょう。
データの品質管理
移行前に高品質なデータのみを選別するために、データプロファイリングやクレンジングの手順とツールを確立します。これにより、信頼性の高いデータ基盤を構築できます。
データカタログの導入
クラウドデータウェアハウスに適したデータとメタデータを把握するため、データカタログツールの使用を検討します。これにより、データの可視性と統制が強化され、移行対象の正確な判断が可能となります。
運用データストアの移行影響評価
技術的な側面だけでなく、ガバナンスや法令遵守といった非技術的な影響についても検討が必要です。特に規制や契約上のデータ配置要件に留意し、リスク評価を行います。
適切なツールと自動化機能の導入
データ管理やデータ統合ソリューションが一体的に機能することが理想です。特に接続性、使いやすさ、迅速な統合、エンドツーエンドのサポート、拡張性などの観点から有用なツールを選定し、プロセスの効率化と統合性を図りましょう。
このようなアプローチにより、柔軟性やリアルタイム性、そしてコスト効率を備えたデータウェアハウスのモダナイゼーションが実現可能となり、将来的なデータ活用基盤の競争力を向上させることができます。
データウェアハウスとデータレイクが抱える新時代への適応課題
1992年、米国のコンピュータ科学者ビル・インモン氏の著書『Building the Data Warehouse』により、データウェアハウスの概念が広く知られるようになりました。それ以前からも同様の概念は存在していた可能性があるものの、インモン氏の提唱により、企業の意思決定支援に活用されるデータ管理手法として本格的に普及しました。以後、TeradataやIBMといった企業が、データを一元化し、迅速かつ正確な情報分析を目指してデータウェアハウス技術の発展に尽力してきました。
従来型データウェアハウスの限界と新しいニーズ
しかし、データ量の増加やリアルタイム分析の需要が高まる中、従来型のデータウェアハウスには限界があるとする意見も増えています。特に、データ量の急増、処理速度の向上要求、リアルタイム分析ニーズといった課題において、データウェアハウスの既存技術は十分に対応できていないと指摘されています。
クラウドとの競争と従来型データウェアハウスのコスト
データウェアハウスの多くは高額なオンプレミス設備を前提とし、構築やクエリ変更に多くの時間と費用がかかります。クラウドの導入により、従来のデータウェアハウス技術と比べて圧倒的なスケーラビリティとアジリティが実現されました。例えば、クラウドプラットフォームは必要な時に必要なリソースを動的にスケーリングできるため、オンプレミス環境のようにアイドル状態のインフラに無駄なコストをかける必要がなく、クエリごとに柔軟な拡張が可能です。このため、クラウドベースのデータ処理能力は、パフォーマンス面で従来型のデータウェアハウスを上回ります。
多様なデータストリームへの対応力
また、ソーシャルメディア、Eコマース、IoTセンサーといった新しいデータソースが増加する中、企業はこれらのデータからリアルタイムでインサイトを得たいと考えています。しかし、従来型のデータウェアハウスは厳格なデータスキーマやETL(抽出、変換、読み込み)プロセスを備えたシステムであるため、こうしたデータストリームに対する柔軟性やリアルタイム処理の俊敏性が十分とは言えません。
データコンサルタント視点からのアドバイス
クラウドとの適切な組み合わせ
従来型データウェアハウスを引き続き利用する場合、柔軟なクラウド技術を併用することでスケーラビリティとアジリティを補完することができます。オンプレミスとクラウド環境を連携させるハイブリッドモデルも効果的な選択肢となるでしょう。
リアルタイムデータ処理のためのアーキテクチャ再設計
リアルタイムデータやデータストリームを扱う必要がある場合、データレイクや脱構築型データウェアハウスなどの新しいアーキテクチャを検討し、柔軟で効率的なデータ管理を実現することが重要です。
マルチプラットフォームとデータ統合の検討
企業全体のデータを統合的に管理し、単一のデータベースやウェアハウスに依存しないマルチプラットフォーム戦略を導入することで、急速に増加するデータ量に対応できる基盤を整備することが可能になります。
これにより、従来のデータウェアハウスの制約を克服し、次世代のデータ活用基盤を構築するための一歩を踏み出すことができます。
従来型データウェアハウスを超える次世代ツールの「分析対象」
従来のデータウェアハウスやデータレイクの限界を克服するため、新たなデータ管理技術が登場しています。代表的なものに、Databricksの「データレイクハウス」アプローチや、Snowflakeのクラウドベースのマルチクラスタアーキテクチャ、Amazon Redshift SpectrumのようにS3に保存したデータへ直接クエリを実行する機能があります。また、Apache Hadoopを中心としたデータレイク構築は減少しつつあるものの、Apache Sparkのような高性能なオープンソースツールは引き続き人気を保っています。
ビジネスニーズがもたらす技術の進化
今日では、技術革新そのものよりも、ビジネス分析ニーズがデータインフラの進化を促進する傾向が強くなっています。従来のデータウェアハウスに求められる要件はここ数年で大きく変化し、特に顧客インテリジェンスや変化分析、IoT分析といった新しいデータ要求が増えています。センサーデータやIoTデータなどの新しいデータソースへの対応を求められる中、データウェアハウスも進化し、半構造化データや非構造化データの処理を可能にしています。
クラウドの活用によるコスト削減とスケーラビリティの向上
クラウドプラットフォームはデータ分析における弾力性とスケーラビリティを提供し、一般的には20%程度のコスト削減が見込まれ、状況次第では50%から70%の削減も可能です。しかし、ペタバイト級の大規模な分析システムを構築する企業は一部に限られ、Forresterによれば、実際にその規模で運用する企業は全体の3%未満とされています。こうした企業は主に製造業や高度な測定を要する分野に多く、エッジ処理や機械学習を活用してデータフローの効率化や意思決定の高速化を目指しています。
リアルタイム処理の需要とその自動化の課題
加えて、リアルタイムデータ処理の需要も増えています。特に、Eコマースやエンターテインメント、ソーシャルメディアの「クリックストリーム」データは膨大な情報の流れを生み出しますが、その多くは短期的な価値に留まります。リアルタイムのストリーム分析への投資価値は、ビジネスがその情報に即座に反応できるかどうかにかかっており、そのためには高度な自動化が不可欠です。
データコンサルタント視点からの提言
次世代アーキテクチャの採用
ビジネスニーズに合わせて、データレイクハウスやクラウドベースのマルチクラスタアーキテクチャの採用を検討することで、柔軟な分析環境を構築できます。
IoTおよびリアルタイム分析への対応
IoTやリアルタイムストリームデータの増加に対応するためには、機械学習やエッジ処理を組み合わせたアプローチが必要です。これにより、データの即時分析やリアルタイムでの意思決定が可能になります。
クラウドを活用したコスト効率の向上
クラウドの弾力性やスケーラビリティを活かして、オンデマンドで処理能力を利用することで、コスト効率の高いデータインフラを実現します。
このような進化的な対応を通じて、データウェアハウスやデータレイクを超えた、新しいデータマネジメント基盤を構築することが可能になります。
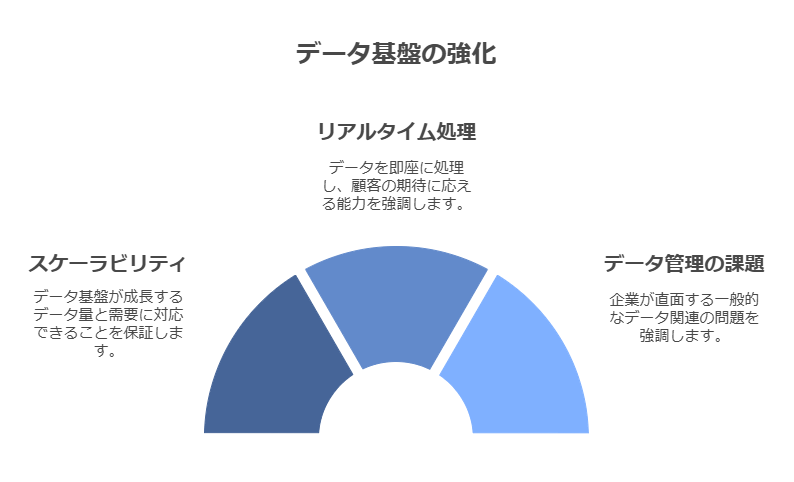
クラウドデータウェアハウスのモダナイゼーションが求められる背景
クラウドデータウェアハウスは、顧客体験の改善、業務プロセスの自動化、データの収益化、生産性向上といったデジタルトランスフォーメーション(DX)の目標達成に欠かせない要素です。企業はクラウドへの予算を増加させる中で、セルフサービスで柔軟性の高いオンデマンドのマネージドインフラストラクチャを提供するクラウドデータウェアハウスの導入を進めています。以下ではその重要性と、業務・IT部門の課題について整理します。
クラウドデータウェアハウスが重要な理由
データの爆発的増加に対応
従来のデータウェアハウスでは、増え続けるデータ量と多様なデータタイプに柔軟に対応することが困難です。クラウド基盤はスケーラビリティに優れ、必要に応じて拡張・縮小が可能であるため、将来的なデータ管理のニーズにも柔軟に応えられます。
拡張にかかるコストと時間の削減
従来のデータウェアハウスを増大するワークロードに対応する形で拡張する場合、コスト・労力・時間がかさむ一方です。クラウドなら、リソースを柔軟に配分できるため、運用コストの最適化が期待できます。
分散データソースへの対応とガバナンス強化
オンプレミスとクラウド双方にまたがるデータソースの管理、そしてセキュリティやガバナンスの要件を満たすことが可能です。特にクラウドデータウェアハウスは、分散データの統合を効果的に行い、ガバナンス機能を充実させることでコンプライアンスを確保します。
業務部門が抱える課題
インサイト獲得の迅速化
データからの洞察を迅速に得るためには、データの所在と内容、影響範囲を把握する必要があります。リアルタイムでのデータアクセスが可能であることが、ビジネスニーズへの即応性を高めます。
ビジネスニーズに対応するデータアクセスの確保
リアルタイムのデータアクセスは、迅速な意思決定を下す上で不可欠です。クラウドデータウェアハウスの導入により、ユーザーは必要なデータに即時アクセスできるため、ビジネス機会の損失を防ぎます。
IT部門が抱える課題
アジャイル開発への対応
変化するビジネス要件に迅速に対応できるよう、1日単位で新たな要件に対応する体制が必要です。これにより、データウェアハウスの進化がビジネス価値をさらに高めるための礎となります。
クラウド移行の戦略的アプローチ
既存データ資産の状況を把握し、段階的なクラウド移行戦略を策定・実行する必要があります。最適な移行手順を確立し、データの連携やガバナンスを含むアプローチの全体像を整備することが求められます。
統合パターンの多様化対応
ビジネス環境の変化に合わせて複数の統合パターンをサポートすることで、異なるシステム間でのデータ連携を円滑に行えるようにします。
SLA・ガバナンス・セキュリティの担保
サービスレベル合意(SLA)やデータガバナンス、セキュリティの基準を維持しながら、業務を円滑に遂行する体制が必要です。クラウドデータウェアハウスにおけるデータの可用性とセキュリティが、ビジネス全体の信頼性向上につながります。
データコンサルタント視点からの推奨アクション
クラウドデータウェアハウスの導入検討と段階的移行
業務の特性やデータ量に応じて、クラウドへの段階的な移行を推進し、適切なデータ管理体制を整備しましょう。
ガバナンスの強化とデータアクセス体制の見直し
分散するデータソースに対し、クラウド環境下で統一的なアクセス制御とガバナンス基盤の確立が重要です。
アジャイル開発体制の構築
業務部門とIT部門が連携し、俊敏に対応できる体制を確立することで、データの即時活用とDXの推進を加速させましょう。
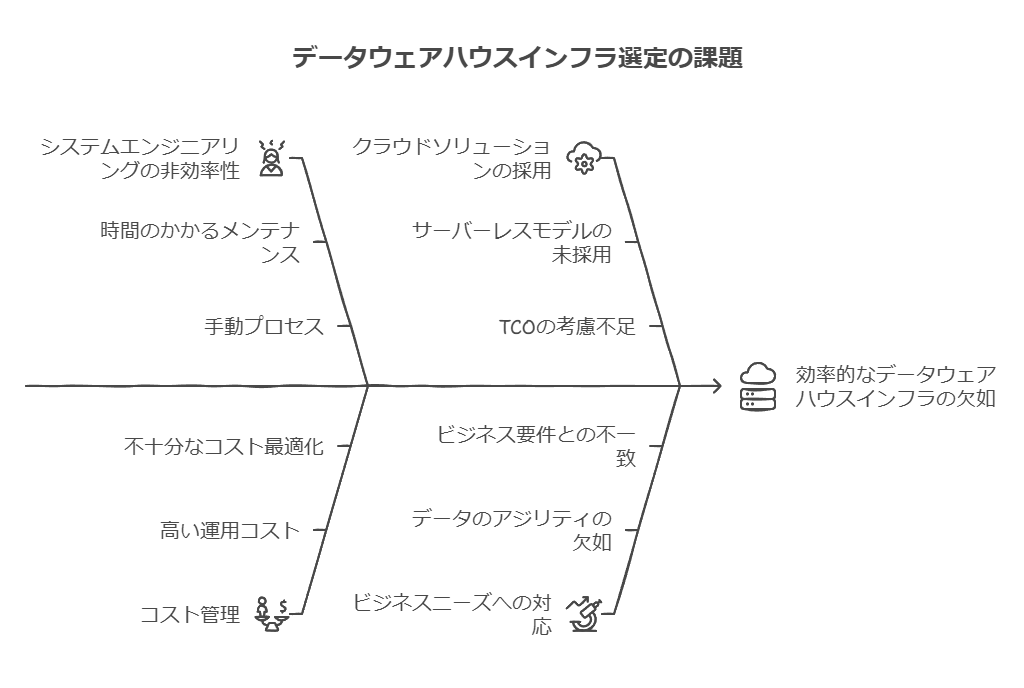
既存のデータインフラストラクチャの課題
1. 従来のデータウェアハウスの役割とその限界
多くの企業は、報告や分析のためにデータウェアハウスを構築し、各種のトランザクション処理システムやデータベースからデータを収集してきました。また、ビッグデータや非構造化データの活用を目的に、Hadoopなどのビッグデータフレームワークも導入してきました。
しかし、これらのインフラストラクチャは複雑化し、コストが高騰する傾向があり、迅速な意思決定や拡張性のある運用に課題を抱える企業が増えています。
2. 従来のデータウェアハウスの具体的な課題
従来型のデータウェアハウジングシステムでは、以下のような課題が顕著です:
(1) 高コスト構造
初期投資に数百万ドル規模のソフトウェアやハードウェア費用が必要。
セットアップや運用に長期間と多大な労力を要する。
(2) 管理と運用の複雑性
データモデルの設計からデータ取り込みまで、手作業での管理が必須。
管理者チームを雇用する必要があり、人的リソースの負担が増大。
(3) スケーリングの難しさ
データ量の増加に伴うシステムのスケーラビリティ確保が困難。
ダークデータ(利用されないデータ)がサイロ化され、分析に活用できない。
(4) クエリ性能とデータ保護の課題
クエリ速度を維持しつつ、データ損失を防ぐ仕組みが求められる。
高度に正規化されたデータが必要で、柔軟性に欠ける。
3. ビジネスインパクト:課題がもたらす影響
これらの課題は、以下のような形で企業のデータ活用を制約します:
データ分析プロジェクトの立ち上げに時間がかかり、意思決定が遅れる。
ダークデータや非構造化データの活用不足により、データの価値を十分に引き出せない。
コストやリソースが非効率的に消費され、競争優位性の低下を招く。
4. 次世代のデータウェアハウスへの移行:解決策の方向性
従来型データウェアハウスの課題を解消するためには、以下のアプローチが有効です:
(1) クラウドネイティブなデータウェアハウスの活用
オンデマンドのスケーラビリティにより、データ量の増加に柔軟に対応。
高速なデプロイメントと運用の簡易化を実現。
(2) サイロ化データの統合と活用
データレイクやモダンデータプラットフォームを活用し、異なる形式やソースのデータを統合。
ダークデータを分析可能な形式に変換し、データ価値を最大化。
(3) 自動化とインテリジェントツールの導入
データ取り込み、モデル設計、モニタリングのプロセスを自動化し、人的負担を削減。
機械学習やAIを活用して、高度なリアルタイム分析を可能にする。
(4) コスト効率の改善
初期投資が少ないSaaS型のデータウェアハウスを検討し、従量課金モデルで柔軟なコスト管理を実現。
5. 結論:最適なデータ基盤で未来をリード
データウェアハウスの課題に直面している企業には、最新の技術やアプローチを取り入れた次世代データ基盤への移行が不可欠です。モダンなデータプラットフォームの導入により、以下のメリットが期待されます:
データ分析の迅速化と高度化
スケーラブルでコスト効率の高い運用
サイロ化を解消し、データ価値を最大化
私たちは、貴社の現状を深く理解し、最適なデータ戦略を策定します。これにより、迅速な意思決定を支える強力な基盤を構築し、ビジネス成長をデータで加速させるお手伝いをします。