目次
- 1 ドキュメント管理戦略の最適化
- 2 データファブリックの必要性と進化:データ管理の新たな潮流
- 3 データアクセスの複雑化とデータファブリックの導入:進化するデータ管理戦略
- 4 データファブリックの概念とその戦略的意義:Gartnerの定義をもとに
- 5 データアーキテクチャへの変換:6つの重要なデータファブリックコンポーネント
- 6 データファブリックの実装アプローチ:柔軟性を持ったデータ統合の重要性
- 7 論理データファブリックの中核要素:データ仮想化の役割と実装の要点
- 8 データ管理におけるデータプロビジョニングの課題:効率的なデータファブリック戦略の構築
- 9 データ管理における分散アーキテクチャと論理データファブリックの重要性
- 10 データ検出機能とセマンティックレイヤーの役割:エンタープライズデータ管理の進化
ドキュメント管理戦略の最適化
現代の企業では、効果的なドキュメント管理が業務の効率化やコンプライアンス遵守において不可欠です。以下は、ドキュメント管理における重要な要素と、それに基づく最適化戦略です。
1. 必須ドキュメントとプロセスの関連付け
ドキュメントの管理において、特定の業務プロセスと関連付けられた必須ドキュメントの定義は不可欠です。これにより、業務の標準化が進み、適切なドキュメントが確実に管理されるようになります。プロセスごとのドキュメント要件を体系的に整理し、アクセスや管理が容易な仕組みを構築します。
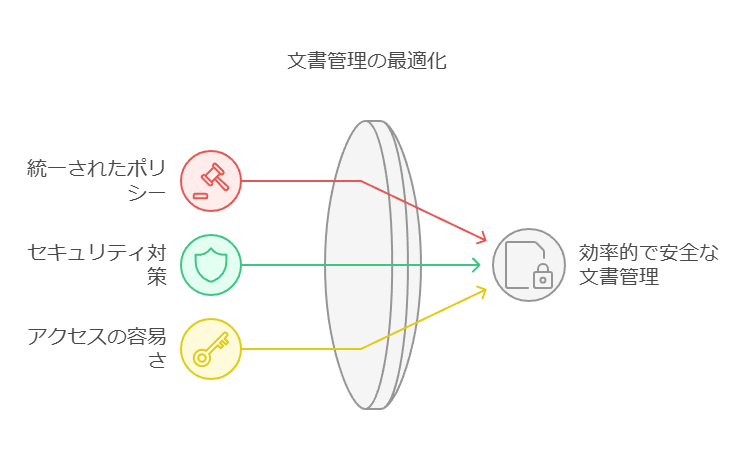
2. ドキュメント保存場所の統合管理
プラニスウェア上または外部でのドキュメント保存については、企業全体で統一されたポリシーが必要です。データセキュリティを確保しつつ、アクセス権限を適切に管理するために、保存場所の一元管理を推奨します。これにより、ドキュメントの分散を防ぎ、情報へのアクセスが容易になります。
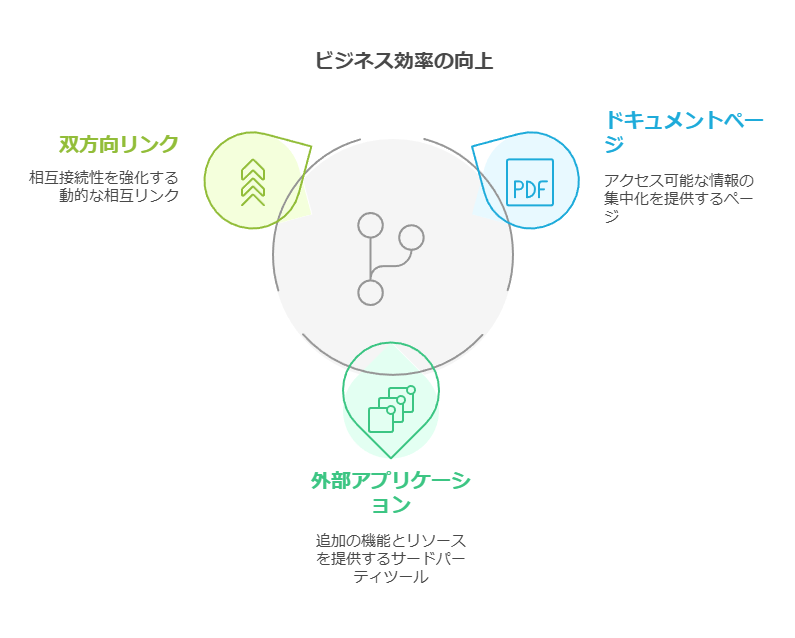
3. 双方向のダイナミックURLリンクの活用
すべてのドキュメントページと外部アプリケーション間で、双方向のダイナミックURLリンクを利用することで、業務の効率化が図れます。このリンクにより、関連情報へのアクセスが迅速化され、ドキュメント管理の精度が向上します。
4. スペルチェックと全文検索機能の重要性
スペルチェック機能や全文検索エンジンの導入は、ドキュメントの品質管理と迅速な情報検索に不可欠です。これにより、ドキュメントの正確性を高め、必要な情報を迅速に取得できる環境が整います。
アーキテクチャの最適化
ドキュメント管理システムのアーキテクチャは、業務効率とシステムの拡張性を左右する重要な要素です。
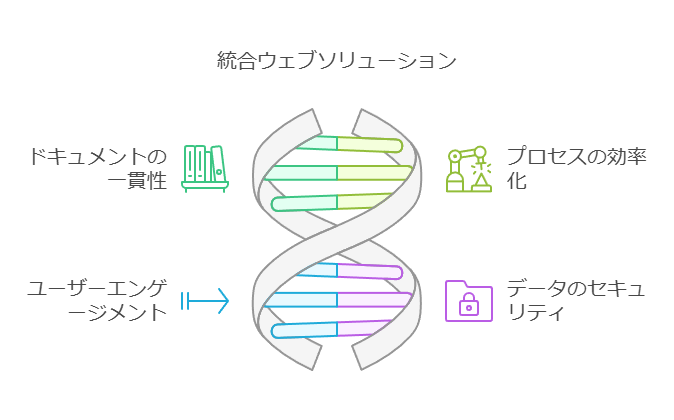
1. 統合されたウェブソリューション
統合されたウェブソリューションは、企業全体で一貫したドキュメント管理を実現するための基盤です。オールインワン製品の導入により、複数のツールやプラットフォーム間での整合性が確保され、運用の一貫性が向上します。また、対応言語が多様であることは、グローバルな展開を支援します。
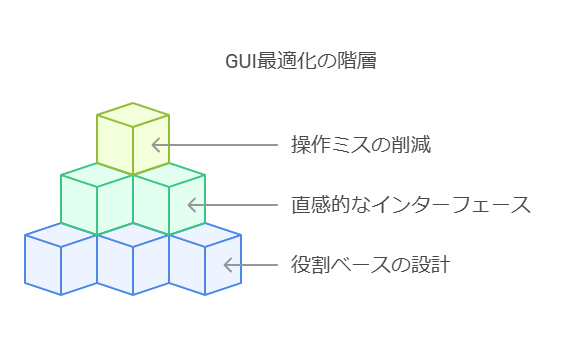
2. 役割ベースの直感的なGUI
役割ベースの直感的なGUI(グラフィカルユーザーインターフェース)は、ユーザーエクスペリエンスを向上させ、操作ミスを減らすための重要な要素です。複数回のアンドゥ/リドゥ機能を備えたインターフェースを提供することで、ユーザーが安心して作業を進められる環境を構築します。
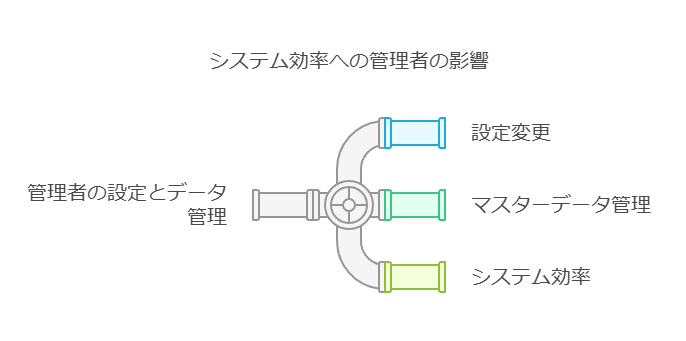
3. マスターデータ管理の柔軟性
機能分野の管理者が簡単に設定変更やマスターデータ管理操作を行えることは、システムの運用効率を高める要因となります。これにより、システムの柔軟性が向上し、変化する業務ニーズに迅速に対応できるようになります。
外部システムとの連携強化
企業のデジタル化が進む中で、外部システムとのシームレスな連携が求められています。
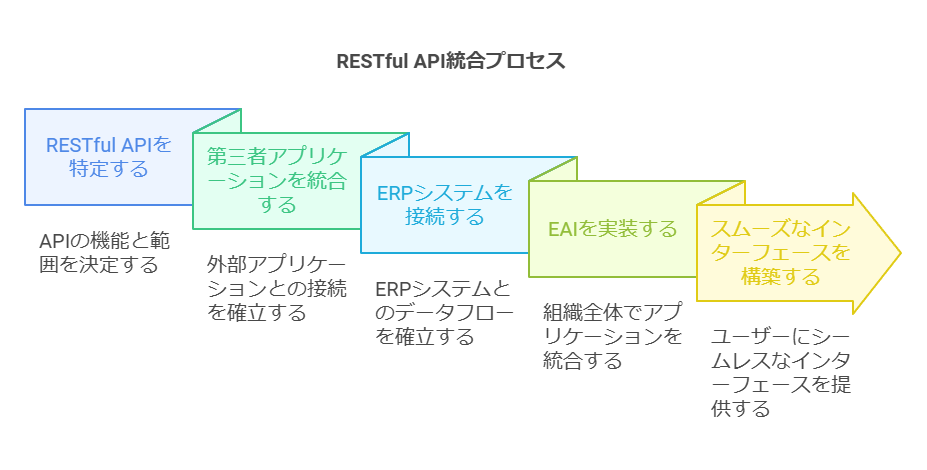
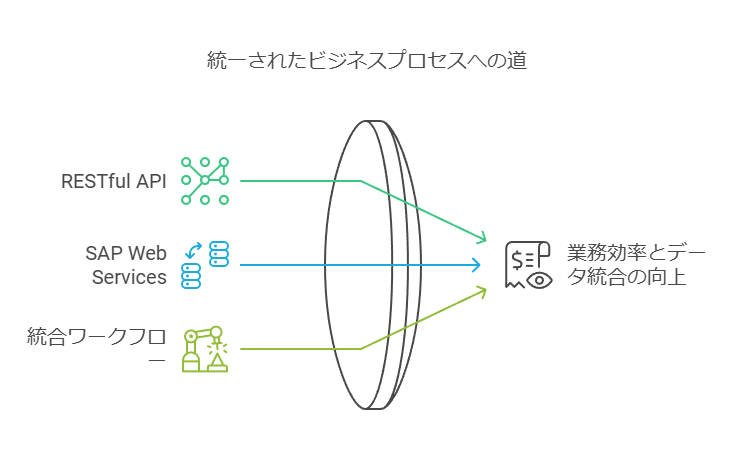
1. RESTful APIとフィードの活用
RESTful API(XMLおよびJSON形式)を活用することで、他の第三者アプリケーションやERP、EAIとスムーズに連携できるインターフェースを構築します。また、RSS形式のフィードを利用することで、情報の自動更新や通知機能を強化できます。
2. SAP Web Services認定コネクターの利用
SAPをはじめとする大手ERPシステムとの連携は、業務の効率化とデータの統合管理において重要です。認定コネクターを使用することで、安全で確実なデータ連携が可能となります。
3. 組み込みのコネクターと統合ワークフロー
Jira、Aha!、Azure DevOpsなど、広く利用されているドキュメント作成システムとの統合コネクターを活用することで、システム間のデータ共有と作業の自動化が可能になります。また、新規ワークフローを簡単に追加できるワークフローエディターの活用により、業務プロセスの最適化が進みます。
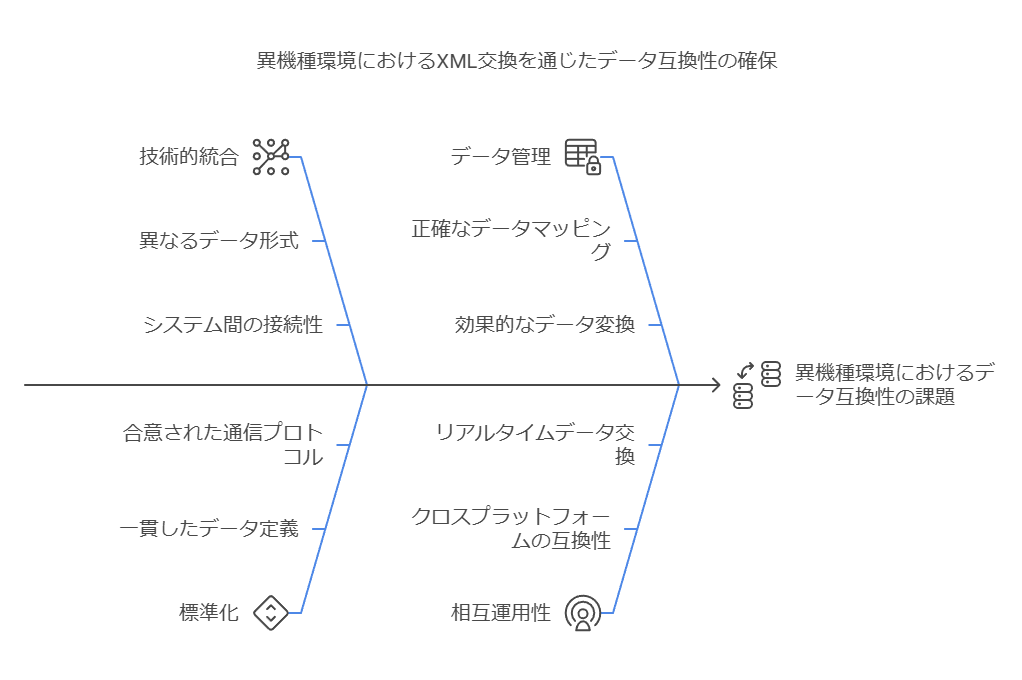
4. XML交換と互換性の確保
異機種交換環境におけるXML交換機能を活用し、オブジェクト全体のデータ互換性を確保します。これにより、複数のシステム間でのデータ整合性が保たれ、システムの拡張性が向上します。
ここでは、データコンサルタントの視点から、ドキュメント管理の各要素を企業全体の業務効率やデジタルトランスフォーメーションの推進にどのように貢献するかを強調しました。また、外部システムとの連携やシステムのアーキテクチャ設計の重要性についても具体的に説明しています。
データファブリックの必要性と進化:データ管理の新たな潮流
データファブリックは比較的新しい概念であり、その定義には幅があるものの、近年のデータ管理手法の進化からその必要性を理解できます。かつてエンタープライズデータウェアハウス(EDW)がデータ管理の中心でしたが、ビッグデータの普及に伴い、機械学習(ML)やデータサイエンスの分野が急速に台頭しました。こうした高度なアナリティクスや意思決定支援に対応するため、データ要件も複雑化の一途をたどっています。
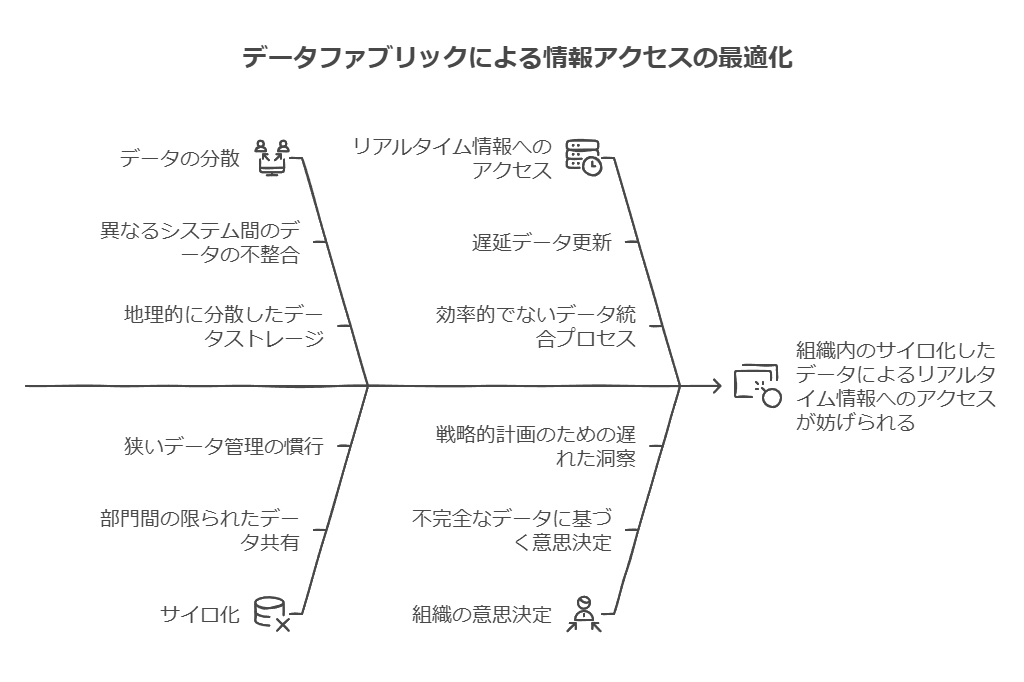
従来、IT部門は限られた予算の中で多くのシステムを管理する必要がありました。この制約から、ビジネス部門にもセルフサービス型のビジネスインテリジェンスやデータ統合のニーズが高まり、シチズンインテグレータやパワーユーザーがデータの舞台に参加するようになりました。クラウドやSaaSソリューションの導入は、こうした負担の一部を軽減しましたが、同時にデータが分散し、サイロ化が進むという新たな課題も生じました。
データファブリック導入の背景:多様化するデータ管理ツールと信頼性の確保
高度なデータ活用が進む中で、データファブリックは複雑化するデータ環境を統合するための基盤として注目されています。現在、EDWデータマートやリレーショナルデータベース(RDBMS)だけでなく、データレイクやNoSQLシステム、REST API、さらにはソーシャルメディアフィードやリアルタイムデータフィードなど、多種多様なデータソースが存在します。こうした専門化したツールが登場した一方で、組織が「信頼できる唯一の情報源(Single Source of Truth)」を構築するのはさらに困難になっています。
データファブリックの価値:複雑なデータ管理ニーズに応える柔軟性と統合力
データファブリックは、複数のデータソースを柔軟かつ統合的に管理することで、データの分散やサイロ化の問題を解消し、データの信頼性や可用性を高めます。従来のシステムがデータの一貫性を担保しにくくなっている中で、データファブリックはさまざまなデータ管理ニーズに対応し、組織がリアルタイムに価値ある情報を得られる環境を提供します。
結果として、データファブリックは、ビジネス部門とIT部門の連携を支え、企業全体でデータ駆動型の意思決定を可能にする重要なインフラとなっています。
データアクセスの複雑化とデータファブリックの導入:進化するデータ管理戦略
今日、データにアクセスするユーザー層は多様化しています。BIアナリスト、シチズンインテグレータ、データサイエンティスト、データスチュワード、IT担当者、データセキュリティの専門家といった多様なペルソナが、異なるスキルセットと目的を持ってデータにアクセスする必要があります。この状況により、組織全体でデータへのアクセス要件が急速に複雑化しています。
さらに、多くの企業がクラウドやマルチクラウドへの移行を進めており、これにより物理的なデータの分散が進むハイブリッドエコシステムが形成されています。こうしたエコシステム内で、IT部門はビジネスの継続性を確保しながら、柔軟に新しいアーキテクチャに適応する必要があります。
同時に、データコンプライアンスとガバナンスへの期待が高まり、GDPRやCCPAといった特定の法的基準への準拠や、外部からの脅威に対する防御が求められています。ハイブリッド環境のデータ管理は、その複雑さからエラーの発生リスクが高くなるため、より一層の慎重さと確実な管理が必要です。
データファブリックの必要性:統合アーキテクチャの実現
こうしたデータ管理の変化に対応するために、データファブリックの概念が生まれました。データファブリックは、将来の進化を見据えたデータ管理のガイドラインとして、以下のコア要素を組み合わせて構築されます:
共通のアクセスレイヤー
データファブリックは、全てのデータソースとユーザーに共通のアクセス層を提供します。これにより、ユーザーはシステムの複雑さを意識することなく、単一の論理システムとしてデータにアクセスできます。
柔軟なデータ統合戦略
分析用途と運用用途の両方に適した複数のデータ統合戦略を持ち、異なるユースケースに応じてシームレスにデータを使用できるよう設計されています。
セマンティックレイヤー
データ要素の関係や接続を容易に管理し、データの利用や操作をスムーズにするためのセマンティックが追加されています。これにより、異なるデータセット間の相互利用が促進されます。
ガバナンスとセキュリティ
データの信頼性向上のため、全体にわたるガバナンス、文書化、セキュリティ機能が実装されています。これにより、異なるユーザーがデータを使用する際に一貫性が保たれます。
アクティブメタデータとAIによる自動化
アクティブメタデータとAIを用いて、システムの開発・運用・利用プロセスが大幅に簡易化され、自動化が進むことで、効率的かつスピーディなデータ管理が可能となります。
データファブリック導入の意義:現代のデータ管理の複雑さを解消
データファブリックは、複雑なハイブリッドデータ環境におけるデータ管理の混乱を解消し、組織がデータの価値を最大限に活用できるようサポートします。将来的なデータ管理ニーズにも対応できる柔軟性と持続可能性を提供することで、企業全体のデータ活用力を底上げするインフラとしての役割を果たします。
データファブリックの概念とその戦略的意義:Gartnerの定義をもとに
データ管理の進化に伴い、業界のリーディング企業であるGartnerは、データファブリックを次のように定義しています。「デプロイメントプラットフォームやアーキテクチャの手法に依存せず、データオブジェクトの設計、統合、展開を通知および自動化するアーキテクチャパターンである」と述べています。また、Gartnerは、データファブリックが全てのメタデータ資産を活用し、AIや機械学習(ML)の手法を組み合わせることで、データ管理と統合の設計・展開に対する実用的なインサイトと推奨を提供する仕組みを強調しています。その結果、より迅速で豊富な情報に基づく、場合によっては完全に自動化されたデータアクセスと共有が実現可能になります。
データファブリックの最終目標は、ビジネスにおけるデータアクセスやデータ統合のプロセスをアジャイルでシームレスかつ効率的にすることです。高度な分析やインサイトを導き出すための複雑さを内包しつつも、ビジネスユーザーにとっては直感的に操作できるインターフェースを提供することが求められています。成熟したデータファブリックの導入により、企業は高度な分析シナリオから運用シナリオに至るまで、あらゆるビジネスユースケースに対応できるようになります。
戦術的観点からのデータファブリックの役割
Gartnerはまた、データファブリックの核心的な役割について「信頼できるデータをすべてのデータソースからすべてのデータコンシューマに、共通のアクセス層を通じて提供することにより、多様なデータソースを効率的に統合する」と述べています(「Demystifying the Data Fabric」Jacob Orup Lund著、2020年9月)。このような共通レイヤーを介したアプローチにより、データの分散やサイロ化の問題を解消し、企業全体でデータが統合された形で共有される環境を提供します。
データファブリックは、異なるシステム間のデータの橋渡しを行うだけでなく、データの信頼性と一貫性を維持し、ビジネスの俊敏性を高めます。これにより、企業は複雑なデータ環境でも迅速な意思決定を行い、競争優位を維持することが可能になります。データファブリックのアーキテクチャを活用することで、ビジネスは将来にわたり適応可能で、拡張性の高いデータ管理基盤を確立することができます。
データアーキテクチャへの変換:6つの重要なデータファブリックコンポーネント
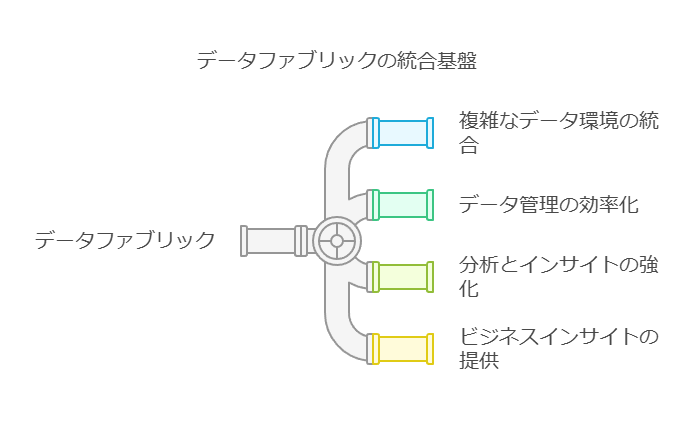
データ管理における次の課題は、これらの理論を実際のデータアーキテクチャにどう反映させるかです。ここでは、機能的なデータファブリックの構築に必要な6つの重要なコンポーネントを説明します。
データ仮想化エンジン
データを抽象化し、アプリケーションやユーザーがデータソースから独立してデータにアクセスできる共通のアクセス層を提供します。特に重要なのは、インテリジェントなクエリオプティマイザを用いて、処理コストを削減しながらパフォーマンスを最適化することです。
拡張データカタログ
データ探索や検索を促進し、ユーザー間のコラボレーションとデータガバナンスを向上させるための中心的な役割を果たします。
アクティブなメタデータ
監査機能と履歴分析を可能にし、さらにAI処理の基盤としても機能します。データの価値を高めるための重要な要素です。
拡張メタデータを含むセマンティックレイヤー
従来の技術的な情報に加え、ビジネス用語やタグ、ステータスなどのメタデータで強化することで、セルフサービスやセキュリティ、ガバナンスの機能をすべてのデータ資産に適用しやすくします。
AIベースの推奨システム
プラットフォーム全体で活用できるAIを活用し、ユーザーの利用状況から学習して開発、運用、パフォーマンス調整を効率化することで、データ管理のライフサイクル全体をサポートします。
DataOpsとマルチクラウドプロビジョニング
複数のクラウド環境でのデータ運用を容易にし、管理・運用コストを削減します。クラウドベンダーに依存しないシステムを確立するために不可欠なコンポーネントです。
これらの要素を揃えることで、効率的かつ柔軟なデータ管理基盤を構築し、ビジネスニーズに迅速に対応できるデータアーキテクチャが実現します。
データファブリックの実装アプローチ:柔軟性を持ったデータ統合の重要性
データファブリックは現代のデータ管理において注目を集めており、複数のベンダーがそれぞれ異なるアプローチを提供しています。その本質は、分散型エコシステムにおいてデータ管理と統合を柔軟に実現することです。これにより、ユースケースや要件に応じて、ユーザーやAIベースの意思決定システムが最適な統合戦略とデータシステムを選択し、効率的に運用できる環境を構築することが可能です。
柔軟なデータ統合手法には、以下のようなさまざまなプロセスやシステムの組み合わせが考えられます:
ETL (抽出、変換、ロード) プロセス
ELT (抽出、ロード、変換) プロセス
リアルタイムフェデレーション
データレイクやエンタープライズデータウェアハウス (EDW) の活用
しかし、一部のベンダー、特にデータレイクやETL分野のベンダーは、データファブリックの本来の柔軟性に欠けるアプローチを提供する場合があります。多くの場合、それは物理的なデータの集中管理に基づいたモノリシックなシステムで、中央リポジトリへのデータのレプリケーションと、パイプラインの自動化に重きを置いたものです。
このようなアプローチには以下のような大きなデメリットが存在します:
ソリューションのロックイン
特定のシステムへの依存度が高まり、柔軟性が制限されるため、データファブリックの進化や変更が難しくなります。特定のベンダーの技術にロックインされることで、ストレージ要件の変更やシステムの改良が制約され、長期的な拡張性に影響を及ぼします。
データファブリックの柔軟性を最大限に生かすためには、こうしたロックインリスクを避け、さまざまなデータソースやプロセスを適切に組み合わせる分散型アプローチが不可欠です。
論理データファブリックの中核要素:データ仮想化の役割と実装の要点
論理データファブリックを効果的に設計するには、中心的な役割を果たすコンポーネント同士がどのように連携して要件を満たすかを理解することが重要です。ここでは、データ仮想化の役割とその主要な構成要素について解説します。
データ仮想化:接続・結合・公開のための中間レイヤー
データ仮想化は、ソースシステムとデータ消費者を繋ぐ中間層で、データの接続、結合、公開を可能にする論理データファブリックの要です。このレイヤーは、データの物理的な場所や構造を抽象化し、ユーザーがデータを透過的に利用できる環境を提供します。
ソースデータへの非依存性
データ仮想化プラットフォームは、様々なデータリポジトリに対して共通のアクセス層を提供し、通信プロトコルやクエリ言語、データフォーマットの違いを上位層から切り離します。これにより、異なるデータソースから「基本ビュー」を生成でき、表形式の構造で標準化されたスキーマを活用することが可能です。仮想化ツールには、データソースごとにアダプタが組み込まれ、ユーザーはデータソースの内部構造を意識することなく、データを統合・活用できます。
ビジネスニーズに応える仮想データモデル
データ仮想化レイヤーでは、抽象化されたオブジェクトを結合し、ビジネス視点でのデータモデルを構築します。これにより、データの構造化や結合、集約、変換が容易になり、データ利用者が求める柔軟なビューを提供できます。また、グラフィカルウィザードや高度なメタデータ管理機能を使うことで、ソース変更の影響分析やバージョン管理を効率的に行い、運用の負担を軽減します。
データ公開コンポーネント:業務アプリケーションへの統一アクセスポイント
データ仮想化レイヤーの最後の重要な構成要素はデータ公開機能です。JDBCやODBC、ADO.NETを介したSQL、またはRESTful APIやGraphQL、GeoJSONといった様々なWebサービスAPIを通じて、標準プロトコルでデータを業務アプリケーションに提供します。これにより、データコンシューマは単一のアクセスポイントから必要なデータにシームレスにアクセスできます。
データアクセスの保護と認証連携
セキュリティ面では、外部のActive Directoryインスタンスやアイデンティティプロバイダーと連携することで、データアクセスを管理・保護します。アクセス権管理を強化しながら、認証の一貫性を保つことで、セキュリティリスクを抑えたデータ利用が実現できます。
これらのコンポーネントが効果的に機能することで、論理データファブリックは組織全体のデータ管理を最適化し、データの迅速なアクセスや統合を可能にします。
データ管理におけるデータプロビジョニングの課題:効率的なデータファブリック戦略の構築
データファブリックの構築にあたり、データプロビジョニングの遅延やモノリシックなアーキテクチャの制約は、迅速な価値実現や運用の最適化において大きな障害となり得ます。以下に、データファブリック導入の際に検討すべき代表的な課題と、それぞれがもたらす影響をまとめます。
1. データプロビジョニングの遅延によるアジリティの低下
データレプリケーションを基盤としたアプローチでは、データ資産を利用可能にするまでのタイムラグが発生しやすく、ビジネスのスピードに追従できないリスクがあります。データプロビジョニングに遅延が生じると、データファブリックの持つ本来のアジリティが損なわれ、価値実現までの時間が延びてしまいます。
2. 単一システムに全ワークロードを統合する際の課題
すべてのワークロードを単一のシステムに集約するアプローチは、一見効率的に思えますが、ユースケースごとに最適化されない可能性があります。たとえば、データレイクやデータウェアハウスをバックエンドとする場合、運用に必要なAPI(例:顧客情報取得)では、期待されるパフォーマンスが出ないことがあります。また、既存の分析システムやドメイン固有のデータマートがある場合、それらを再利用できなくなり、重複したデータ処理が発生します。
3. 高いメンテナンスコストがもたらす運用負荷
レプリケーションベースのデータパイプラインは、維持・更新に多大なコストがかかります。常にメンテナンスが必要な上、進化するデータ要件に合わせてパイプラインの調整が求められます。そのため、モノリシックなアプローチは管理コストが高くなりがちで、効率性が低下します。
データファブリックが目指す分散データと論理アクセスの重要性
データレプリケーションは、データファブリックが提供すべき重要な機能の一つですが、これに過度に依存するのは最適ではありません。データファブリックは、分散型のデータ管理と論理アクセスを組み合わせることで、柔軟かつ統一されたデータアクセスを可能にすることを目指します。
このアプローチは、物理的なデータの移動を最小限に抑えつつ、さまざまなデータソースにわたる論理的な統合を行うことを意味します。これにより、データソースの物理的な配置に関係なく、ユーザーやアプリケーションは必要なデータに迅速かつシームレスにアクセスでき、運用のアジリティとメンテナンスの効率化が期待できます。
効率的なデータファブリック戦略を構築するためには、こうした分散データの概念を踏まえた論理アクセスの実装が重要です。それにより、データファブリックが提供するメリットを最大化し、運用コストやプロビジョニング遅延といった課題を克服することが可能となります。
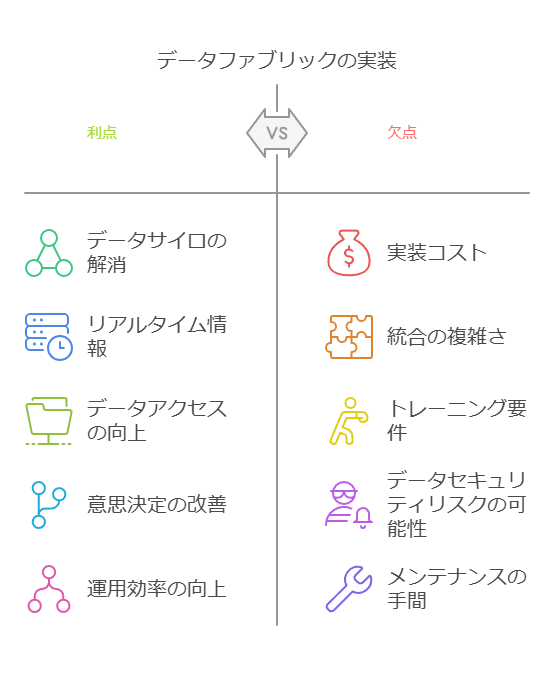
データ管理における分散アーキテクチャと論理データファブリックの重要性
最新のデータエコシステムは、データウェアハウスやデータレイク、運用ストア、NoSQLデータソース、リアルタイムフィードといった多様な要素で構成されています。このように分散型のデータ環境が求められるのは、現代のビジネスニーズに応じた柔軟で迅速なデータ管理を可能にするためです。しかし、どんなデータ管理システムもすべてのユースケースに対応できるわけではなく、ハイブリッドおよびマルチクラウド環境におけるデータ分散の増加に対応した仕組みが必要となります。
論理データファブリックとは:分散データへの効率的アクセスと管理
論理データファブリックでは、データアクセスが論理抽象化レイヤーを通して行われ、複雑なバックエンドの構造をユーザーに意識させません。この論理層によって、セキュリティ、ガバナンス、データ活用のための単一のアクセスポイントが提供されます。また、リアルタイムのフェデレーションや、データセットのキャッシング・集約認識テーブルの作成など、複数のデータ統合戦略を可能にします。論理層の抽象化により、以下のようなメリットが実現されます。
迅速なデータプロビジョニング:初回のレプリケーションなしにデータが即座に利用可能となり、プロビジョニングの遅延を防ぎます。
ベンダーロックインの解消:複数のデータ統合方法に対応することで、特定のベンダーやシステムに依存しないデータ管理が実現します。
運用コストの削減:セマンティックモデリングや高度なメタデータ管理機能を備えることで、運用の効率が向上し、コストが削減されます。
データ仮想化:論理データファブリックの実現を支える技術
分散型データアーキテクチャでは、リアルタイムのデータアクセスが求められます。このため、データ仮想化は、論理データファブリックの中核を担う重要な技術となります。データ仮想化により、物理的なデータの場所や形式に関係なく、異なるデータソースへのアクセスが容易になり、必要なデータをタイムリーに統合・活用できるようになります。
論理データファブリックを効果的に活用するには、高度なデータ仮想化技術を提供できるベンダーの支援が不可欠です。次のセクションでは、論理データファブリックがどのように機能し、どのようにこれらの課題に対応するかについて詳しく掘り下げていきます。
データ検出機能とセマンティックレイヤーの役割:エンタープライズデータ管理の進化
データ検出機能の向上
データカタログの推奨機能は、eコマースやビデオストリーミングプラットフォームでのレコメンデーション機能に似た技術です。ユーザープロファイルや行動パターンを分析することで、データカタログはユーザーが関心を持ちそうなデータセットを推奨できるようになります。この機能は、単なるデータ管理から一歩進んで、利用者の行動に基づいたインテリジェントなデータ探索を可能にするものです。
現在の研究の焦点は、データ検出、データモデリング、セルフチューニングクエリ、および機密データの自動識別など、先進的なデータ管理に関する分野に及んでおり、これらの技術はDenodo Platformの将来のバージョンに組み込まれる予定です。
拡張メタデータを含むセマンティックレイヤー
ユニバーサルセマンティックレイヤーは、データの民主化のための重要な要素です。このレイヤーは、ビジネスユーザーがデータに関する理解を共通にし、効率的なデータ活用を促進します。従来の列名やデータタイプに加えて、次のような意味情報を拡張メタデータとして追加することで、データの有効性とアクセスのしやすさが向上します。
データリネージと変更影響分析:データの依存関係を可視化することで、ユーザーや開発者がデータの履歴や変更の影響を把握できるようになります。
データセット間の関係:複数のデータソースにまたがるデータセットの関係性を表現し、探索やクエリ作成を簡素化します。
文書化とステータスメッセージ:データに関連する説明や運用メッセージを追加することで、ITチームとビジネスユーザー間のコミュニケーションを改善します。
タグとビジネス用語:データ辞書の定義やビジネス用語をタグ付けすることで、標準化されたデータの一貫性を維持します。
機密データの識別:セキュリティ要件に基づいて機密データを識別し、保護します。
統一的なデータメトリクス:企業全体で共通の基準(利益や利ざやなど)を定義し、メトリクスを一元化します。
論理データファブリックとセマンティックレイヤーの連携
拡張メタデータを含むセマンティックレイヤーは、論理データファブリックの各コンポーネントで共有されるべきです。たとえば、データカタログにはステータスやドキュメント情報が表示されるだけでなく、アクセス制御ポリシーの定義にもタグやビジネス用語が使用される必要があります。このように、論理データファブリックは、スマートなコンポーネントの組み合わせによって安全で適切に管理されたセルフサービス機能を提供し、データアクセスとガバナンスを強化します。
この一貫性のあるデータ統合戦略により、データユーザーが必要な情報に迅速かつ確実にアクセスでき、企業全体でのデータ利用が効率的に行える基盤が築かれます。