
目次
データウェアハウスとデータレイクへの統合的なアクセス:次世代データ分析基盤の要点
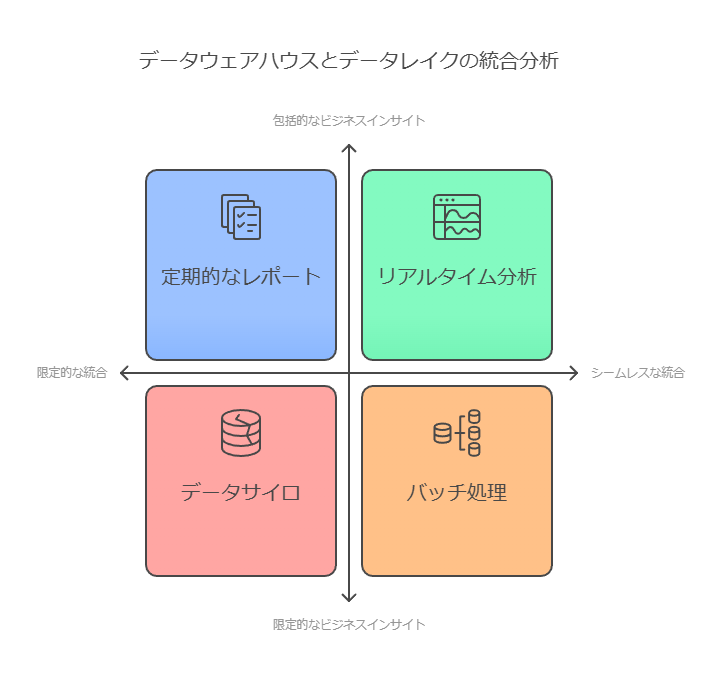
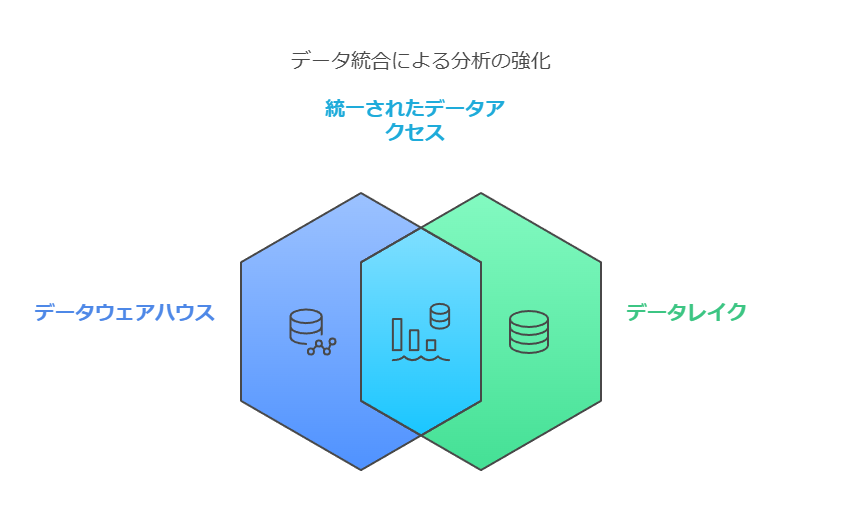
現代のデータ活用では、データウェアハウスとデータレイクをシームレスに統合し、双方の利点を最大限に引き出すことが求められています。これにより、構造化データと非構造化データの一貫性ある分析が可能になり、ビジネスインサイトを迅速に得る環境が整います。
1. データウェアハウスとデータレイクの役割と統合の重要性
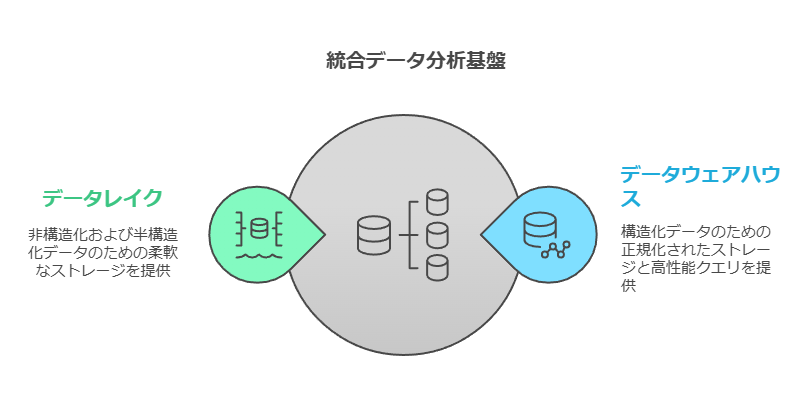
データウェアハウスは、構造化データを正規化し、高性能なクエリエンジンを活用する分析基盤を提供。複雑な分析クエリに適しています。
一方、データレイクは非構造化データや半構造化データを含む柔軟なストレージを提供。異種データを蓄積し、幅広いユースケースに対応可能です。
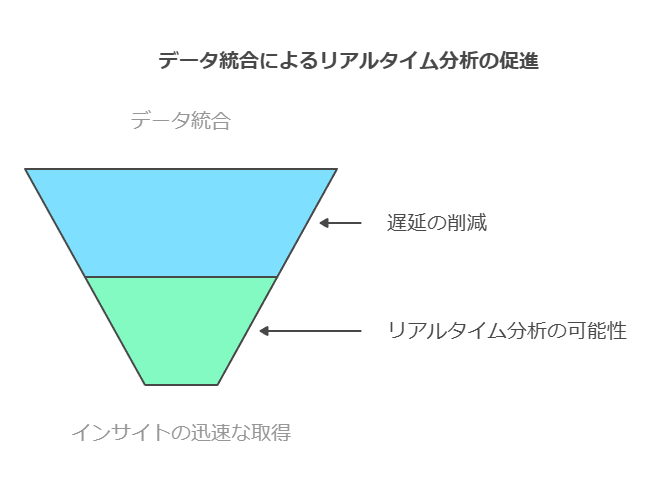
これらを統合し、データの変換や移動による遅延を最小化することで、リアルタイムの分析やインサイトの取得が可能になります。
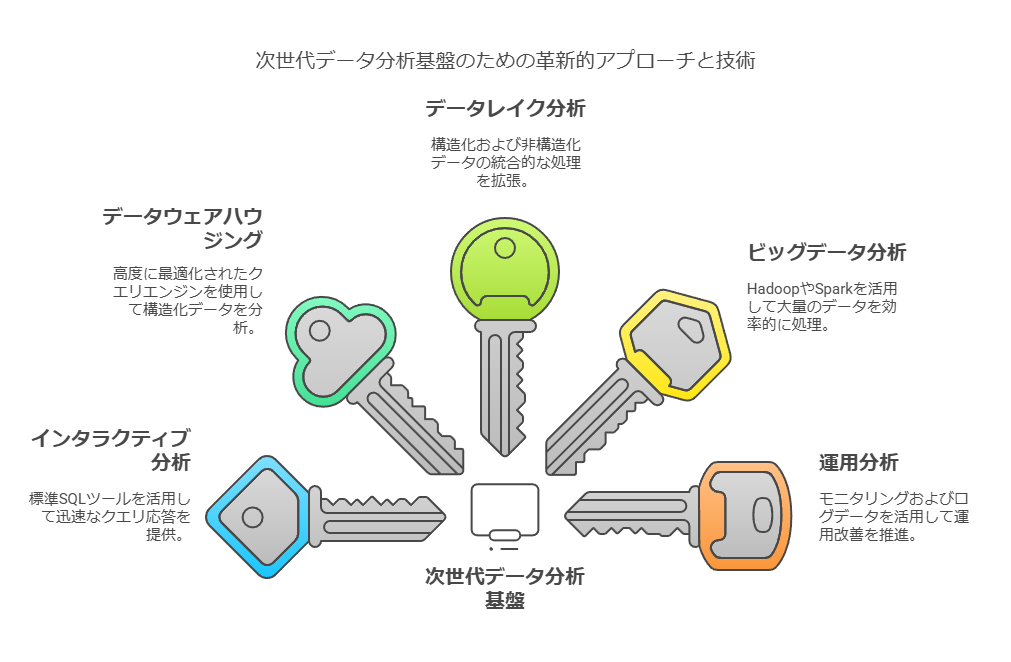
2. 統合的なアクセスを実現するためのポイント
(1) ユースケース別のデータ処理アプローチ
インタラクティブ分析
標準SQLツールを活用し、迅速なクエリ応答を提供。エンドユーザーは、クエリの変更や再実行を瞬時に行える環境を求めています。
データウェアハウジング
高度に最適化されたクエリエンジンを使用し、大量の構造化データ(ペタバイト規模)に対する複雑な分析を実現。
データレイク分析
データウェアハウスのクエリをデータレイクに拡張し、構造化データと非構造化データを統合的に処理。これにより、エクサバイト規模へのスケールアップが可能。
ビッグデータ分析
HadoopやSparkフレームワークを活用し、大量のデータを効率的に処理。データレイクとの連携でさらなる分析の多様性を実現。
運用分析
アプリケーションのモニタリングやログデータ、クリックストリームデータを活用して、運用改善を推進。
(2) シームレスなデータアクセスの重要性
データの移動や変換に伴う遅延を最小化し、以下を実現することが求められます:
データウェアハウスとデータレイク双方へのクエリ拡張により、タイムリーな分析を可能にする。
ビジネスユーザーからデータサイエンティストまで、組織全体が同じデータソースを信頼して活用できる環境を構築する。
3. 次世代データ分析基盤の構築がもたらす価値
統合的なデータ基盤を導入することで、以下の利点を享受できます:
リアルタイムの意思決定を加速:データ変換や移動を最小化し、即時に活用可能なデータ環境を提供。
コスト効率の向上:データ処理や管理の効率化により、運用負荷を削減。
分析の精度と幅を拡大:構造化データと非構造化データを組み合わせることで、より深いインサイトを提供。
スケーラビリティと柔軟性:ペタバイトからエクサバイト規模のデータまで対応可能な環境を構築。
4. データコンサルタントからの提言
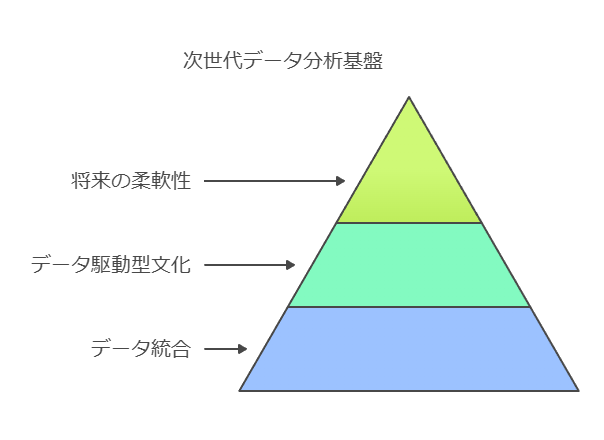
企業の競争優位性を高めるためには、次世代型のデータ分析基盤の採用が不可欠です。これにより、以下を実現します:
すべてのデータを統合的に管理し、サイロ化を解消。
組織全体でデータ駆動型の文化を育成し、意思決定の迅速化を推進。
将来の拡張性や進化するユースケースに対応する柔軟性を確保。
私たちは、貴社の現状を分析し、最適なデータ統合戦略を提案いたします。データウェアハウスとデータレイクの統合を通じて、さらなるビジネス成長を実現するお手伝いをさせていただきます。
データウェアハウスとデータマート:データ活用戦略の基盤
1. データウェアハウス:統合データ分析の中核
データウェアハウスは、複数のデータソース(データレイクを含む)から情報を収集・統合する中央リポジトリです。主な特徴は以下の通りです:
データ変換と整備:データは事前定義されたデータモデルに合わせて変換、修復、重複排除が行われ、一貫性と品質が確保されます。
高速分析:BIツールを利用することで、大量のデータを迅速に分析し、隠れたパターンや傾向を発見可能。
ビジネス全体での活用:組織内のユーザーがアドホックSQLクエリ、定期レポート、ダッシュボードを通じてデータにアクセスし、意思決定に活用します。
データサイエンティストの役割:クエリを実行して傾向を特定し、オフライン分析を行うことで、より深い洞察を得る支援を行います。
メリット
データウェアハウスは、データ間の関係性や傾向の可視化を通じて、組織の意思決定プロセスを強力に支援します。
2. データマート:特定領域に特化した効率的な分析基盤
データマートは、データウェアハウスの一部を抜粋し、特定の業務領域または対象分野に最適化されたシンプルなデータ分析基盤です。
用途ごとの最適化:部門単位(例:販売、マーケティング)や地域別にセグメント化されたデータセットを提供。
構築の容易さ:データマートは設計・構築が簡単で、迅速な導入が可能。大規模なデータウェアハウスや運用ストアから構築されます。
柔軟な活用:特定の業務課題に焦点を絞った分析を効率的に実行可能。
留意点
データマートは特定領域に特化しているため、複数のデータマート間でのクエリ実行が複雑化する場合があります。この場合、データの統合性と可視性を維持する戦略が重要です。
3. データ分析:データの真価を引き出すための最新手法
現代の分析パイプラインは、多様なツールと技術を活用し、データの潜在的価値を最大限に引き出します。
(1) 分析ツールの役割
1つのツールですべての分析ニーズをカバーすることは困難です。したがって、以下が求められます:
共通のデータソース:データレイクのような統合基盤から、すべての分析ツールがデータを直接取得できる環境を構築。
多様な分析機能:ツールごとに異なる機能を活用して、データ収集、変換、可視化、モデル構築を最適化。
(2) データ分析のアプローチ
高速なクエリ応答:データウェアハウスの強みを活用し、タイムリーな意思決定をサポート。
専門的なデータ活用:データサイエンティストは、クエリ実行とオフライン分析を通じて、傾向やパターンを発見。
カスタム分析:データマートの柔軟性を活かし、特定の課題や業務領域に対応する分析を実行。
4. データコンサルタントからの提言
効果的なデータ分析環境を構築するためには、データウェアハウスとデータマートを組み合わせ、データレイクを共通基盤として統合することが鍵となります。これにより以下の成果を実現します:
データの一元化と品質向上:すべてのユーザーが信頼できるデータを活用可能。
迅速な意思決定:BIツールやダッシュボードを通じてタイムリーなインサイトを提供。
コスト効率と柔軟性の向上:業務ごとに特化したデータ分析が可能になり、運用負荷も低減。
貴社のデータ戦略を再構築し、次世代のデータ分析基盤を導入することで、競争優位性を高めるサポートをいたします。
データウェアハウスにおける課題と現代的なデータ管理への移行
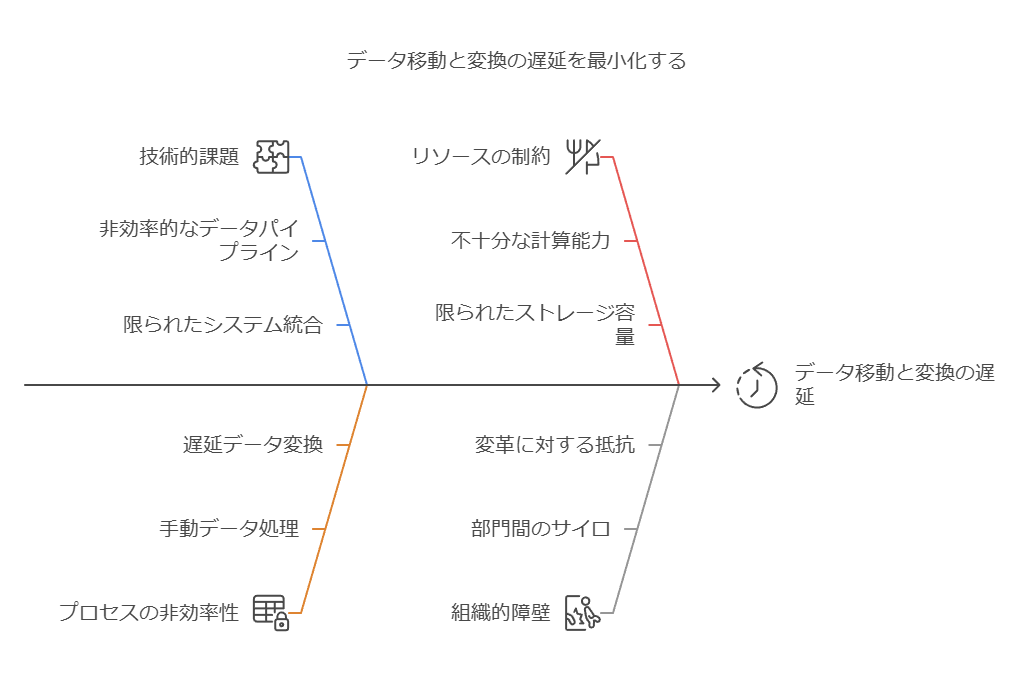
1. データボリュームとクエリパフォーマンスの問題
企業が生成するデータ量が指数関数的に増加する中、データウェアハウスのパフォーマンス低下が顕著な課題となっています。特に以下の状況では、運用上の選択肢が限定されがちです:
クエリ処理速度の低下を受け入れる。
高コストな更新プロセスへのリソース投資を余儀なくされる。
この結果、多くのITチームは既存のサービスレベルアグリーメント(SLA)を維持するために、データの追加やクエリ数の増加を制限せざるを得ない状況に陥っています。一部の企業はこれを回避するためにデータマートを活用しますが、これには以下のデメリットが伴います:
複雑なインフラストラクチャ:データのコピーやサブセットの管理が必要。
ベンダーロックイン:特定のツールやサービスに依存するリスクが増大。
2. 新しいデータタイプへの対応不足
従来のデータウェアハウスは、半構造化データや非構造化データを効率的に処理するよう設計されていません。これには以下のようなデータソースが含まれます:
クリックストリームデータ(ユーザーのウェブ行動ログ)。
IoTセンサーやデバイスからのデータ。
ソーシャルメディアから収集されるリアルタイムデータ。
これらのデータを処理するには、従来の構造化データモデルでは対応が困難です。そのため、多くの企業は以下のような新しい技術を検討しています:
Hadoopフレームワーク:大規模な分散処理が可能。
クラウド型データレイク:柔軟で拡張性の高いデータ保存とアクセスを提供。
多用途の分析エンジン:データの特性や利用目的に応じた選択肢。
これにより、データ管理戦略がより複雑化し、以下のような課題が浮上します:
データ保存場所とアクセス権限の適切な管理。
各データタイプに最適な分析ツールの選定。
3. バッチ処理の遅延とリアルタイム分析の必要性
従来の**バッチ処理型ETL(Extract, Transform, Load)**のアプローチは、以下の理由で時代遅れになりつつあります:
グローバル企業のニーズに非対応:夜間のバッチ処理は、24時間体制のデータ活用を求めるグローバル企業に適していません。
即時性の欠如:今日のビジネスでは、「明日」ではなく「今」のデータが求められます。
このような遅延は、即時の意思決定やリアルタイムなインサイトを必要とする場面で競争力を損なう要因となります。
モダンデータアーキテクチャへの移行が必要
1. クラウドネイティブなソリューションの活用
クラウドベースのデータプラットフォームは、データウェアハウスの制約を超える柔軟性と拡張性を提供します。たとえば:
スケーラブルなリソース:需要に応じた自動拡張でコスト最適化を実現。
サーバーレスアーキテクチャ:管理負荷を軽減し、本質的なデータ活用に集中可能。
2. リアルタイム処理技術の導入
リアルタイム分析を可能にする技術の導入が求められます。これには以下が含まれます:
ストリーム処理プラットフォーム(例:Apache Kafka、AWS Kinesis)。
インメモリ型分析エンジン:即時性が求められるクエリ処理をサポート。
3. 統合的データ管理戦略
企業は、データウェアハウス、データレイク、データマートの特性を統合的に活用するハイブリッドデータ管理戦略を構築する必要があります。これにより:
構造化データと非構造化データを一元管理。
適切な分析ツールを自動的に選定するエコシステムを構築。
次のステップ:データ戦略の再構築
現代の企業が競争力を維持するためには、次の取り組みが必要です:
データ基盤のモダナイズ:クラウド型プラットフォームやリアルタイム処理技術の採用。
組織内データ文化の醸成:IT部門とビジネス部門が協働し、データ活用を推進。
セキュリティとガバナンスの強化:データ分散環境におけるアクセス管理の徹底。
この変革により、企業はデータから即時に価値を引き出し、迅速かつ正確な意思決定を可能にする基盤を構築できます。
現代的なデータウェアハウス運用における課題と推奨ソリューション
1. 最新分析技術のサポート不足
従来型データウェアハウスは以下の点で限界を抱えています:
高度な機械学習(ML)や予測分析のサポートが不十分。
リアルタイム分析や複雑なユースケースへの対応力不足。
これにより、機械学習モデルを活用した意思決定やリアルタイムな市場対応が求められる企業は、データ活用の可能性を制限されます。特に以下のユースケースにおいて非効率が生じます:
個別最適化が必要な予測モデル(需要予測、リスク分析など)。
ストリーミングデータを活用する即時分析。
推奨ソリューション
統合型データプラットフォーム:クラウド型データウェアハウスを採用し、リアルタイム処理やAI/ML対応を実現する環境を構築。
データウェアハウス+データレイクのハイブリッドアプローチ:データウェアハウスを規範データの管理に特化させつつ、柔軟性のあるデータレイクを活用する。
2. データセキュリティと規制遵守の課題
医療や金融業界では、ISO、HIPAA、FedRAMP、GDPRといった厳格な規制への対応が必須です。従来型データウェアハウスでは以下のような問題が発生しています:
データ保護の負担増:全データを暗号化するためのリソースとコストが増加。
規制対応の迅速性不足:突然の監査要求や記録の削除・更新対応が困難。
機密データ分析の制限:セキュリティ強化により分析作業が阻害されるケース。
推奨ソリューション
データセキュリティを内蔵したクラウド型プラットフォーム:GDPRやその他規制に対応可能な自動化されたセキュリティ設定を提供するクラウド基盤を選択。
アクセス制御の強化:動的アクセス制御やデータマスキング技術を導入し、セキュリティを維持しつつ分析可能性を高める。
ゼロトラストセキュリティモデルの適用:特に機密性の高いデータに対しては、ユーザーとアプリケーションの認証を強化する。
3. ビッグデータシステムの複雑性とリソース不足
大量かつ多様なデータが求められる環境では、以下の課題が顕著です:
複雑なアルゴリズムの要求:データ分析には高度なスキルが必要であり、人材不足が障壁となる。
異なるデータシステム間の統合の困難さ:データウェアハウスとビッグデータシステムにまたがる分析は時間とコストを要する。
推奨ソリューション
分散型処理フレームワークの採用:Apache SparkやSnowflakeなど、効率的にビッグデータを処理できるプラットフォームを活用。
統一されたデータビューの提供:データ仮想化技術を使用し、複数のデータソースにまたがる一貫したビューを提供する。
ノーコード/ローコードツールの導入:非専門家でも分析可能な環境を整備し、データ活用を民主化する。
次のステップ:モダンデータアーキテクチャの実現
企業は以下の取り組みにより、データウェアハウスの課題を克服し、持続可能なデータ活用を推進できます:
クラウドファースト戦略
従来のオンプレミス環境をクラウドへ移行し、スケーラブルでコスト効率の高いデータ管理を実現。
AI/ML対応基盤の構築
高度な分析と予測を可能にするプラットフォームを採用し、競争優位性を強化。
セキュリティとコンプライアンスの標準化
グローバル規模での規制対応を効率化するセキュリティ自動化ツールの導入。
これらの施策により、企業は複雑化するデータ環境に適応し、ビジネス価値を最大化できます。
Snowflakeを核とした最新データアーキテクチャ:戦略的データ活用と効率化の実現
データレイクとしてのSnowflake:多様なデータソースの一元管理と柔軟な活用
Snowflakeをデータレイクとして運用する際、エンタープライズデータウェアハウス(EDW)で最終的に必要とされる構造化データ以外にも、はるかに広範なデータセットがランディングゾーンに集約される傾向にあります。これには、Parquet、JSON、Avro、ORCといった多様な半構造化ファイルが含まれ、これらはSnowflakeのファイル大量取り込み機能(例:COPY INTOコマンド)を駆使して効率的にアップロード可能です。Snowflakeのアーキテクチャは、これらのファイルをVARIANT型の列を持つテーブルにロードすることを推奨しており、スキーマオンリードのアプローチにより、ロード時点での厳密なスキーマ定義を不要とし、データ取り込みの俊敏性を大幅に向上させます。
この半構造化データから価値ある情報を抽出するためには、ファイル大量取り込み後のETL/ELTプロセスにおいて、SnowflakeのSQL拡張機能(JSONやXML関数の活用など)やマッピング機能を組み合わせたデータ変換戦略が不可欠です。これにより、生の半構造化データから分析に必要な属性を抽出し、構造化された形式で下流の分析レイヤーに提供することが可能となります。
移行戦略における継続的ロード:データ整合性とビジネス継続性の確保
Snowflakeへの初期データ移行が完了した後、新旧両方のデータウェアハウスを一定期間並行稼働させ、データの整合性を担保するデュアルローディング期間は、移行プロジェクトの成功に不可欠なフェーズです。このアプローチにより、移行後のシステムが期待通りに機能すること、そしてSnowflake上のデータが旧環境と完全に一致していることを徹底的に検証できます。万が一、移行プロセスで予期せぬ問題が発生した場合でも、ユーザーを一時的に旧データウェアハウスへシームレスにリダイレクトできるリスクヘッジ戦略となります。
この並行稼働期間中、旧データウェアハウスからSnowflakeへ新規データや変更データを継続的にロードするパイプラインの構築が求められます。この目的に適したツールとしては、一度の設定で多数のテーブルのスキーマとデータを効率的にコピーできる大量処理ツールや、データフローを定義し、ソースオブジェクトごとに移行を実行できるデータ統合ツールが挙げられます。
これらの移行フローは、多くの場合、一時的または短期間の運用となるため、ソーススキーマの変更への自動追従は必ずしも必須要件とはなりません。スキーマ変更が発生した際には、ツールによる自動反映に頼るのではなく、データガバナンスの観点から慎重な影響分析を行い、Snowflakeデータウェアハウスへの変更を選択的に適用するアプローチが推奨されます。
一方で、これらのシナリオでは膨大なデータ量を扱うため、データ移行ツールには堅牢な障害回復機能が極めて重要な要件となります。特に、障害発生箇所からのタスク再実行(リジューム)機能は、移行作業の効率性と信頼性を大幅に向上させます。
継続的なデータレプリケーション:リアルタイム分析基盤の構築
データウェアハウス移行とは異なり、ソースシステム(ERP、CRM、ソーシャルメディアフィードなど)からSnowflakeへデータを継続的に複製するシナリオでは、リアルタイムまたはニアリアルタイムでのデータ同期が求められます。このユースケースでは、データはあらかじめ定義された頻度、あるいはストリーミングに近い形でSnowflakeと同期され、ソーススキーマの変更を自動的に検出し、ターゲットスキーマに反映する機能(スキーマエボリューション)が重要となります。
この種のデータレプリケーションは、期間が限定された移行シナリオとは対照的に、恒久的なデータパイプラインとして設計・運用される必要があります。
Informatica社のCloud Mass Ingestionのようなソリューションは、初期ロードと増分ロード(CDC:Change Data Capture)を効率的に実行し、大規模なデータ同期を実現します。さらに、ソーススキーマの変更をターゲット構造に自動的に伝播させる機能もサポートしており、運用負荷を軽減しつつ、常に最新のデータに基づいた分析環境を提供します。これは、ビジネスの俊敏性を高め、データドリブンな意思決定を加速するための基盤となります。
Snowflakeにおけるデータ処理最適化戦略:列指向アーキテクチャの理解とETL/ELT設計
Snowflakeの列指向アーキテクチャとクエリパフォーマンスへの影響
Snowflakeは列指向(カラムナ)データベースであり、このアーキテクチャは従来のリレーショナルデータベース(例:Oracle)とはデータ格納構造が根本的に異なります。この特性は、特にCRUD(作成、読み取り、更新、削除)処理のパフォーマンスに顕著な影響を与え、操作対象となる列数に応じて性能が大きく変動します。具体的には、読み取り処理において、クエリが必要とする列のみにアクセスすることでI/Oを最小限に抑え、極めて高いパフォーマンスを発揮します。
マッピング設計においてSnowflakeをデータソースとして定義する際、InformaticaのようなETLツールではデフォルトのソースタイプとして「オブジェクト」(Snowflakeのテーブルやビューを指す)が指定されます。この設定では、ソースオブジェクトからテーブルやビューを直接参照・選択できます。重要なのは、ツールがデフォルトでソースの全項目を下流の変換処理にリンクしようとする場合でも、実際のデータ読み込みはマッピングロジックで使用される項目、またはターゲットに連携される項目のみに限定されるという挙動を理解することです。しかしながら、カスタムクエリを作成する際には、特に列指向データベースの特性を最大限に活用するため、SELECT句で必要最小限の列のみを指定する「射影(Projection)」を徹底することがパフォーマンス最適化の鍵となります。
例えば、300列を有する広範なテーブルからデータ処理を行う場合でも、実際に変換や分析に必要となるのが20列程度であれば、データアクセスをその20列に限定することで、不要なデータスキャンを回避し、処理効率を劇的に向上させることが可能です。これは、Snowflakeのストレージとコンピューティングのアーキテクチャを効率的に利用する上で基本的ながら非常に重要なプラクティスです。
Snowflakeデータウェアハウジングユースケース2:ランディングデータの戦略的処理とETL/ELTパターン
Snowflakeのランディングゾーンに生データがロードされた後、これを価値ある情報資産へと転換するためのデータ処理戦略は、ビジネス要件とデータ特性に応じて多岐にわたります。主要な処理経路としては、以下のパターンが想定されます。
構造化データストアへの変換・ロード: ターゲットとなるデータモデル(ディメンショナルモデルを採用したEDW、Data Vault、オペレーショナルデータストア(ODS)など)のスキーマに合わせてデータを変換し、整備された形で格納する。
外部アプリケーション連携のためのデータ抽出・同期: 分析や業務利用のため、Snowflake上のデータを抽出し、外部のアプリケーションやシステムと同期する。
高度分析・機械学習(ML)プロジェクト向けのデータ準備: エンタープライズ規模のデータサイエンスアルゴリズム適用やデータ品質向上処理(クレンジング、標準化、エンリッチメント)を施し、機械学習モデルのトレーニングや推論に最適なデータセットを準備する。
これらのデータ処理を実行する上で、どのコンピューティングリソースやエンジン(Informaticaネイティブエンジン、Snowflakeのコンピュートウェアハウスなど)を選択するかは、データ量、処理ロジックの複雑性、Snowflake内外での処理コスト、さらにはレイテンシやスケーラビリティといったプロジェクト固有の要件を総合的に勘案して決定する必要があります。
このデータフロー設計(「マッピング」)における主要ツールとして、InformaticaのCloud Data Integration Mapping Designerの活用を推奨します。このプラットフォームは、GUIベースで直感的なデータフロー設計を可能にするとともに、実行時には柔軟なエンジン選択肢を提供します。
InformaticaネイティブエンジンによるETL処理: これは標準的なアプローチであり、ソースデータを読み込み、行単位または集約単位で変換処理を適用し、ターゲットに書き込みます。一般的なETLシナリオにおいて有効な選択肢です。
Snowflakeへのプッシュダウン最適化(ELT処理): ランディングゾーンへのデータロード(Extract & Load)が完了した後、変換処理(Transform)をSnowflake内部で実行するELTパターンです。Informaticaのマッピングで設計したデータフローロジックを、実行時に高度なプッシュダウン最適化(APDO: Advanced Pushdown Optimization)を選択することで、SnowflakeのSQLコマンドに変換します。マッピングロジック全体がプッシュダウン可能な場合、InformaticaがSnowflakeの指定されたウェアハウスを使用して、すべての処理をSnowflake内で完結させることができます。これにより、データ移動のオーバーヘッドを削減し、Snowflakeのスケーラブルなコンピュート能力を最大限に活用することで、大規模データ処理のパフォーマンスとコスト効率を大幅に向上させることが期待できます。
SnowflakeデータクラウドとInformaticaによる次世代データ戦略:インテリジェンス駆動型ビジネスへの変革
Snowflakeのデータクラウドは、データ活用における拡張性、同時実行性、パフォーマンスの新たな標準を確立し、数千の企業にデータドリブンな意思決定基盤を提供しています。この革新的なプラットフォーム上で、組織はサイロ化されたデータを統合し、単一の信頼できる情報源(Single Source of Truth)を構築できます。さらに、組織内外でのデータ共有やデータサービスの活用を促進し、広範なデータエコシステムを形成します。このデータクラウドのポテンシャルを最大限に引き出し、接続性、アクセス性、可用性を担保しつつ、増大する貴重かつ膨大なデータから真の価値を創出するためには、Informaticaのようなエンタープライズクラスのデータ管理プラットフォームとの戦略的連携が不可欠です。
I. 戦略的データ基盤の設計と構築:SnowflakeとInformaticaの連携
データディスカバリとカタログ化戦略:
Informatica Enterprise Data Catalog: Snowflake環境を含む企業全体のデータ資産を自動的にスキャンし、メタデータを収集・分析。データリネージ、意味的関連性、品質スコアを可視化し、データスチュワードシップとガバナンスを強化。データ利用者がセルフサービスで必要なデータを迅速に発見・理解できる基盤を構築します。
効率的なデータインジェスチョン戦略:
Informatica Cloud Mass Ingestion:
ファイル大量取り込み: オンプレミスやクラウド上の多様なファイルソース(CSV, Parquet, JSON, Avro, ORC等)からSnowflakeのランディングゾーンへ、効率的かつスケーラブルにデータを一括ロード。初期ロードおよび増分ロードの自動化を実現します。
ストリーミングデータ大量取り込み: IoTセンサーデータ、ログファイル、クリックストリームなど、リアルタイムに発生するストリーミングデータをキャプチャし、Snowflakeへ低遅延で継続的に取り込み、リアルタイム分析基盤を構築します。
高度なデータ統合と変換 (ETL/ELT):
Informatica Cloud Data Integration (CDI & CDI Elastic): GUIベースの強力なマッピングツールにより、複雑なデータ変換ロジックを設計・実装。Snowflakeのコンピューティングリソースを最大限に活用するプッシュダウン最適化(APDO)により、ELT処理のパフォーマンスを最大化。また、CDI Elasticによるサーバーレス処理で、処理量に応じた柔軟なリソーススケーリングを実現します。
II. データガバナンスと品質管理体制の確立
データガバナンスとデータ品質: Informaticaのソリューションを活用し、データ品質ルール定義、プロファイリング、クレンジング、モニタリングのプロセスを確立。Snowflake上のデータの正確性、完全性、一貫性を維持し、信頼性の高いデータに基づいた意思決定を支援します。データガバナンスポリシーの適用とコンプライアンス遵守を徹底します。
III. Snowflakeデータ活用ユースケースと最適化戦略
データレイク及びデータウェアハウスの段階的構築:
ランディング層/ステージング領域: 多様なソースからの生データをそのまま、あるいは軽微な処理でSnowflakeに集約する初期格納領域。
運用データストア (ODS): 特定業務領域の最新データを保持し、リアルタイム性の高いレポーティングや оперативな分析を支援。
エンタープライズデータウェアハウス (EDW): 全社的な意思決定を支援するため、主題領域ごとに整理・統合・履歴管理された高品質なデータマート群。ディメンショナルモデルやデータボルトなどのモデリング手法を適用。
ユースケース1: Snowflakeへのデータ集約と継続的レプリケーション戦略
既存データウェアハウスのSnowflakeへの移行: レガシーシステムからのデータ移行計画策定と実行。スキーマ変換、データマッピング、検証プロセスを含む包括的な移行アプローチ。
継続的なロード (デュアルローディング): 移行期間中、新旧システムを並行稼働させ、データの整合性を担保。段階的なユーザー移行を支援。
データベースとデータウェアハウスデータのSnowflakeへの継続的複製 (CDC): オンプレミスDBや業務アプリケーション(ERP, CRM等)のトランザクションデータを、変更差分のみリアルタイムまたはニアリアルタイムでSnowflakeに複製し、常に最新のデータ分析環境を維持。
ユースケース2: Snowflakeにおけるデータ処理と変換の高度化
ランディングされた生データを、前述のInformatica Cloud Data Integration等を活用し、分析可能な形式へ変換・加工。ビジネスルール適用、データエンリッチメント、集計処理などを実行。
ユースケース3: Snowflakeからの効率的なデータ読み出しと活用
パーティション戦略の最適化: Snowflakeのマイクロパーティションとクラスタリングキーを適切に設計・活用し、クエリパフォーマンスを向上。特に大規模テーブルに対するスキャン範囲を限定。
パフォーマンスチューニングベストプラクティス:
高度なプッシュダウン最適化 (APDO) の徹底活用: Informaticaのマッピングロジックを可能な限りSnowflakeエンジン上で実行させ、データ移動の最小化と処理の高速化を実現。
Informaticaエンジン/セキュアエージェントの配置戦略: ネットワークレイテンシとデータ転送コストを考慮し、セキュアエージェントの最適な配置場所(クラウド、オンプレミス)を選定。
セキュアエージェントプロパティのチューニング: メモリ割り当て、同時実行数など、ワークロード特性に合わせた詳細なパラメータ調整。
ソース/ターゲット属性の最適化: データ型、精度、長さなどを適切に設定し、不要なデータ変換やリソース消費を抑制。
ファイル処理の最適化: CSVファイルサイズ、ローカルステージングファイル数、バッチレコードサイズなどを調整し、ファイルベースのロード/アンロード処理効率を最大化。
大量取り込みタスクの効率的利用: Informaticaの大量取り込み機能とSnowflakeのネイティブ機能を組み合わせた最適なデータロード戦略。
Snowflake特化チューニング: クエリヒストリー分析、ウェアハウスサイジング、クエリリライティングなど、Snowflake固有のパフォーマンス最適化手法の適用。
IV. セキュリティとデータクラウドの可能性
堅牢なセキュリティ体制: InformaticaとSnowflakeが提供する多層的なセキュリティ機能を組み合わせ、データ暗号化、アクセス制御、監査証跡管理を徹底し、機密性とコンプライアンスを確保。
データクラウドの価値最大化: Snowflakeのデータクラウドが実現する、データ共有とコラボレーションのエコシステムは、新たなビジネスインサイトの発見やデータドリブンなイノベーションを加速します。Informaticaとの連携は、このエコシステム内で信頼性の高いデータを流通させ、その価値をさらに高める触媒となります。
この統合的アプローチにより、組織はデータ管理の複雑性を低減し、データから迅速かつ的確に洞察を引き出し、競争優位性を確立するための強固なデータ基盤を構築することが可能となります。
クラウドネイティブ戦略で実現するアナリティクス変革:データ価値最大化への道筋
データドリブンな意思決定が事業成長の鍵を握る現代において、アナリティクス基盤のモダナイゼーションは喫緊の経営課題です。特にクラウド環境を最大限に活用したアナリティクスは、俊敏性、拡張性、そしてコスト効率の観点から、競争優位性を確立するための不可欠な要素となっています。本稿では、データコンサルタントおよびデータアナリストの視点から、クラウドネイティブなアプローチによるアナリティクス変革の核心と、その戦略的価値について詳説します。
クラウドアナリティクス・モダナイゼーションの核心:3つの戦略的柱
アナリティクス基盤をクラウドネイティブ環境へ移行し、その真価を発揮させるためには、業界をリードするベストオブブリードのデータマネジメント機能の導入が不可欠です。特に、人工知能(AI)および機械学習(ML)を組み込んだ以下の3つの機能群は、データ活用の高度化と効率化を両立させるための戦略的柱となります。
クラウドネイティブ・データ統合:俊敏なデータパイプラインによる意思決定の迅速化
今日のビジネス環境では、多様なソースから生成される膨大なデータを、いかに迅速かつ効率的に分析可能な状態にするかが問われています。クラウドネイティブで設計され、インテリジェントな自動化機能を備えたデータ統合ソリューションは、この課題に対する明確な回答です。ノーコード/ローコードのビジュアルインターフェース、事前構築済みの連携テンプレート、そして柔軟なスケーラビリティは、データエンジニアリングの負荷を大幅に軽減し、データパイプラインの構築期間を劇的に短縮します。これにより、クラウドデータウェアハウス、データレイク、あるいはレイクハウスといった最新のデータプラットフォームへ、ビジネスニーズに応じたタイムリーなデータ供給が可能となり、意思決定の迅速化とデータドリブンなアクションを強力に支援します。
クラウドネイティブ・データ品質:信頼性の高いデータに基づく分析精度の向上とガバナンス強化
分析の精度と信頼性は、入力されるデータの品質に大きく依存します。クラウドネイティブなアーキテクチャとAI/MLを活用した自動データ品質管理機能は、データガバナンスプログラムの推進において中核的な役割を担います。データプロファイリング、クレンジング、標準化、名寄せといったプロセスを自動化し、継続的なデータ品質監視を実現することで、クラウド上のデータウェアハウス、データレイク、レイクハウスに格納されるデータの信頼性とセキュリティを担保します。これにより、分析結果の精度が向上し、誤ったインサイトに基づくリスクを低減するとともに、コンプライアンス要件への対応も強化します。
クラウドネイティブ・メタデータマネジメント:データ利活用の促進と全社的なデータ透明性の確立
データがサイロ化し、その意味や来歴が不明瞭な状態では、全社的なデータ活用は進みません。統一されたメタデータ基盤を全社レベルで構築し、インテリジェントかつ自動化されたエンドツーエンドのメタデータ管理を実現することが、この課題を解決する鍵となります。データの意味、関連性、リネージ(系統)を可視化することで、データ利用者は必要なデータを迅速に発見し、その信頼性を評価できるようになります。これは、部門横断的なコラボレーションを促進し、データ分析の効率性を飛躍的に高めるとともに、データガバナンスの徹底と説明責任の向上にも寄与します。
最新クラウドデータ管理ソリューション選定の要諦:将来を見据えた投資
最新のクラウドデータ管理ソリューションを選定する上で極めて重要なのは、単一クラウドに限定されず、マルチクラウド環境全体で一貫した、自動化・インテリジェント化されたエンドツーエンドのデータ管理機能を提供できるかという点です。これにより、特定ベンダーの技術や手作業によるコーディング、限定的な機能に縛られることなく、柔軟かつ拡張性の高いデータ基盤を構築できます。さらに、既存のオンプレミス環境やレガシーシステムへの投資を保護しつつ、段階的にクラウドへ移行・連携できるソリューションであれば、将来にわたる継続的なデータ活用とITインフラの最適化を保証します。
クラウドアナリティクス・モダナイゼーションがもたらす業界別変革インパクト
インテリジェントな自動クラウドデータ管理を実装し、アナリティクス基盤をモダナイズすることは、業種を問わず、迅速なインサイト獲得とイノベーション推進を加速させます。以下に具体的なイニシアチブ例を挙げます。
金融・保険・証券業界:リスク管理高度化と顧客エンゲージメント強化
金融サービス企業にとって、データは生命線です。不正検知の精緻化、与信・融資判断におけるリスク評価の高度化、市場動向予測の精度向上、投資ポートフォリオの最適化、そして日々発生する膨大なトランザクションデータの効率的な処理・管理は、データ活用能力に大きく左右されます。インテリジェントな自動クラウドデータ管理を通じて顧客の行動や潜在ニーズを深く理解することで、パーソナライズされた金融サービスの提供、最適な金融商品の提案、そして顧客口座や機密情報の保護強化といった、競争優位に繋がる価値創出が可能です。
特に不正対策においては、既存の監視システムのモダナイゼーションやクラウドデータレイクへの戦略的投資、AI/MLを活用した予測分析モデルの導入が不可欠です。これにより、従来の手法では見抜けなかった巧妙な不正行為も、早期に検知し、迅速に対応することが可能になります。また、構造化・半構造化されたビッグデータを統合・分析することで、新たな顧客セグメントを発見し、効果的なマーケティング戦略を展開することも、インテリジェントなデータ管理基盤が実現する重要な成果の一つです。
医療業界:患者中心の医療実現とオペレーショナルエクセレンス
医療機関におけるアナリティクスプラットフォームのクラウド移行は、患者ケアの質的向上、業務プロセスの生産性向上、そして優れたペイシェントエクスペリエンスの提供に直結します。クラウドベースのソリューションが持つスケーラビリティと処理能力は、ウェアラブルデバイスからのセンサーデータ、電子カルテ、ゲノム情報、画像データといった多様かつ膨大な医療データを効率的に収集・統合・分析することを可能にします。これにより、個々の患者の健康状態の悪化を高精度に予測し、先制的な予防医療介入や個別化治療法の開発を支援します。
インテリジェントな自動クラウドデータ管理機能は、医療従事者だけでなく、患者自身への適切な情報提供も促進します。例えば、患者ポータルを通じて、検査結果や診療記録といった自身の健康情報へセキュアかつリアルタイムにアクセスできる環境を提供することは、患者の治療への積極的な参加を促し、医療機関との信頼関係を強化します。さらに、診療予約、請求情報の確認、財政的支援に関する情報提供などをオンラインで完結させることで、患者の利便性向上と医療機関の業務効率化を両立させることが期待できます。
このように、クラウドアナリティクスのモダナイゼーションは、単なる技術刷新に留まらず、ビジネスモデルの変革、新たな価値創造、そして持続的な競争優位性の確立を実現するための戦略的投資と位置づけるべきです。