目次
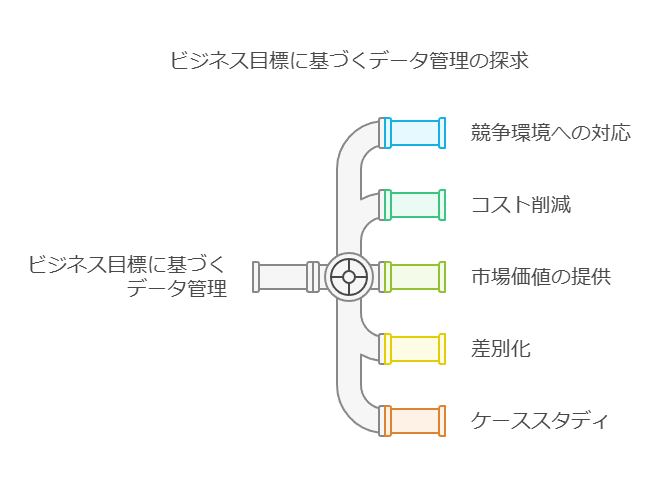
データ管理の視点で考える「正しい問い」:ビジネス目標から始める
効果的なデータ管理プログラムを構築するためには、まず「ビジネス目標」に沿った正しい問いを立てることが重要です。従来、企業が最優先にするポイントはコスト削減でしたが、今日の競争環境では企業がどのように市場価値を提供するか、どのような差別化を図るかといった要素が強く求められています。例えば、以下のようなケースにおいて、企業の優先目標に応じたクラウドプログラム設計の違いが生じるでしょう:
コスト重視:低コストでの提供を優先し、価格競争力のあるプロバイダーとしての地位を確保する。
市場投入期間の短縮:迅速なプロダクトデリバリーを重視し、アジャイルなクラウドインフラを選択する。
M&Aの強化:M&A後の迅速な統合やスケーリングに対応するための柔軟なデータアーキテクチャを構築する。
グローバル展開:各国の規制や市場要求に即応できるグローバルなデータ管理体制を構築する。
業界でのリーダーシップ強化:独自のデータ戦略で他社と差別化を図り、業界リーダーとしての地位を確立する。
データ管理プログラムにおける主な制約要素
次に、プログラムの設計において、会社が従うべき「制約」についても慎重に検討する必要があります。理論的には、企業はAWS、Azure、OpenStackなど任意のプラットフォームを利用できるはずですが、実際には企業ごとに異なる法規制やセキュリティ要件などにより、選択肢が制限されることが多々あります。
主な制約例
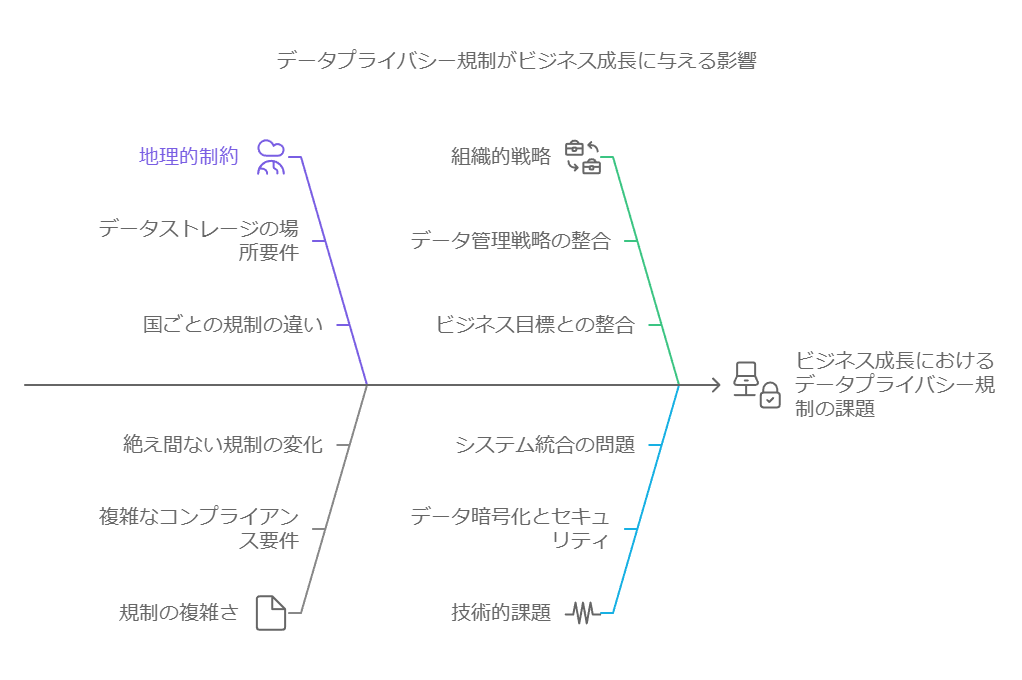
セキュリティとコンプライアンス:特定のデータが各国のセキュリティ規制やコンプライアンスルールの対象となるかどうかを確認する必要があります。企業が異なる国や州をまたいでビジネスを展開する場合、データの保管場所が制約の対象となり得ます。
データプライバシー規制:データ保護が厳しい国でのデータ配置は、事業の成長において大きなハードルとなる場合があります。クラウドプログラムを計画する際、プライバシー規制がどのように企業に影響を与えるかを理解し、データ管理を通じてビジネス目標を支援する戦略が不可欠です。
データ管理の設計段階から、これらの要因を取り入れることで、企業はより戦略的かつ持続可能なクラウドプログラムの実現に近づくことができます。
データ管理における「イベント監視」とアジリティ支援:コンプライアンスと迅速な意思決定を実現する
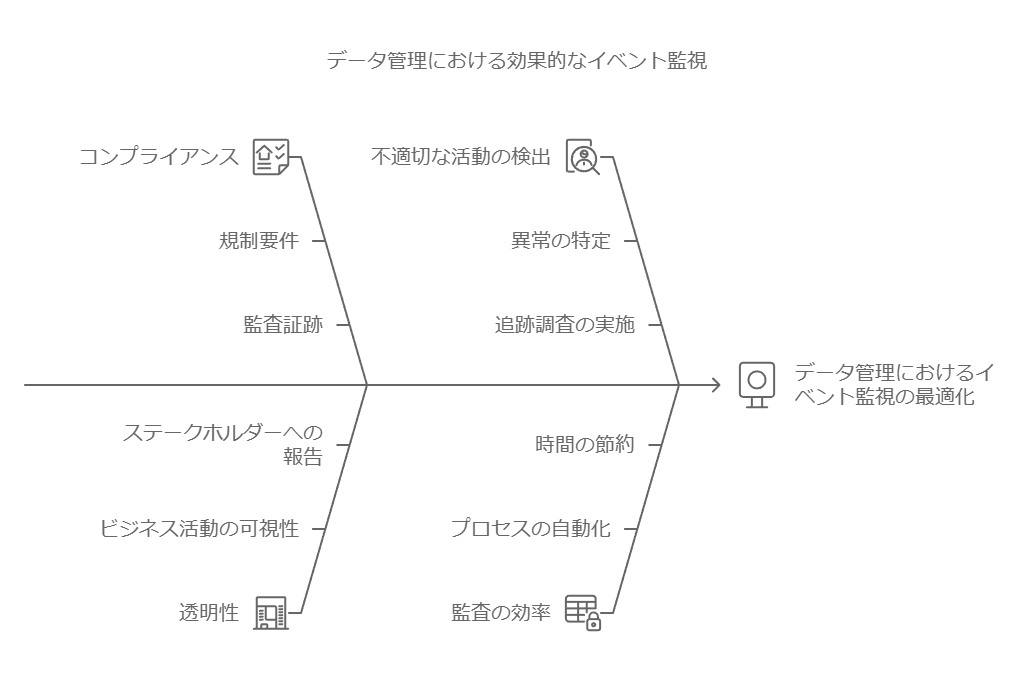
データ管理において、イベント監視が果たす役割は非常に重要です。たとえば、アクティビティが発生したことを確認するために自動生成される監査証跡ログは、コンプライアンスの検証や不適切な活動の追跡調査に役立ちます。このデータを活用することで、監査担当者はビジネスにおける活動の透明性を高め、法令遵守の一環として必要なデータを効率的に確認することが可能です。
ブロックチェーンは、さらに信頼性が求められるシーンで活用されます。資格情報の発行、送金、契約の承認など、データによって各イベントの真正性を保証する場合、ブロックチェーンは改ざん不可能な記録を提供します。このように、データを自動化された監査ガードレールとして使用することで、複雑で時間のかかるコンプライアンスプロセスを効率化し、ビジネスのアジリティ(迅速かつ柔軟な対応)を実現することができます。
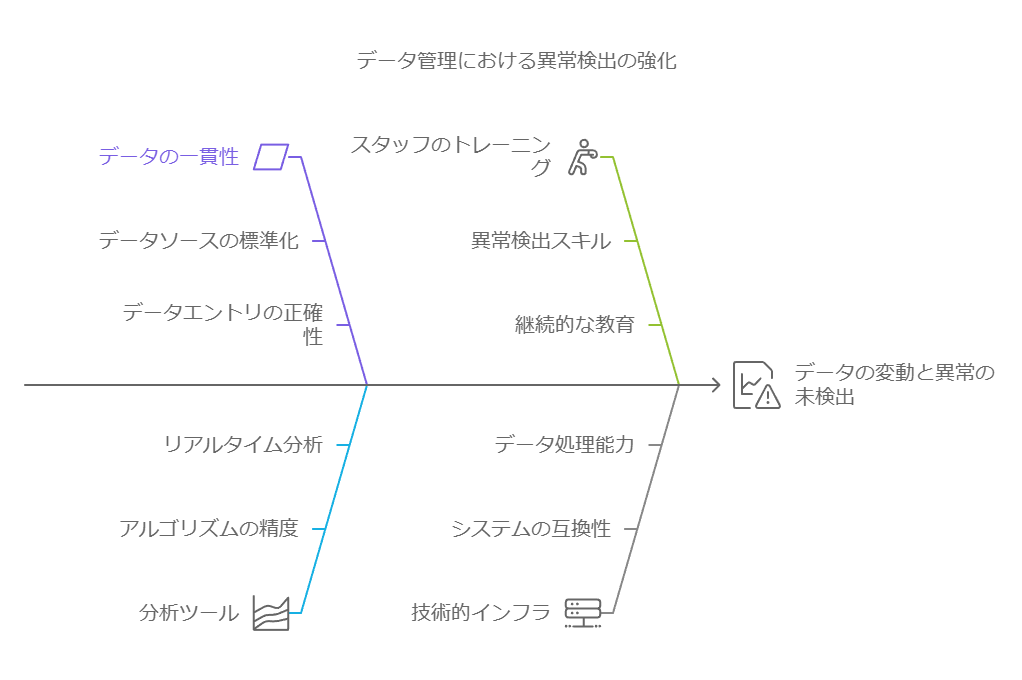
アジリティの実現における課題
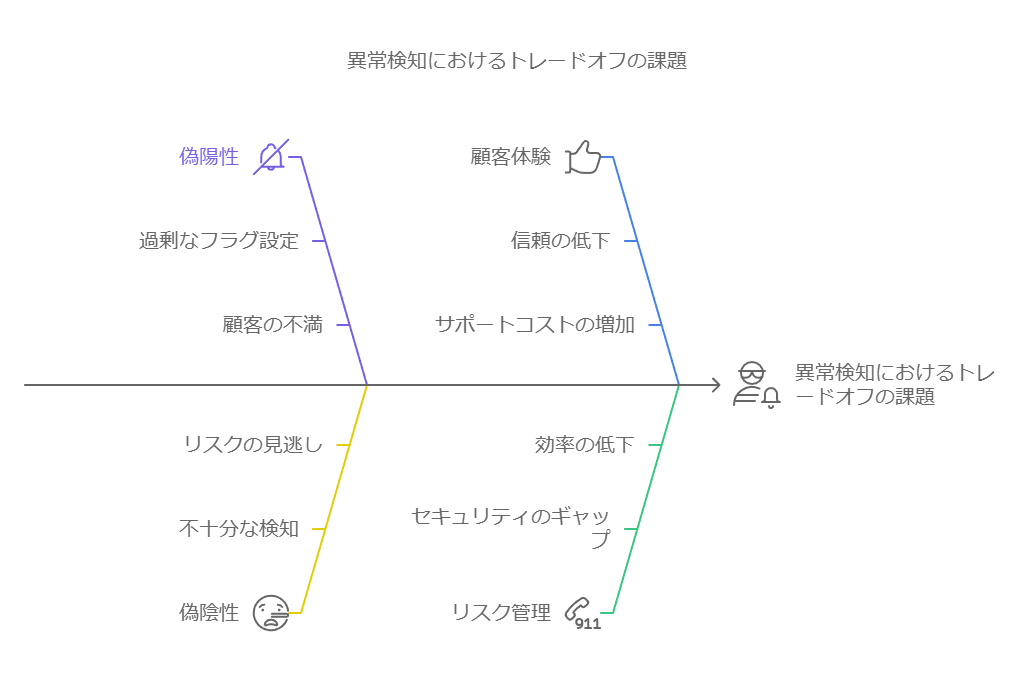
ただし、データを利用したアジリティ支援には課題も伴います。データから適切な推論を導き、最適な意思決定を下すには専門的な知識が必要で、データそのものが答えを示すわけではありません。また、異常検知やコンプライアンスに関して、偽陽性と偽陰性のトレードオフも考慮しなければなりません。たとえば、異常な取引を検知しようとした場合、過剰なフラグ設定が顧客の不満を引き起こす可能性がある一方、検知が少なすぎると不正の発見が遅れるリスクが生じます。
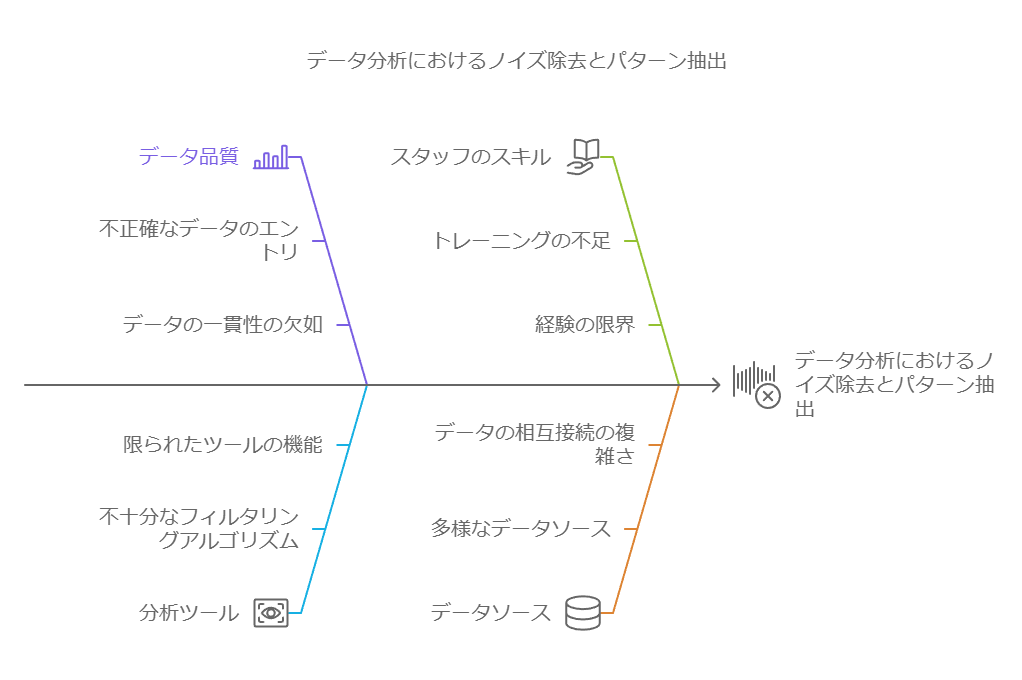
さらに、データセットが大きくなるとノイズが増え、重要なパターンが埋もれてしまう可能性もあります。データのアジリティをサポートするためには、信号(意味のあるパターン)とノイズを見極め、迅速に対応するプロセスが求められます。
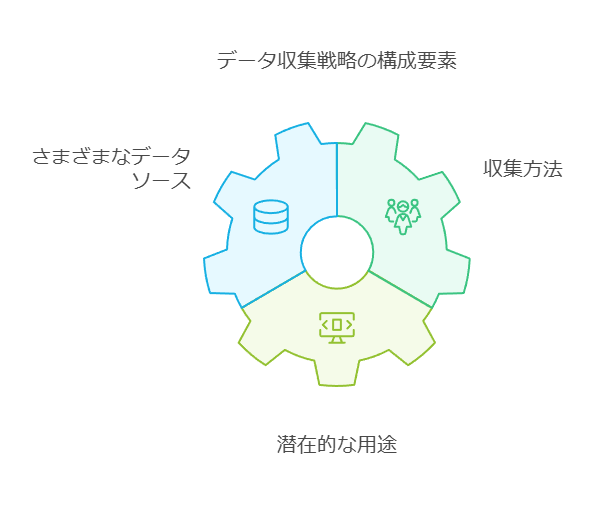
データアジリティを高める6つのステップ
データ収集の多様性:既存の仮説に限定せず、さまざまな用途で活用可能なデータを収集します。
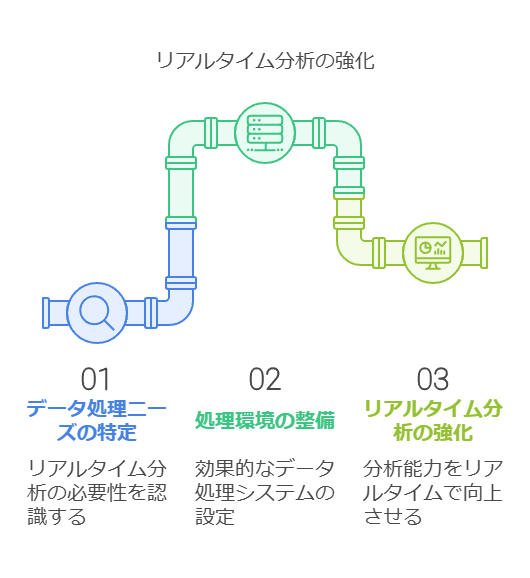
リアルタイム分析の強化:意思決定を迅速化するため、リアルタイムでのデータ処理環境を整備します。
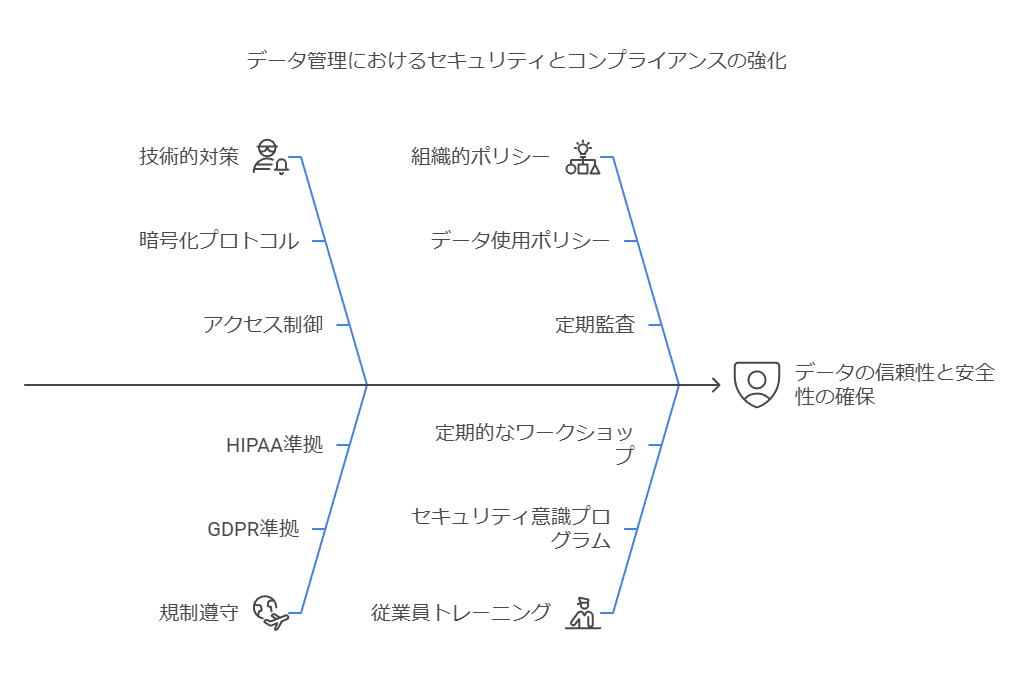
セキュリティとコンプライアンスの強化:データの信頼性と安全性を確保し、規制遵守を徹底します。
ノイズと信号の識別:データの価値を引き出すため、ノイズを効果的に除去し、重要なパターンを抽出します。
プロアクティブなトラブルシューティング:データの変動や異常を早期に察知し、リスクを未然に防ぎます。
柔軟なデータアーキテクチャの構築:組織が変化に迅速に対応できるよう、スケーラブルで柔軟なデータ基盤を構築します。
データアジリティの実現は、教育機関や多様な組織にとっても重要です。想定外の変化に柔軟に対応し、新たなイノベーションを生み出すためには、データの柔軟な収集・活用を目指すことが必要です。
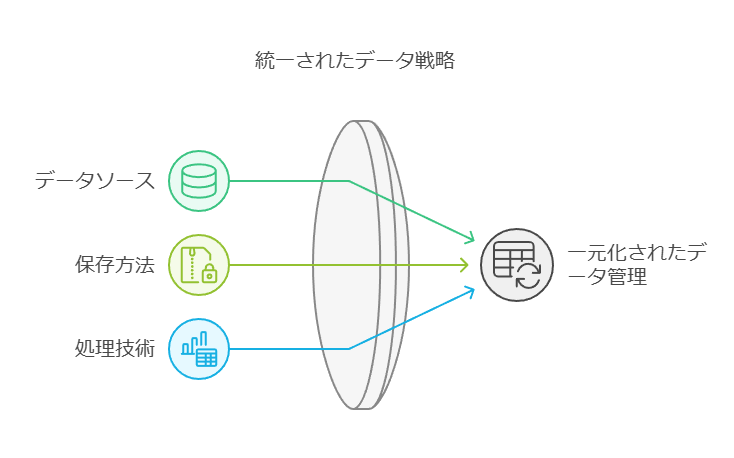
データ管理:多様なデータソースと形式に対応する戦略的アプローチ
新しいデータソースやデータ形式の増加に伴い、従来の記録システムの価値が再認識されつつありますが、同時にデータ管理の複雑さも急速に増しています。今日の企業が競争力を維持するためには、多様なデータアセットを効果的に取得、保存、処理するための戦略的な管理体制が求められています。以下は、これを実現するために必要な重要なポイントです。
1. 新しいデータアセットの取得・保存・分析
従来のデータ管理システムは、データ量、速度、種類の多様性や正確さに対応する設計がされていないため、モダンデータアプリケーションに対応するには限界があります。特に新しいデータソースや異なるデータ形式を迅速に取得し、それらを分析に活用することで、これまで得られなかったビジネス洞察の発見や新たな収益機会の創出が可能になります。
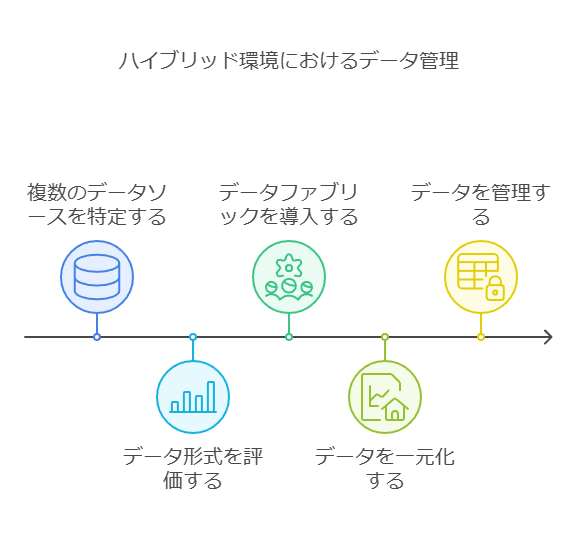
2. 多様なデータ環境への対応と管理の一元化
現在のデータエコシステムは企業、顧客、サプライチェーンが相互に関わり合い、情報がエッジやクラウド、オンプレミス環境で生成・共有されています。そのため、データがどの環境で生成されても、その形式を変更することなく文脈を維持しながら取得、保存、処理することが不可欠です。また、リアルタイムでデータの可視性を確保することで、迅速な対応や修正が可能になります。
3. ハイブリッド環境でのデータ管理とデータファブリックの役割
ハイブリッドクラウド環境を跨いでデータ管理の一元化を実現するためには、データファブリックの導入が効果的です。データファブリックは、複数のデータソースや異なる形式のデータを1つのビューで保存、検索、処理できる環境を提供し、データの所在を問わずシームレスにアクセス可能にします。これにより、分散されたデータ資産を一元的に管理し、企業全体でのデータ活用を促進します。
このようにして、データの分散化による課題を解決しつつ、迅速かつ効率的なデータ活用の基盤を整えることで、企業の競争力と新たなビジネス価値創出の基盤を築くことが可能です。
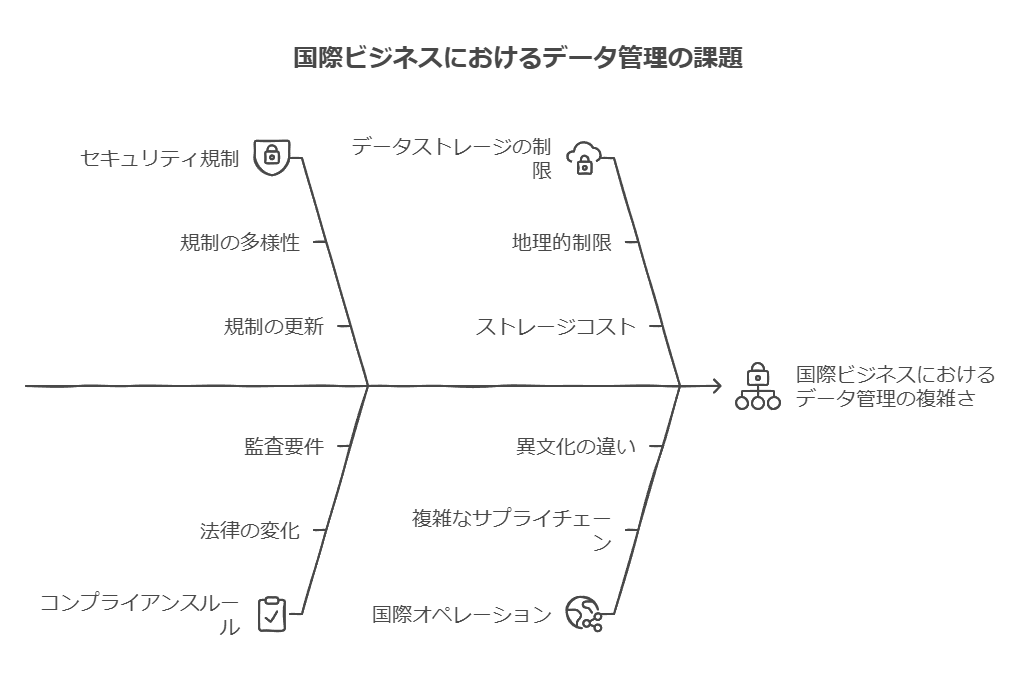

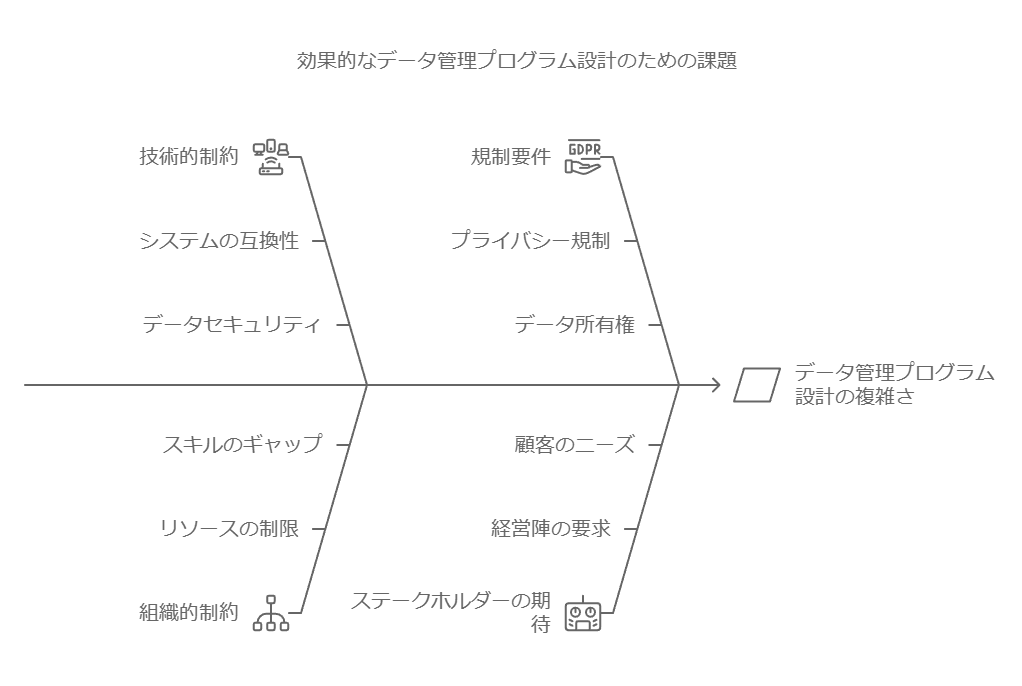
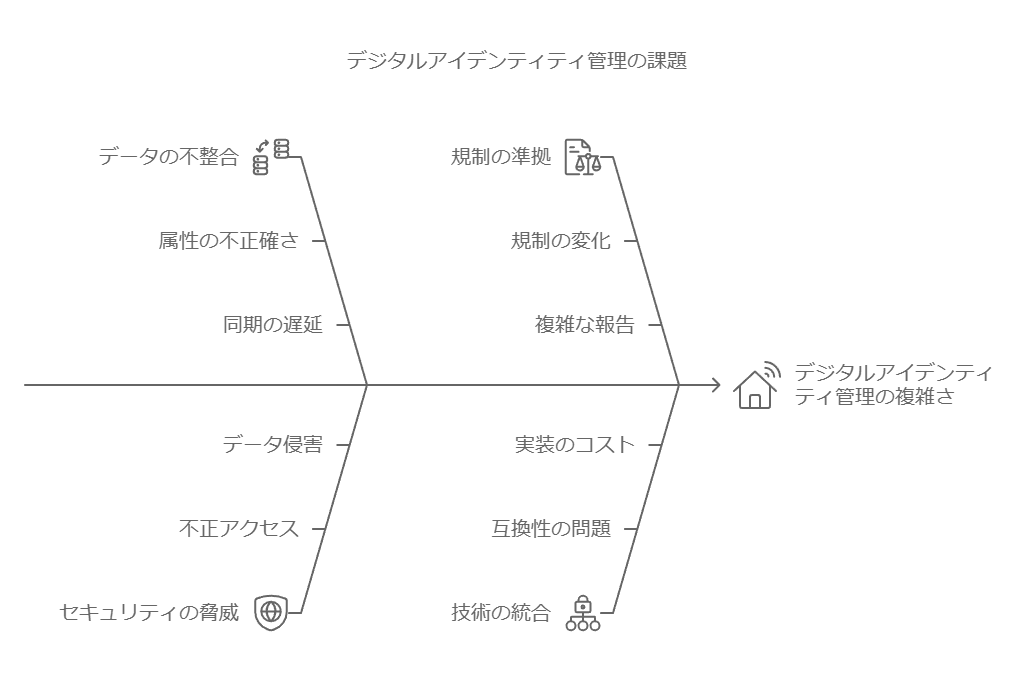
データ管理:企業が抱えるデジタルアイデンティティの7つの課題とその解決策
企業が抱えるデジタルアイデンティティに関する課題は、ID管理、運用、データセキュリティにわたります。以下、課題とその解決策を詳しく解説します。
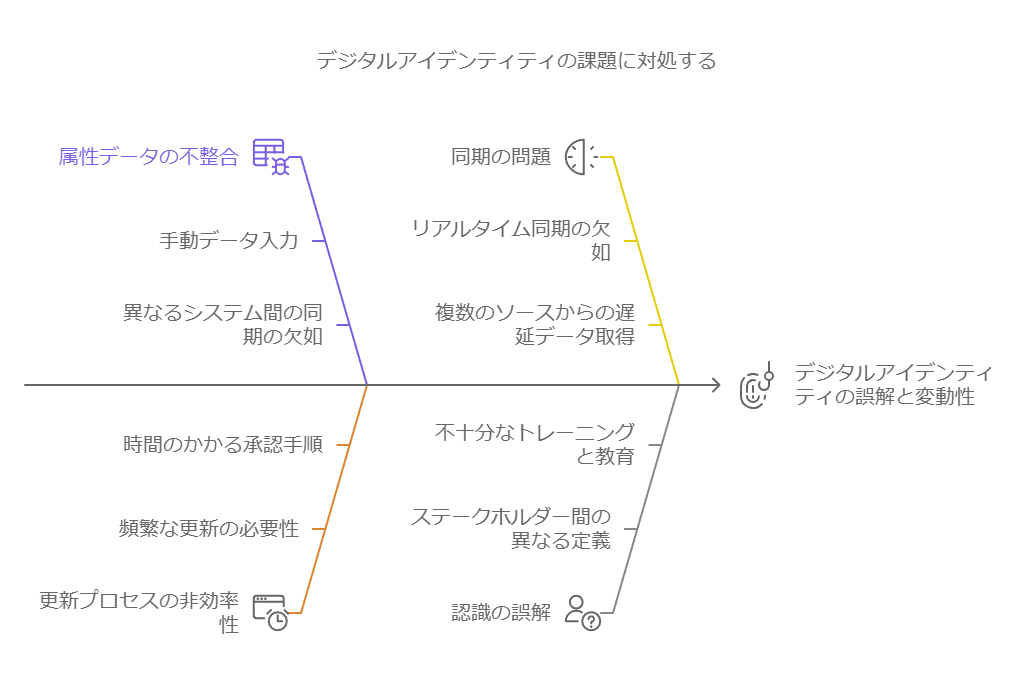
課題1: デジタルアイデンティティの誤解と変動性
問題点: デジタルアイデンティティは単なるIDとは異なり、ユーザーの属性や行動データが組み合わさったものです。ライフステージやサービス内容の変更により、データが実態に合わなくなることがあります。 解決策: 定期的な属性データの更新と同期を自動化し、ユーザーのライフサイクルに応じたプロファイル更新体制を整備することで、ミスマッチを減らします。
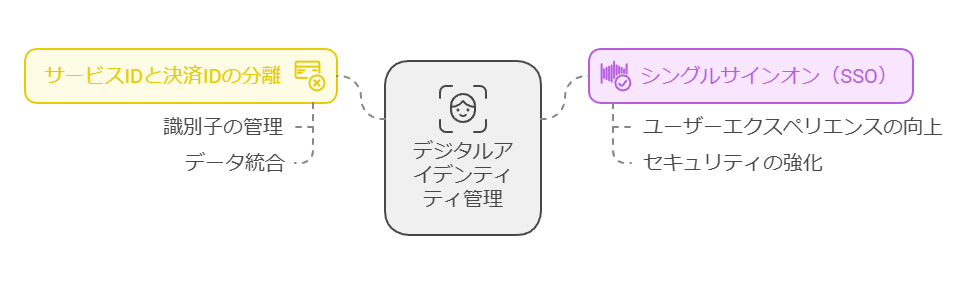
課題2: 分離されたサービスIDと決済ID
問題点: サービスIDと決済IDの分離により、ログインの手間が増え、ユーザーが離脱するリスクがあります。 解決策: シングルサインオン(SSO)や統合ID管理を活用し、異なるサービス間での一貫したユーザーエクスペリエンスを実現します。これにより、認証の煩雑さを解消し、離脱率を低減できます。
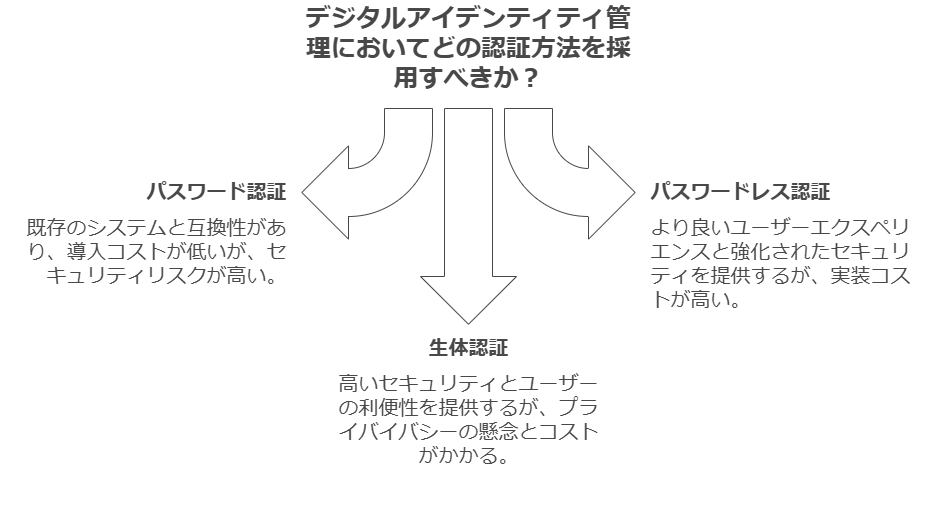
課題3: パスワード認証の限界とセキュリティリスク
問題点: 多くのサービスでIDとパスワードを使いまわすユーザーが多く、不正アクセスのリスクが高まります。 解決策: パスワードレス認証や生体認証など、パスワードを使用しない認証方式の導入を検討し、セキュリティの強化を図ります。また、教育や認証方法の標準化でユーザーの認識を高めます。
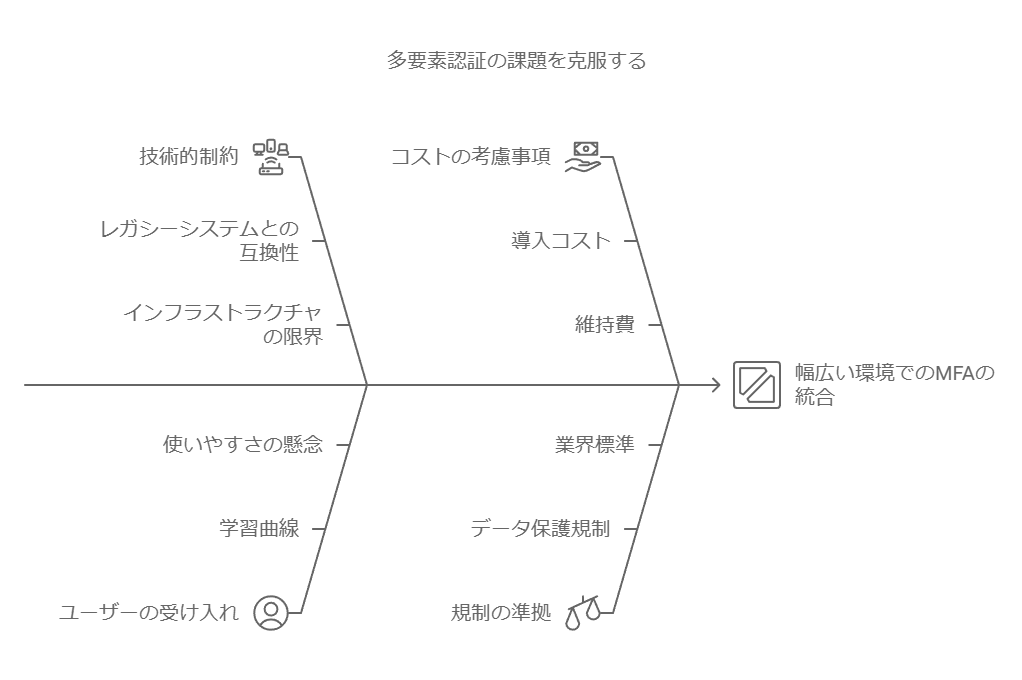
課題4: 多要素認証(MFA)とデバイス対応の問題
問題点: MFAは効果的なセキュリティ手段ですが、対応デバイスが限られることがあり、特に企業の貸与デバイスと私有デバイスの管理が複雑です。 解決策: MFAの選択時に対応デバイスの多様性を考慮し、幅広い環境で使えるソリューションを導入します。企業内のデバイス管理ポリシーも見直し、アクセス制限や認証のルールを一貫させる体制を整えます。
課題5: ユーザー属性変動への対応
問題点: ユーザーの属性は頻繁に変わり、特に消費者向けサービスでは住所変更や転職、入退社などへの対応が求められます。 解決策: デジタルアイデンティティのライフサイクル管理を導入し、個人の属性変更が即座に反映されるようにします。また、入退社や人事異動に応じたID管理体制を構築し、アクセス権の適切な付与と廃棄が行えるようにします。
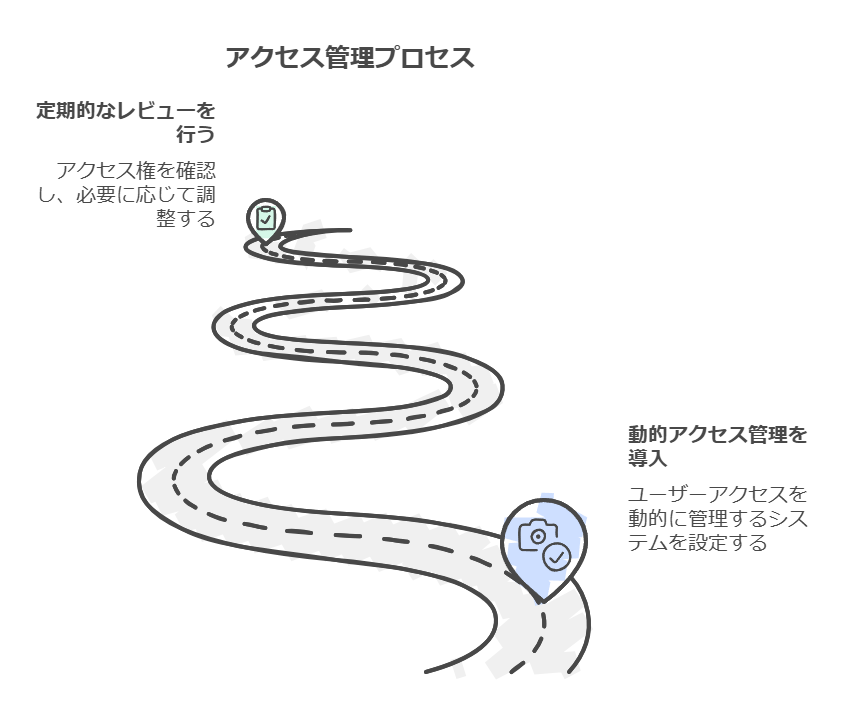
課題6: 社内および外部アクセス権の管理
問題点: 部署や職位に応じたアクセス権の変更が遅れると、セキュリティリスクや業務効率の低下につながります。外部パートナーのアクセス範囲の管理も重要です。 解決策: 役職や所属によって自動的にアクセス権が変更される動的アクセス管理を導入し、外部パートナーには限定的なアクセス権を設定します。定期的なレビューとアクセスログの監査も行い、セキュリティと利便性を両立させます。
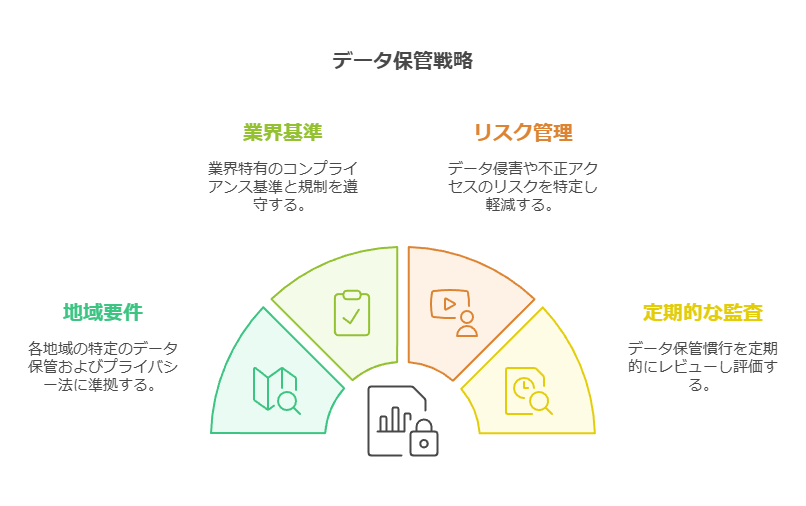
課題7: データ保管場所とコンプライアンス
問題点: データの保管場所によっては、コンプライアンス要件が異なり、特にクラウドサービスではデータの所在地やアクセスが問題となる場合があります。 解決策: 各国や業界のコンプライアンス要件に基づき、オンプレミス、パブリッククラウド、プライベートクラウドを組み合わせたデータ保管戦略を構築します。クラウド事業者のサービス内容も定期的に確認し、規制に準拠したデータ管理体制を確保します。
まとめ
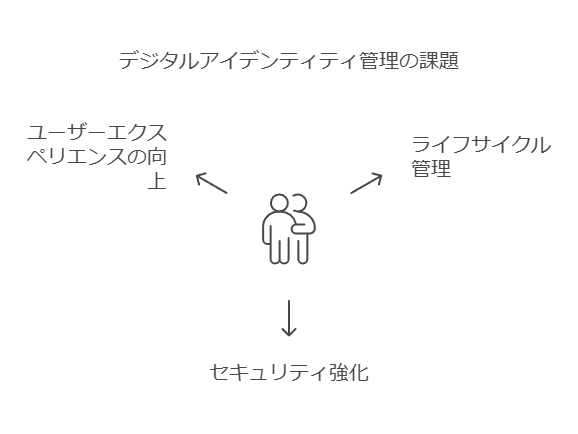
デジタルアイデンティティの管理は、ユーザーエクスペリエンスを向上させつつ、企業のセキュリティ体制を強化するための重要な要素です。適切な認証手段やアクセス管理を選定・導入し、リアルタイムでの対応と透明性を重視することで、企業全体での一貫したデジタルアイデンティティ戦略を実現できます。
デジタルアイデンティティ活用によるビジネスへの貢献
企業のデジタルトランスフォーメーション(DX)推進が進む中、特に「2025年の崖」を控えて多くの企業が急速にビジネス変革に取り組んでいます。その中でも、自社独自のアプリケーション開発を進める際に重要となるのが「デジタルアイデンティティ」の有効活用です。ゼロトラストがセキュリティでのキーポイントであるように、ビジネスにおいてはデジタルアイデンティティがDX推進において大きな役割を果たします。
デジタルアイデンティティによるユーザー理解の深化
GAFAのように高度にパーソナライズされたサービスを提供するためには、ユーザーのデジタルアイデンティティの把握が不可欠です。デジタルアイデンティティには、ユーザーの行動履歴や関心事項が含まれており、これにより各ユーザーへ最適なタイミングで適切な情報やサービスを提供できます。たとえば、店舗展開や不動産関連業界などでも、こうしたアイデンティティデータを活用してターゲットマーケティングやユーザー体験の向上を図ることが可能です。デジタルアイデンティティの活用は、まさにDXの一環として企業のビジネス変革を実現するものといえます。
自動車保険業界におけるデジタルアイデンティティ活用例
デジタルアイデンティティの活用は、自動車保険業界でも活用されつつあります。顧客の自動車に緊急時信号を送信するデバイスを設置し、走行データを含む運転履歴を収集することで、さらなる発展が期待されます。例えば、立ち寄り場所、運転パターン、また事故が発生しやすいエリアなどの情報は、ロードサービスの最適化や自動車保険料の調整に役立てることが可能です。こうしたデータは、ユーザーに直接メリットを提供するだけでなく、保険会社の運用効率化にも寄与します。もちろん、プライバシー保護の観点から、個人を特定できる情報は適切に管理・除去される必要がありますが、匿名化を含む最新のソリューションも多数登場しています。
デジタルアイデンティティがもたらすビジネス変革の可能性
様々な業界において、デジタルアイデンティティの効果的な活用はビジネス変革を推進する鍵となっています。顧客の行動やニーズをリアルタイムで把握し、パーソナライズされたサービスや新たな収益源の創出に活用することで、競争力を高めることが可能です。企業はこのデータ資産を生かし、デジタルアイデンティティ情報を効果的に活用することで、自社ビジネスを進化させる機会を得られるでしょう。
データ管理ツールの活用によるビジネスの最適化
多くのデータ駆動型組織はセルフプロビジョニング型のモデルを採用し、必要なデータ管理ツールやサービスに迅速にアクセスすることで、効率的なデータ活用を実現しています。このモデルでは、従来の構造化クエリから高度なデータ分析まで、多様なツールを通じて幅広い用途にデータを活用することが可能です。
データの可視化とモデリングツールによるインサイトの深掘り
データの価値を最大限に引き出すため、モデリングツールを用いたデータの視覚化やシナリオ作成が行われています。これにより、分析結果の把握が容易になるだけでなく、ビジネスシナリオに基づく意思決定の精度が向上します。AIや機械学習(ML)の技術を活用することで、結果予測、異常検知、データ分類、感情分析、パターン認識などの分野でも、より迅速かつ効果的なデータ処理が可能となり、新たなビジネスの可能性が開かれています。
データ処理の高速化とクラウド利用の成功事例
データの迅速な分析は多くの産業で求められています。たとえば、オーストラリアのアデレード大学は、クラウドベースのハイパフォーマンスコンピューティング(HPC)を活用して48の小麦エクソームと18の大麦ゲノム全体を分析し、通常2週間かかる処理を6時間で完了させました。このようなクラウド環境の利用は、データ処理のスピードを劇的に向上させ、研究プロセスを効率化します。
教育分野における機械学習ツールの革新
Education Perfect (EP) のようなEdTech企業では、AWSの機械学習およびデータ分析ツールを使用して、生徒の成長をリアルタイムで追跡し、カスタマイズされたカリキュラムやフィードバックを提供しています。MLの活用により、個別化された学習機能が強化され、学生一人ひとりに最適な学習サポートが提供可能です。また、Sky Newsのようなメディア企業も、機械学習を通じて視聴者体験を向上させています。
機械学習導入の3つのアプローチ
AWSを利用した機械学習には、以下の3つのアプローチがあります。
既存モデルの活用: Amazon RekognitionやAmazon Lexといった事前トレーニング済みのモデルを使用し、画像認識や自然言語理解などの機能をすぐに導入する方法です。
独自モデルのトレーニング: Amazon SageMakerを使用して、特定のニーズに応じた独自のモデルをトレーニングし、データ分析をカスタマイズする方法です。
高度なカスタムMLモデルの開発: 専門知識を持つデータサイエンティストがAWSのML向けサービスを活用し、独自のアルゴリズムやトレーニング方法を使用して高度なモデルを構築するアプローチです。
これらのツールは、企業や教育機関がデータの活用を最大化し、新しいインサイトやビジネス機会を発見するために役立ちます。
データ管理におけるスキル向上の重要性
データを効果的に活用するには、データから価値を引き出すためのスキルを持つ従業員が不可欠です。この必要性が、近年データサイエンティストの需要が高まっている主な理由です。もちろん、統計や分析の知識が少ないユーザーにも利用可能なツールが増えていますが、データを最大限に活用し、精度の高い意思決定に結びつけるためには、データの理解と正確な推論を行えるスキルが求められます。
ケーススタディ:データ分析の課題と統計スキルの重要性
統計的なスキルが不足していると、平均値に過度に依存し、データの分布全体を無視することがあります。米国移民局での経験からも、申請処理時間の短縮を図るために平均処理時間を追跡しましたが、少数の例外的なケースが平均を歪めていることが後に判明しました。国家安全保障や詐欺の懸念で時間がかかるケースが全体の処理時間に偏りを与え、その影響で施策の成果が十分に確認できなかったのです。
その後、パーセンタイル(85%)を使ってケース全体の改善状況を把握することで、多くのケースに対する施策の効果が確認できました。このケースが示すように、データとツールだけでなく、正確な分析スキルを持つ人材の重要性が明らかです。
データ提示と意思決定への影響
さらに、データの提示方法にも注意が必要です。不適切な提示がされると、データに基づく意思決定が誤った方向に進むリスクがあります。データ提示の専門家であるEdward Tufte氏は、データが提示方法によって歪められ、不明瞭になる可能性を指摘しています。データに基づく意思決定の精度を確保するためには、データ分析に加えて、視覚化やプレゼンテーションのスキルも欠かせません。
データ駆動型組織が重視すべきスキル向上のポイント
データ活用をビジネスの競争優位性につなげるために、次のスキル育成に注力することが求められます。
統計リテラシーの向上:平均値に偏らずデータ全体の分布やパーセンタイルを含む幅広い分析手法を理解し、意思決定の基盤となるデータの見方を深めます。
データビジュアライゼーション:データの提示方法を工夫し、データの歪みや誤解を招かないようにします。視覚化の適切な手法を学ぶことで、効果的なデータ提示が可能です。
データ倫理とセキュリティの意識:誤解やバイアスを防ぐための倫理的なデータ処理方法を理解し、データのセキュリティとプライバシー保護にも配慮する能力を備えます。
このように、データ活用の効果を最大化するためには、単にデータツールを提供するだけでなく、データから正確なインサイトを得られるスキルを持つ人材の育成が不可欠です。
データコンサルタントの視点で、データ管理の戦略やAPJ(アジア太平洋および日本)地域における課題と解決策に焦点を当てて、経営層やITリーダーがデータ戦略の重要性を表示しました。
APJ地域におけるデータ管理とDataOpsの重要性
統一されたポリシーに基づくデータ管理は、データの一貫性を保ち、大規模な自動化を実現するために非常に効果的なアプローチです。しかし、アジア太平洋および日本(APJ)地域では、他の地域ほどDataOpsや統一されたデータポリシーが重視されていない現状があります。その理由は以下の5つの要因に分けられます。
政府の介入が少ない歴史的背景
APJ諸国の多くは、個人情報の保護に関しては一定の規制があるものの、民間企業のデータ管理に対して政府が直接干渉することは少ないという特徴があります。これは、他の地域に比べて統一されたデータ管理の取り組みが進んでいない一因です。
データ価値への認識不足
この地域の多くの企業では、全社的なデータポリシーによってデータの価値を最大化できるという認識がまだ十分に高まっていません。経営層が統一されたデータポリシーやDataOpsのメリットを理解し、積極的に導入を検討することが、データ管理の最適化に繋がります。
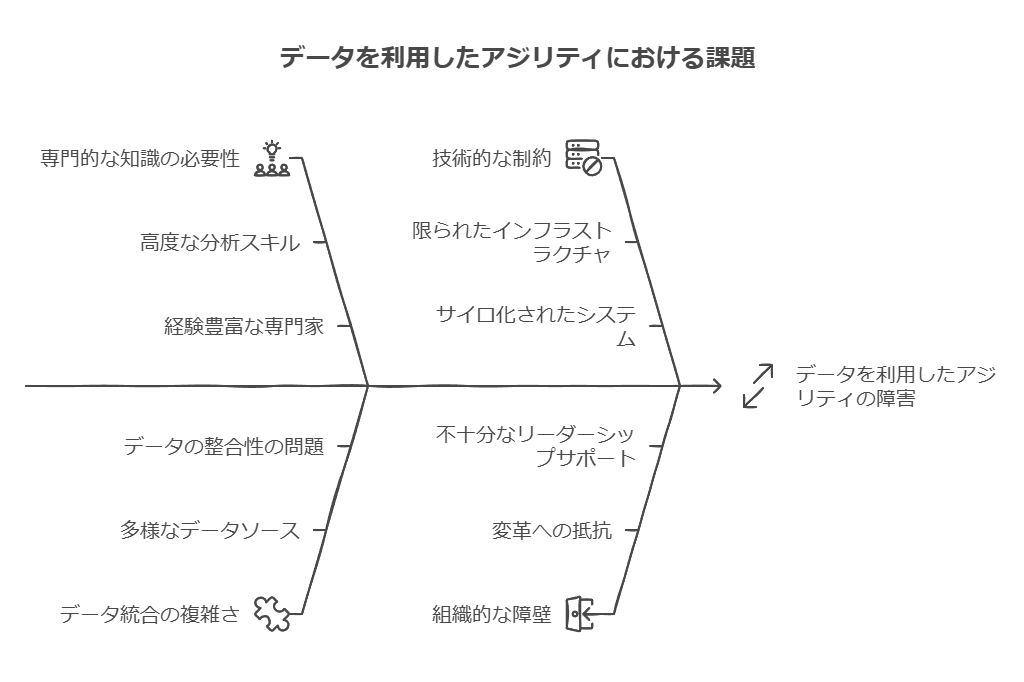
ITインフラの強化が必要
企業がリアルタイムでデータを収集・分析・活用するには、カスタマイズされたITインフラとAI対応のエッジデバイスが不可欠です。特に製造業では、エッジデバイスを工場の近くに配置し、リアルタイムでデータを処理できる安定したインフラストラクチャが重要です。経営部門とIT部門が協力して、適切なプラットフォームを確保し、効果的なデータ管理を実現する必要があります。
従業員のスキルトレーニングの必要性
DataOpsやデータアジリティを最大限に活用するためには、従業員の再トレーニングが不可欠です。既存の従業員に対して新たなスキルを提供するか、ビッグデータの分析や意思決定に精通した新たな人材を採用することで、将来のデータドリブンな組織を形成できます。この取り組みにより、企業はデータ活用に強い人材基盤を構築し、競争優位を確保できるでしょう。
将来を見据えた長期的投資の必要性
COVID-19のパンデミックにより、企業は予期せぬ事態に備えるための長期的な戦略と投資の重要性を再認識しました。APJの企業は、クラウドやデータ保存の変更に関して保守的な傾向がありますが、今後はより柔軟で先進的なデータ管理手法に移行する必要があります。データセキュリティの強化は、この変革を促進する最大の要因です。
データ管理の変革に向けたAPJ地域のチャンス
APJ地域では、データ管理に関して依然として保守的な姿勢が見られますが、DataOpsに投資することでその価値を最大化する大きなチャンスがあります。企業は、データ管理における保守的なアプローチから脱却し、セキュリティや自動化されたデータプラットフォームに投資することで、データドリブンな未来に向けて大きな飛躍を遂げることができます。
さらに、パンデミック後の新たなビジネス環境において、在宅勤務やリモートワークの普及は、企業によるより高度なデータ管理とセキュリティの取り組みを後押ししています。これにより、企業は一貫したポリシーの下でデータ管理を進化させ、競争力を維持しつつ、将来的な成長を確保することが可能です。
これにより、APJ地域の企業に向けて、データ管理の重要性とそれに伴う課題、そして将来に向けた具体的な改善策を提示しました。経営層やIT部門がどのようにデータ戦略を展開すべきか、より明確に理解できる内容となっています。
サプライチェーンのデータ最適化と収益化の戦略
消費者は製品やサービスへの迅速なアクセスを期待していますが、過剰な在庫は余剰コストや損失のリスクを高めます。このバランスを維持するには、最新のサプライチェーン管理が不可欠です。適切なデータ管理によって、小売業者とサプライヤーは変化に強いサプライチェーンを構築し、在庫計画や需要予測、リスク管理の精度を向上させることが可能です。
データの抽出とインサイト生成
トランザクションや消費者行動、IoTセンサーデータ、さらにはSNSのフィードバックなどから得られる情報を活用することで、在庫計画や予測に役立つインサイトを生成します。小売業者とサプライヤー間でのデータ共有が効率的に行われることで、サプライチェーンのリアルタイムな調整と最適化が可能になります。
リアルタイムと安全なデータの重要性
データの価値を最大限に引き出すには、リアルタイムかつ安全なデータ共有が必須です。サプライヤーは、需要に応じて迅速に在庫の移動や発注を行うことで、小売業者と連携したサプライチェーン管理が可能となります。しかし、レガシーシステムや従来の異種システムが、セキュアかつ効率的なデータ転送を阻んでいるケースが多く、FTPなどの非効率な方法に依存せざるを得ないこともあります。
データ収益化の可能性と課題
大手小売業者には、匿名の顧客データやPOSデータ、トランザクション情報など、サプライヤーやその他の関連企業にとって貴重なデータが蓄積されています。これらのデータを活用することで、サプライヤーのアナリティクスチームは需要予測やプロモーション計画で競争優位を確保し、また外部企業は市場インサイトの収集に役立てることが可能です。
プライバシーとデータ品質の課題
データ収益化を行う上での大きな課題は、顧客プライバシーの保護です。データ共有によるブランドリスクや法的リスクに留意しつつ、安全なプライバシー対策を講じることが重要です。また、データ品質の低さも収益化の障壁となり得ます。外部からのデータはフォーマットや内容に矛盾が多く、クレンジングと整理に時間とリソースを要する場合があります。レガシーシステムでは、これらのデータ品質の課題に対処するのが難しいため、データインフラのアップデートが必要です。
推奨アプローチ
サプライチェーンのデータ最適化と収益化には、次の要素が重要です:
リアルタイムデータインフラの導入
サプライヤーと小売業者がリアルタイムでデータ共有できるシステム基盤を整備することが不可欠です。
データクレンジングと統合プロセスの自動化
データの一貫性を保つためのクレンジングと統合を自動化し、データ品質を確保します。
プライバシー保護の強化
顧客プライバシーと法規制を遵守し、安全なデータ収益化が可能なフレームワークを構築します。
データ主導のサプライチェーン管理を推進することで、小売業者は消費者ニーズの変動に柔軟に対応し、効率的かつ競争力のあるサービス提供が可能になります。
データ管理における重要な要素:機能的なデータファブリック構築のための6つのコンポーネント
課題:データアーキテクチャの実現方法
データファブリックの概念を現実的なデータアーキテクチャに変換する際の主な課題は、データ資産を最大限に活用するためのアーキテクチャ設計です。ここでは、機能的なデータファブリックを構築するための6つの重要なコンポーネントについて解説します。
データ仮想化エンジン
データ仮想化エンジンは、データの抽象化を実現し、データソースからアプリケーションやデータ利用を切り離す役割を果たします。共通のアクセス層を提供することで、異なるデータソースを統一的に扱えます。このエンジンの中核にはインテリジェントなクエリオプティマイザがあり、処理コストの削減と速度の最適化に寄与します。
拡張データカタログ
データカタログは、データの探索や検出を促進し、コラボレーションやデータガバナンスの向上に寄与します。適切なメタデータの活用により、データの視認性や信頼性が強化され、利用の一貫性が向上します。
アクティブなメタデータ
アクティブなメタデータは、監査や履歴分析を可能にし、AI処理の基盤として機能します。リアルタイムで更新されるメタデータは、運用の透明性を提供し、将来の分析や意思決定を支援します。
セマンティックレイヤーの拡張メタデータ
セマンティックレイヤーは、従来の技術情報をビジネス用語、タグ、ステータスで補強し、セルフサービス、セキュリティ、ガバナンスの機能を向上させます。これにより、データ資産をより直感的かつ安全に利用できる環境が構築されます。
AIベースの推奨機能
プラットフォーム全体で利用できるAIベースの推奨機能は、使用状況から学習し、開発・運用・パフォーマンス調整などのデータ管理ライフサイクル全体を簡素化します。これにより、より効率的なデータ管理プロセスが実現します。
DataOpsおよびマルチクラウドプロビジョニング
DataOpsおよびマルチクラウドプロビジョニングの導入は、管理および運用コストを削減し、クラウドベンダーに依存しない柔軟なシステム構築を可能にします。多様なクラウド環境に対応しながらも、一貫した管理プロセスを維持します。
この6つのコンポーネントは、機能的かつ柔軟なデータファブリックの基盤を形成し、データアーキテクチャの成功に不可欠な要素です。それぞれの要素を組み合わせることで、企業のデータ活用がより効率的で柔軟性の高いものになります。