目次
オブザーバビリティ確立のためのアプリケーションのインストルメンテーション
1. 効率的なインストルメンテーションプロセスの確立
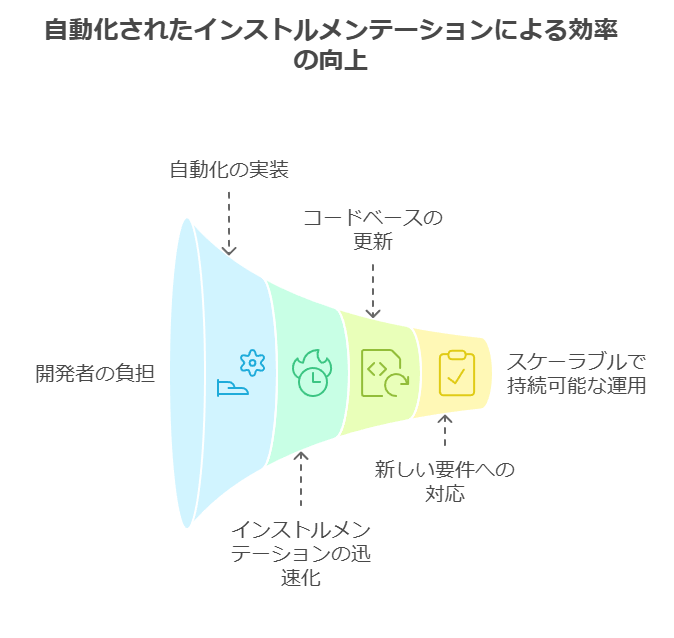
オブザーバビリティを導入する際に重要な要素の一つは、インストルメンテーション(計装)プロセスの効率化です。現代の複雑なシステムにおいて、インストルメンテーションを容易に、かつ迅速に行うことができれば、導入コストと労力を大幅に削減できます。そのため、OpenTelemetryが広く採用されています。
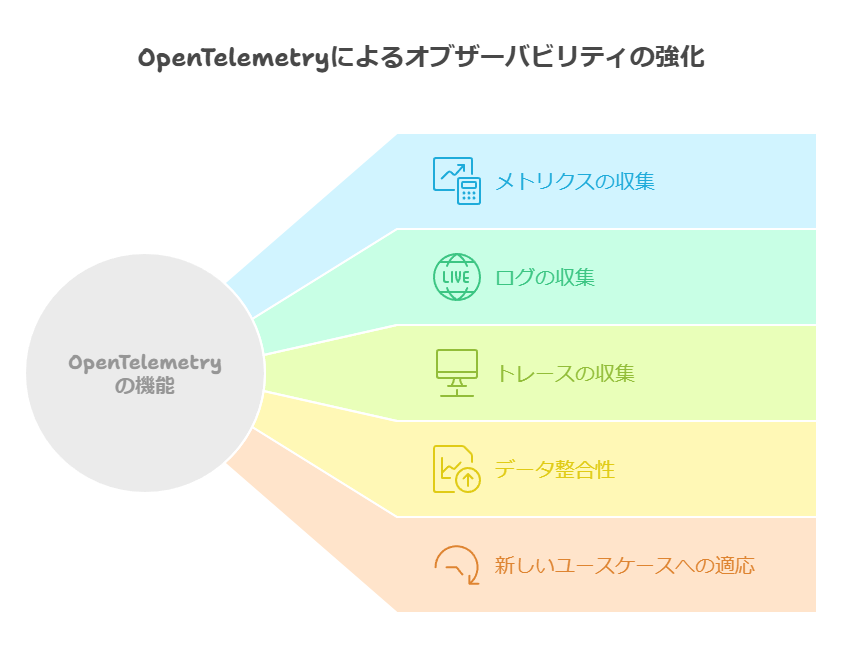
OpenTelemetryは、メトリクス、ログ、トレースの収集を統一された形式で行い、複数のオブザーバビリティプラットフォームにデータを送信する柔軟性を提供します。これにより、異なるツール間でのデータ整合性の問題が解消され、将来的に新しいユースケースやシステム環境に対応する際も、追加の手間を最小限に抑えつつ適応が可能です。
さらに、自動インストルメンテーションのサポートにより、開発者や運用チームの負担を減らし、インストルメンテーションの導入スピードを加速します。特に、既存のコードベースに対して1回のインストルメンテーション作業を行うだけで、今後の新たなモニタリング要件にも対応できるという点は、スケーラビリティと持続可能なオペレーションにおいて非常に重要です。
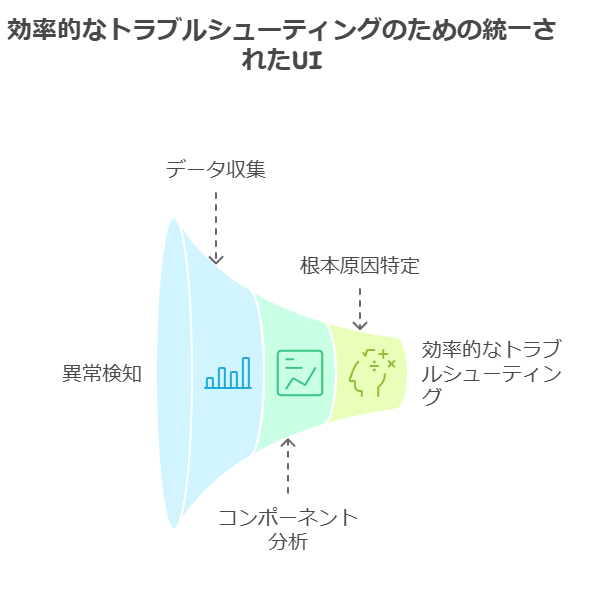
2. 単一の効率的なUIによる的確なトラブルシューティング
オブザーバビリティソリューションの最も大きな利点の一つは、統一されたUIを通じて、効率的にトラブルシューティングが行えることです。分散環境やクラウドネイティブアーキテクチャでは、複数のコンポーネントやサービスが絡み合うため、異常検知から根本原因特定までのプロセスを迅速に進める必要があります。
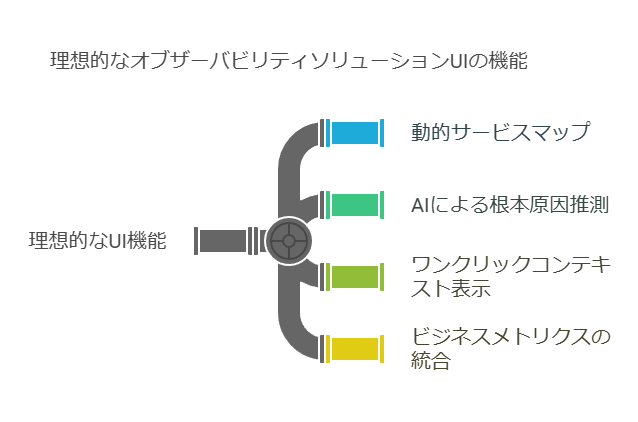
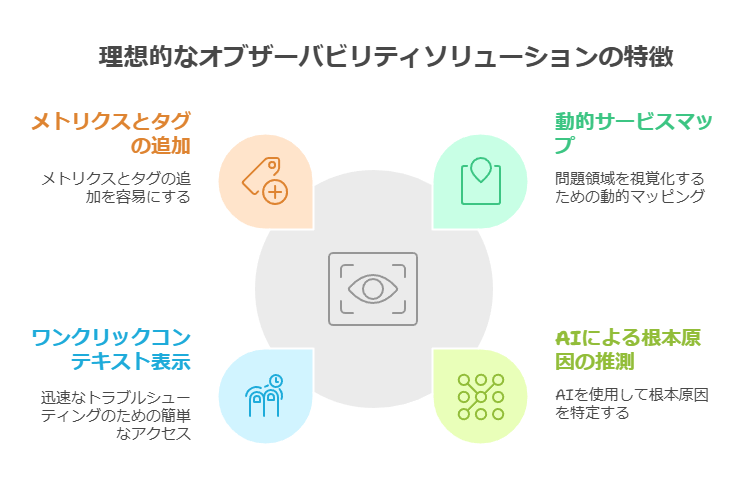
理想的なオブザーバビリティソリューションのUIは、以下の機能を提供するべきです:
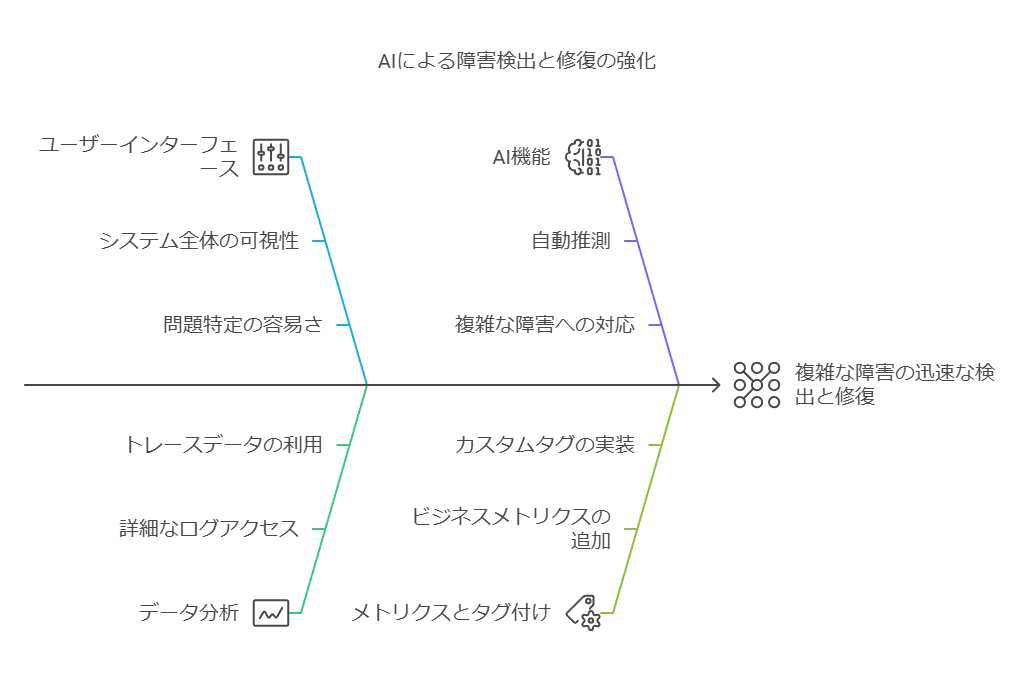
動的なサービスマップによる問題箇所の可視化
AIによる根本原因の推測(異常検知の際に特に有効)
ワンクリックでの詳細なコンテキスト表示(迅速なトラブルシューティングを支援)
ビジネスメトリクスやカスタムタグの簡単な追加機能
これらの機能により、エンジニアは単一のUI上で、システム全体を俯瞰しつつ問題を特定し、詳細なログやトレースデータに基づいて迅速に対応できます。特に、AIを活用した根本原因の自動推測は、複雑な障害が発生した際に、MTTD(平均検出時間)やMTTR(平均修復時間)を短縮するための大きな助けとなります。
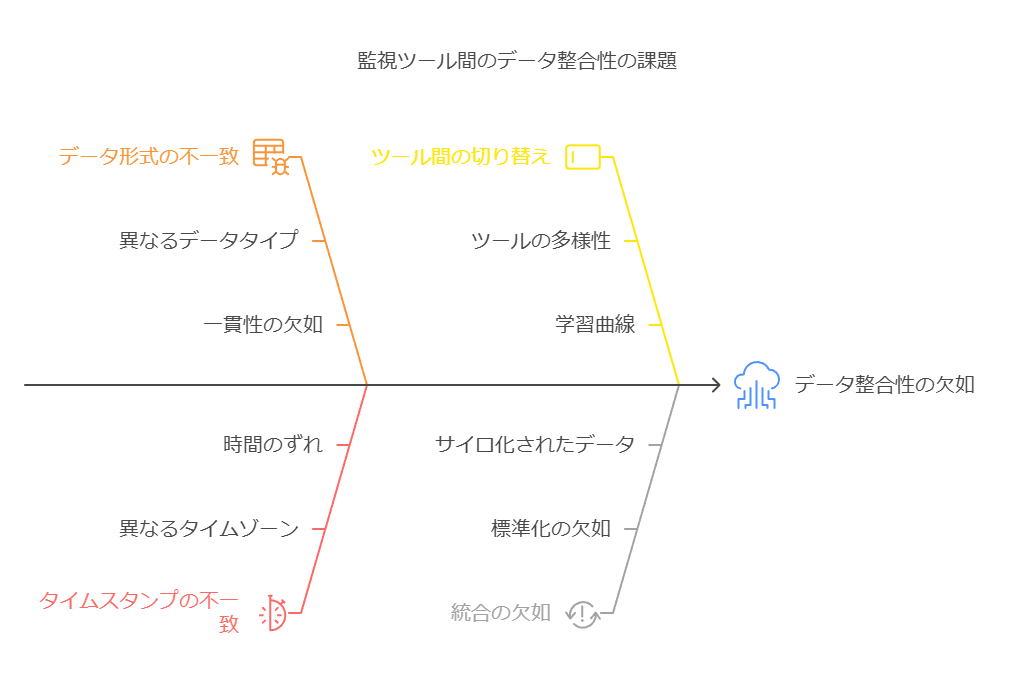
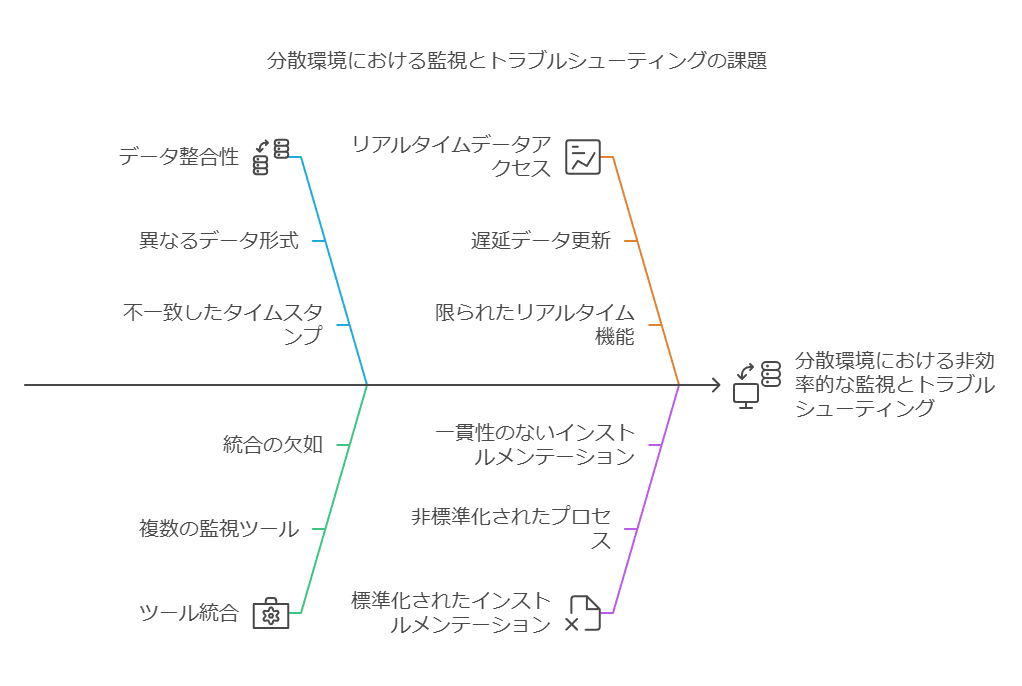
3. ツール間のデータ整合性の課題解決
複数の監視ツールを使用する場合、ツールごとに異なるデータ形式やタイムスタンプに基づいて収集されるため、データの整合性を保つことが課題になります。オブザーバビリティの統合プラットフォームを利用することで、こうしたツール間の切り替えに伴う非効率性やデータの不一致を軽減できます。
OpenTelemetryのような標準化されたインストルメンテーションと統合UIを活用することで、複数の監視ツールを使いながらも、一貫したデータビューを保ちながらシステムを監視し、トラブルシューティングを行うことが可能です。これは、特に大規模な分散環境において、効果的な問題解決に必要なデータ精度とリアルタイム性を確保するための重要なステップとなります。
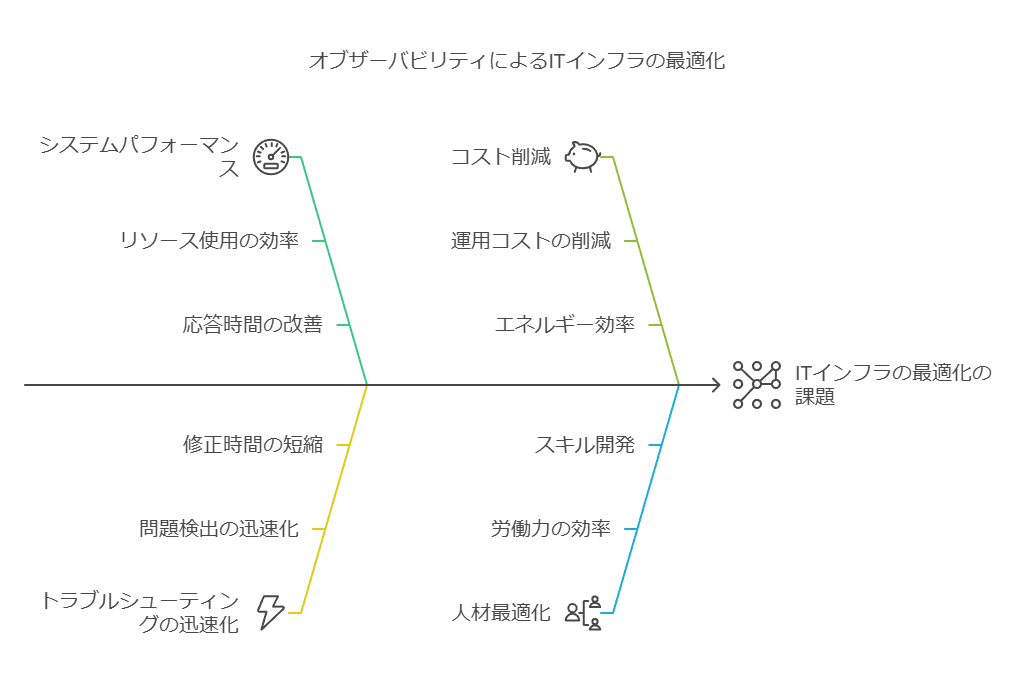
データコンサルタントの視点では、これらのオブザーバビリティのアプローチは、システムのパフォーマンス最適化、トラブルシューティングの迅速化、そしてスケーラブルで柔軟なITインフラ運用に大きな貢献を果たします。特に、自動化と標準化により、長期的なコスト削減や人材リソースの最適化が実現できます。
オブザーバビリティのメリット
1. オブザーバビリティの役割と今日のエンジニアリングプラクティスにおける意義
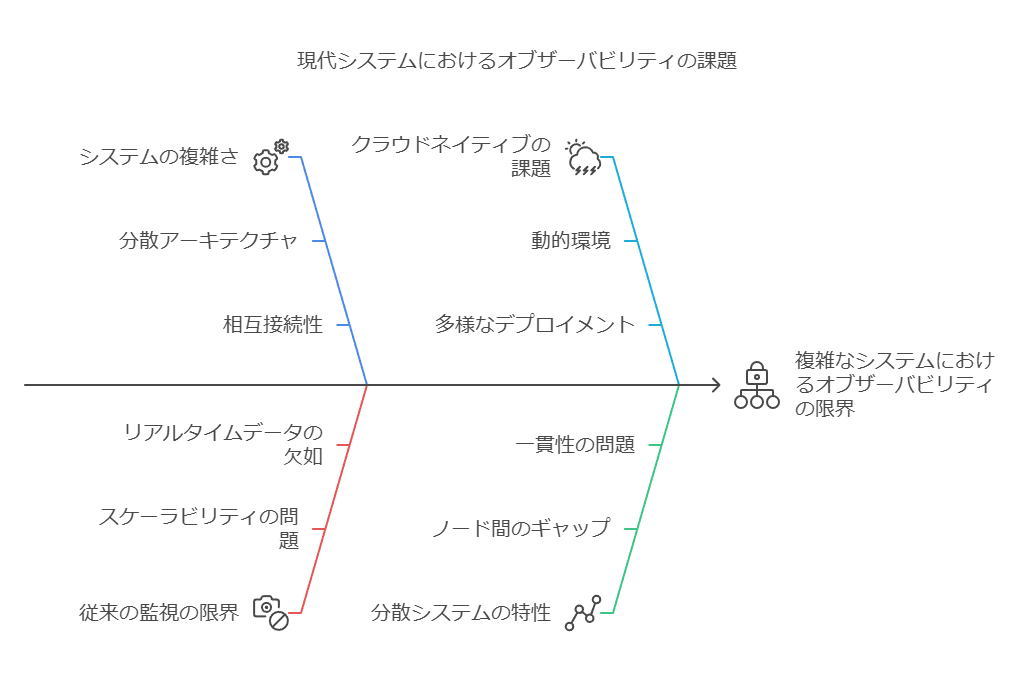
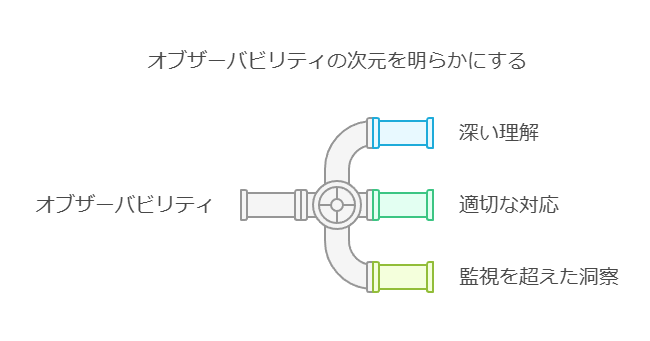
オブザーバビリティは、システムの出力データを基に内部状態を把握し、インサイトを得る能力を指します。現代のエンジニアリング環境、特にクラウドネイティブや分散システムの導入が進む中では、従来の監視手法だけでは対応が難しくなってきています。
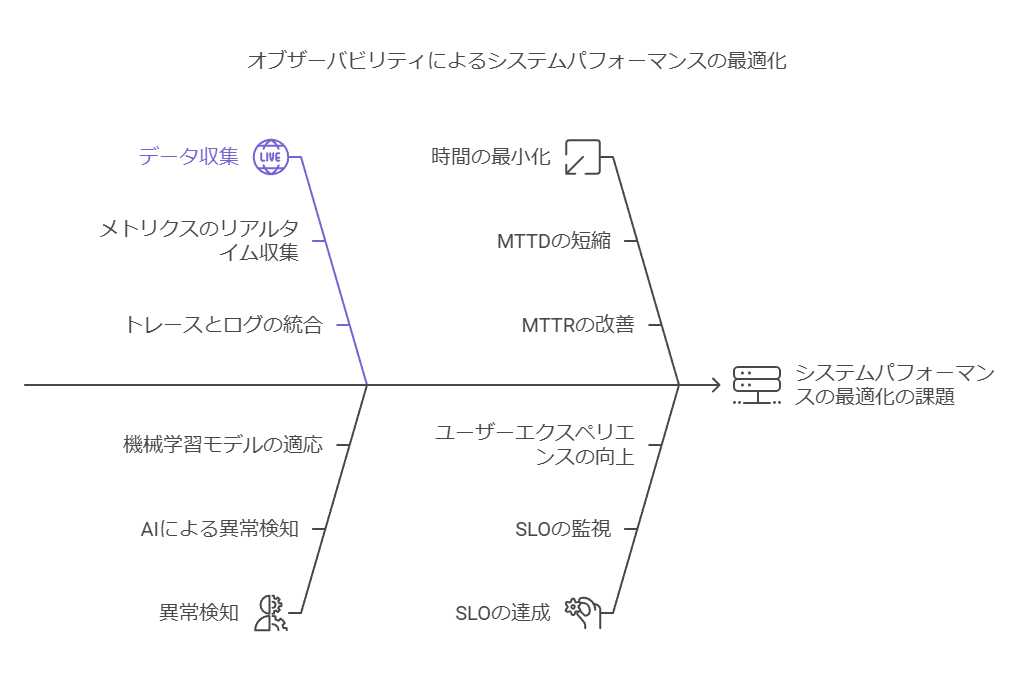
分散アーキテクチャでは、システム全体の状態や問題を把握するのが困難なため、オブザーバビリティによって得られるリアルタイムの可視化とプロアクティブな問題検出が、システムのパフォーマンス最適化に不可欠です。これにより、エンジニアは複雑なインフラを包括的かつ効率的に管理でき、問題の予兆を早期に察知して解決策を迅速に導入することが可能になります。
オブザーバビリティは単なる監視ではなく、システムの内部で何が起きているのかをより深く理解し、適切に対応するための先進的なアプローチです。
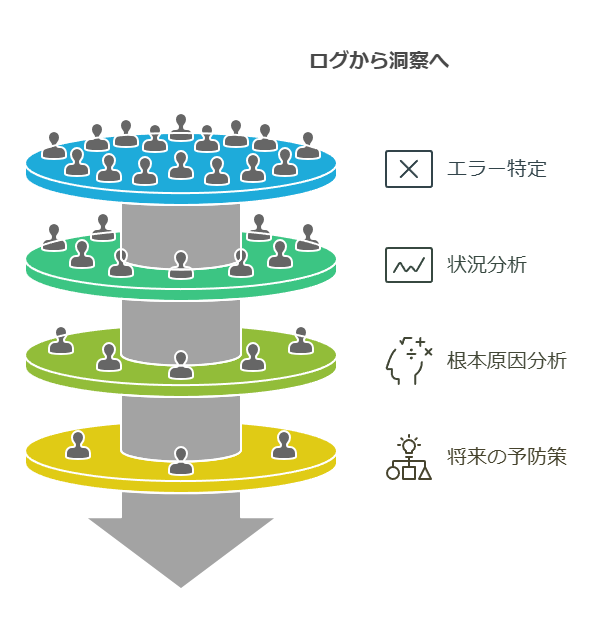
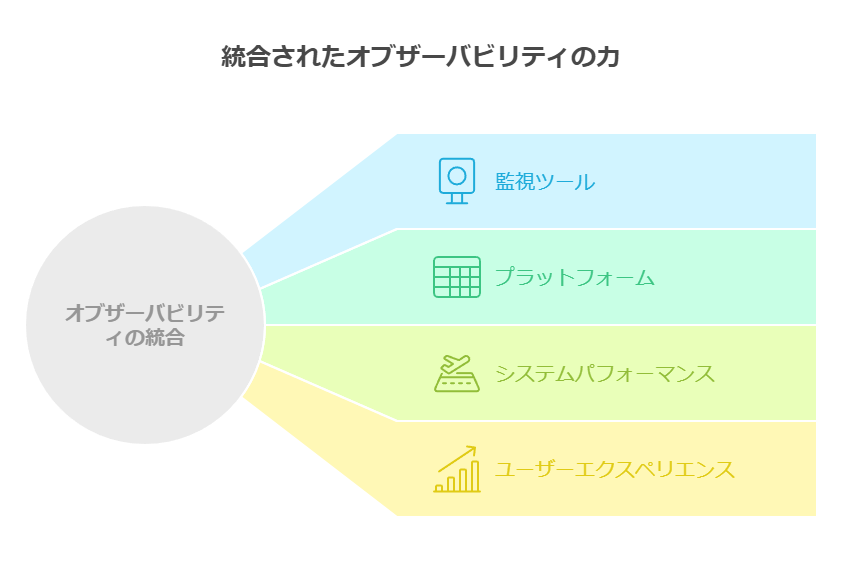
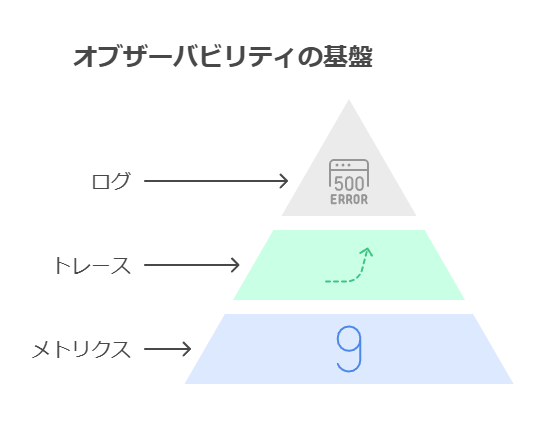
2. オブザーバビリティの3つの重要要素:メトリクス、トレース、ログ
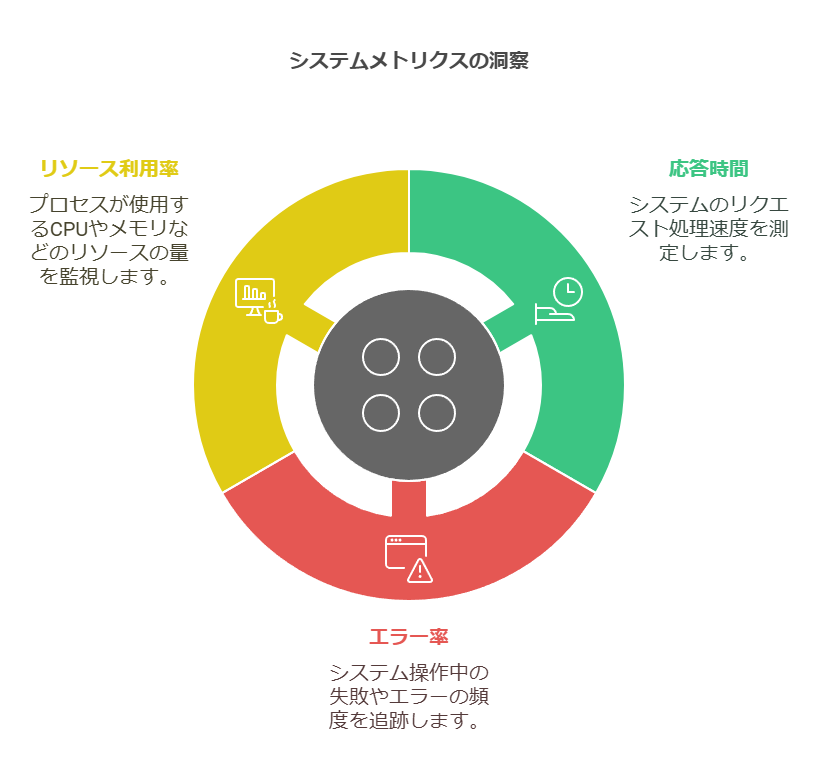
オブザーバビリティの効果的な運用は、メトリクス、トレース、ログという3つの要素に支えられています。この3つが統合されることで、システムの健全性やパフォーマンスを網羅的に理解でき、トラブルシューティングやパフォーマンス改善が迅速に行えます。
メトリクス: メトリクスはシステムの定量的な指標を提供し、応答時間、エラー率、リソース利用率などを測定します。これにより、システムが正常に稼働しているか、またはリソースが過剰に消費されているかなどを把握し、異常なパターンやトレンドを検出できます。
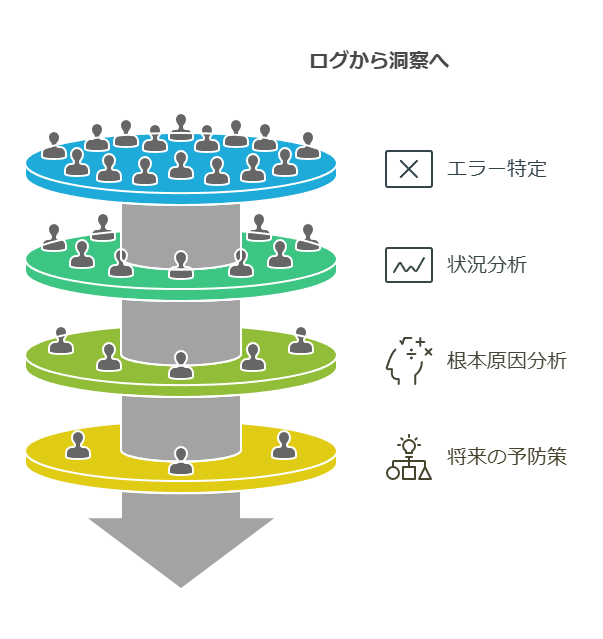
トレース: トレースは、リクエストやトランザクションが複数のサービスを横断して処理される流れを追跡します。これにより、依存関係や処理フローをエンドツーエンドで可視化し、システム内のボトルネックや障害発生ポイントを特定することができます。トレースは、特に複雑なマイクロサービスアーキテクチャにおいて、問題箇所の特定に役立ちます。
ログ: ログは、システムが発生させるイベントやメッセージの詳細な履歴を提供します。ログデータを活用することで、特定のエラーや障害がどのような状況で発生したのかを追跡し、根本原因を明らかにすることが可能です。また、問題の履歴を参照することで、将来的な予防策の策定にも役立ちます。
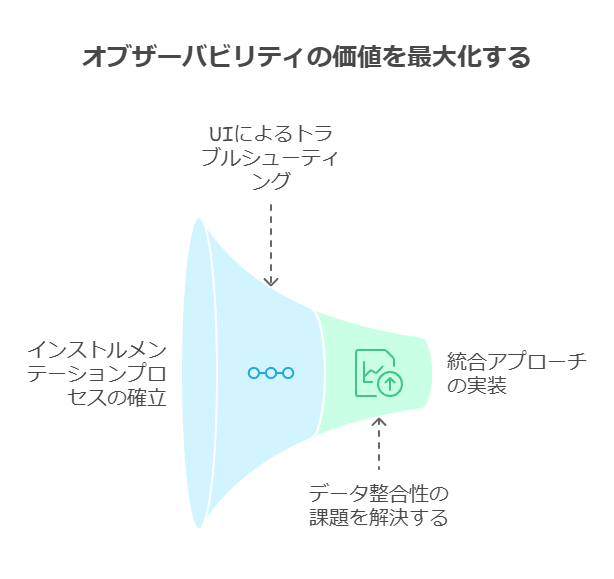
3. オブザーバビリティの価値を最大化するための統合アプローチ
システムの安定運用を支えるために、オブザーバビリティは単一のソリューションとしてではなく、他の監視ツールやプラットフォームと統合的に運用することが重要です。これにより、全体のシステムパフォーマンスとユーザーエクスペリエンスの向上を目指すことができます。
例えば、メトリクス、トレース、ログをリアルタイムで収集・分析し、AIや機械学習を活用して異常検知を自動化することで、平均検出時間(MTTD)と平均解決時間(MTTR)を短縮し、障害の影響を最小限に抑えることが可能です。また、SLO(サービスレベル目標)の達成を維持しつつ、システム全体の最適化を進めることができます。
データコンサルタントとしての視点では、オブザーバビリティは単なる技術的な選択肢ではなく、ビジネスの継続性や効率性を保証するための不可欠な要素です。特に、複雑なインフラ環境において、エンジニアリングチームが迅速かつ的確に対応するためのツールセットとして、オブザーバビリティは極めて価値の高い戦略的投資となります。
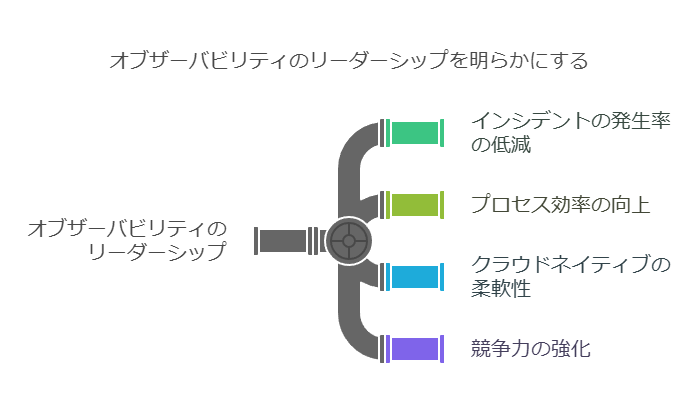
オブザーバビリティの価値は、インシデントの発生率を低減し、組織全体のプロセス効率を向上させることで、業界のリーダー企業が明確な成果を上げていることで証明されています。大規模な従来型組織がクラウドネイティブのスタートアップと同等の柔軟性と競争力を持つためには、オブザーバビリティのリーダー企業が実践している4つの重要な要因に焦点を当て、戦略的に取り組む必要があります。
1. 先を見越して取り組む
オブザーバビリティの取り組みは、システムの複雑性が増大する前に実施することが重要です。ハイブリッドやマルチクラウド環境が複雑化すると、インシデントの発生頻度や影響が増加し、サービス停止による損害が大きくなります。データ分析によると、オブザーバビリティの取り組みが長期間にわたって行われている組織ほど、インシデントの発生率が低く、影響も少ないことが確認されています。
2. 早期に開始し、継続的に最適化する
リーダー企業は、すでに2年以上にわたりオブザーバビリティを重要な優先事項として捉えています。オブザーバビリティの強化には時間がかかるため、今すぐ始めることが重要です。また、これは一度の取り組みで完了するものではなく、ITインフラの拡張や新しいアプリケーションの導入に合わせて継続的に最適化し、オブザーバビリティが適切に機能していることを定期的に確認する必要があります。
3. データ収集と相関分析の優先化
組織全体で生成されるメトリクス、ログ、トレースなどのデータを統合し、サイロ化を解消することが重要です。これにより、すべてのデータソースを可視化し、問題の発見や解決に必要なインサイトを得ることができます。また、柔軟かつオープンなインストルメンテーションツールを導入することが、データ主導の意思決定プロセスを確立するための重要なステップです。
4. 分析力の強化
関連するデータを迅速に特定し、相関付けることで、組織はより正確な意思決定が可能になります。適切なデータ分析を行うことで、チーム全体での共通認識が生まれ、効果的なコラボレーションが促進されます。共通のツールを使用してデータを収集し、相関分析することにより、インシデント対応のスピードが向上し、顧客満足度や収益の向上に寄与することが期待されます。
同じデータ収集・分析ツールを使用することで、チーム間での摩擦を軽減し、より迅速かつ効果的にインシデントへの対応が可能となります。問題をリアルタイムで検知し、即座に対応することで、顧客満足度を向上させ、結果的に収益増加にもつながります。
オブザーバビリティツールの統合戦略
オブザーバビリティ市場は、複数のベンダーを統合した一貫性のあるプラットフォームへとシフトしており、最終的に統合プラットフォームが主流となると予想されます。この過渡期において、組織は最適な可視化とシームレスな連携を実現し、個別のポイントソリューション間での作業コストや時間を削減するツールの選定が重要です。データの一元管理と効率的なモニタリングを可能にする統合戦略は、今後の競争力強化に欠かせません。
オープンソースと商用ツールの選択基準
オープンソースツールは、多くの企業がオブザーバビリティ導入の初期段階で採用する傾向があります。特に、デジタルトランスフォーメーションの初期段階にある組織にとって、低コストで柔軟なソリューションとして有効です。しかし、オブザーバビリティの成熟度が高まるにつれて、より高度な機能や拡張性が求められ、オープンソースでは限界が生じることがあります。組織は、現時点のニーズだけでなく、将来的な成長やスケーラビリティを見据え、オープンソースと商用ツールのバランスを慎重に考慮することが重要です。
ベンダーロックインを避ける柔軟なツール選定
クラウドプロバイダー提供のツールに依存しすぎることは、マルチクラウドやハイブリッド環境での可視化に制限が生じるリスクがあります。そのため、ベンダーに依存しないアーキテクチャを採用し、特にOpenTelemetryのようなオープンソースのインストルメンテーションツールを活用することを検討すべきです。このアプローチにより、異なるクラウドサービス間のデータを統合して監視でき、ベンダーロックインを避けつつ、全体的な投資対効果(ROI)を向上させることが可能です。
複雑さに対応するためのアプローチ
最新のITインフラは複雑さが増し続けており、特にオブザーバビリティの導入初期においては、わかりやすさを優先して本来の機能を犠牲にする選択をしがちです。しかし、成功しているチームは、この複雑さを受け入れ、正面から対応しています。インフラやアプリケーションが抱える本質的な複雑さを単純化しすぎると、重要なインサイトが見逃され、問題の根本原因を見誤る可能性があります。複雑さを適切に理解し、効果的に対処するためのツールとプロセスを導入することが不可欠です。
ベンダー統合の戦略とツール選定において、オープンソースと商用ツールの両方を組み合わせ、柔軟かつ拡張性のあるアプローチが求められます。複雑なインフラ環境に対処するためには、ベンダーロックインを避けつつ、複雑さを克服する戦略的なオブザーバビリティの実践が、競争力を保つための鍵となるでしょう。

オブザーバビリティの成熟度がもたらすビジネス上のメリット
オブザーバビリティの成熟度を向上させることで、組織は2つの大きなメリットを享受できます。まず1つ目は、システム全体の状況をリアルタイムで迅速に把握できるようになることです。これにより、プロアクティブな意思決定が可能になります。2つ目は、問題の検出と解決が高速化され、時には問題が発生する前に未然に防ぐことができる点です。このプロアクティブな対応により、ダウンタイムを最小限に抑え、ビジネス運営を最適化します。
デジタルエクスペリエンスの信頼性向上
調査結果によると、オブザーバビリティの成熟度が高い組織では、現場担当者が提供するデジタルエクスペリエンスに対する自信が顕著に高まっています。これは、システムの可視化レベルが向上し、問題を迅速に特定・解決できるため、顧客に対して安定的かつ高品質なサービスを提供できることに起因します。このような自信は、ユーザー体験の向上と競争力強化に直結します。
可視化と数値ベースの成果
オブザーバビリティの高い成熟度は、単にシステム状況の可視化を超えて、ソフトウェアのパフォーマンスやチーム間の連携強化、さらにはデジタルトランスフォーメーションやイノベーションの推進を定量的に測定できる基盤を提供します。これにより、組織は進捗や課題を数値で把握でき、効果的な戦略立案が可能となります。定量的なデータは意思決定の精度を高め、ビジネス成果の可視化に大きく寄与します。
自信の向上とオブザーバビリティの効果
オブザーバビリティの成熟度が向上するにつれ、現場チームの自信も年々高まっています。調査では、全体的な成果向上が確認されており、特にリーダー的組織においては、アプリケーションの可用性とパフォーマンス要件を満たす能力に対する自信が、ビギナー組織の2倍にも達していることが示されています(71%対35%)。この自信は、安定した運用とサービス品質の改善に直結しています。
パフォーマンスとセキュリティの可視性の格差
リーダー的組織は、アプリケーションパフォーマンスの可視化において66%、セキュリティの可視化において64%の組織が高い可視性を確保しています。一方で、ビギナー組織はそれぞれ44%、42%と、可視性の点で大きな差が見られます。この格差は、組織の成熟度による運用効率やリスク管理能力の違いを明確に示しています。
コードレベルでの可視性
リーダー的組織の58%が、アプリケーションをコードレベルで深く可視化できているのに対し、ビギナー組織では43%にとどまります。コードレベルでの可視化は、パフォーマンスボトルネックやバグの早期発見につながり、リーダー的組織がより迅速かつ精度高く問題を解決できる要因となっています。
コンテナ環境の可視化
コンテナ環境の可視化に関しても、リーダー的組織は64%が高い可視性を確保していますが、ビギナー組織は39%にとどまります。コンテナはマイクロサービスアーキテクチャの重要な要素であり、その可視化が進んでいる組織は、よりスムーズな運用と障害対応が可能です。この可視性の違いは、クラウドネイティブな環境での競争優位性に直結します。
オブザーバビリティの成熟度を高めることで、リアルタイムの可視化やプロアクティブな問題解決能力が向上し、ビジネス上のリスクが低減します。リーダー的組織とビギナー組織の差異は、パフォーマンスの可視性やセキュリティ態勢、コードレベルの監視、コンテナ管理に顕著に表れ、これらが競争力と運用効率の格差を生んでいます。
開発の信頼性とスピードに関するKPIの優位性
オブザーバビリティをリードする組織は、アプリケーション開発におけるスピードと信頼性において、ビギナー組織を圧倒的に上回るパフォーマンスを発揮しています。特に、オンデマンドでの本番環境へのコードデプロイや、障害の迅速な検出能力といったKPIにおいて大きな差が見られます。これにより、リーダー的組織はビジネスクリティカルなシステムの安定運用を実現しています。
コードデプロイの柔軟性
リーダー的組織は、ビギナー組織に比べ、オンデマンドでのコードデプロイの柔軟性において2.1倍の優位性を示しています(59%対28%)。これは、迅速なフィードバックループと自動化されたデプロイメントプロセスを整備することにより、開発サイクルの短縮とビジネス要件への迅速な対応を可能にしています。
問題検出時間の短縮 (MTTD)
リーダー的組織では、自社製アプリケーションの問題を数分以内に検出できる割合がビギナー組織の2.1倍(41%対20%)に達しています。これは、リーダー的組織が高度な監視体制とアラート機能を導入しているため、MTTD(平均検出時間)がビギナー組織よりも約37%短縮され、より迅速な問題対応が可能となっていることを示しています。
デプロイ頻度とダウンタイムの関係
リーダー的組織は、本番環境へのデプロイ頻度が高いにもかかわらず、ビジネスクリティカルなアプリケーションのダウンタイム発生頻度が著しく低いです。64%のリーダー的組織では、ダウンタイムが四半期に1回以下であるのに対し、ビギナー組織ではこの割合が40%に留まります。この差は、リーダー的組織がより成熟したオブザーバビリティと自動化プロセスを活用していることに起因します。
年間ダウンタイム発生数の中央値
リーダー的組織の年間ダウンタイム発生数の中央値はわずか2回であるのに対し、ビギナー組織では6回に達しています。この大きな差は、リーダー的組織がリアルタイムでのモニタリングとプロアクティブな障害対応を活用し、システムの安定性を確保していることを示しています。
問題解決のスピード (MTTR)
リーダー的組織は、ビジネスクリティカルなアプリケーションで発生したダウンタイムや重大なパフォーマンス問題に対して、4時間以内に解決できる割合がビギナー組織の2倍です(53%対27%)。さらに、MTTR(平均修復時間)はリーダー的組織で約69%短縮されており、迅速な問題解決によるシステム安定性の確保が強みとなっています。
オブザーバビリティソリューションによる改善の差異
オブザーバビリティソリューションの導入によっても、リーダー的組織とビギナー組織の間に顕著な差が見られました。リーダー的組織は、より高いレベルでソリューションを活用し、改善を促進しています。
開発とデプロイ時間の短縮、可視性の向上
オブザーバビリティの活用により、リーダー的組織はビギナー組織と比べ、以下のような成果を達成しています。
- 開発時間の短縮:リーダー的組織68%、ビギナー組織57%
- デプロイ時間の短縮:リーダー的組織73%、ビギナー組織62%
- クラウドネイティブおよび従来型アプリケーションの可視性向上:リーダー的組織75%、ビギナー組織58%
これらの改善は、特に複雑なハイブリッドクラウド環境やマルチクラウド環境における運用の最適化に寄与しています。
問題検出と解決の時間短縮
リーダー的組織では、問題検出までの時間を短縮できた割合が75%に達しており、ビギナー組織の65%と比べても優位です。また、問題解決までの時間を短縮した組織もリーダー的組織では73%、ビギナー組織では65%に達しています。これらの短縮は、迅速な対応能力とオペレーショナルエクセレンスの向上に寄与しています。
クラウドネイティブと従来型アプリケーションの可視性の差異
特に注目すべきは、クラウドネイティブおよび従来型アプリケーションの可視性向上において、リーダー的組織とビギナー組織の間に17ポイントもの差が出ていることです(75%対58%)。この可視性の向上は、複雑化するハイブリッドおよびマルチクラウド環境での課題に対処するために不可欠であり、今後さらに多くの組織が、全体環境の可視化と管理の最適化を求められることは間違いありません。
エンジニアリングチームのリーダーはクラウドネイティブ環境の管理に関する新たな課題に直面している
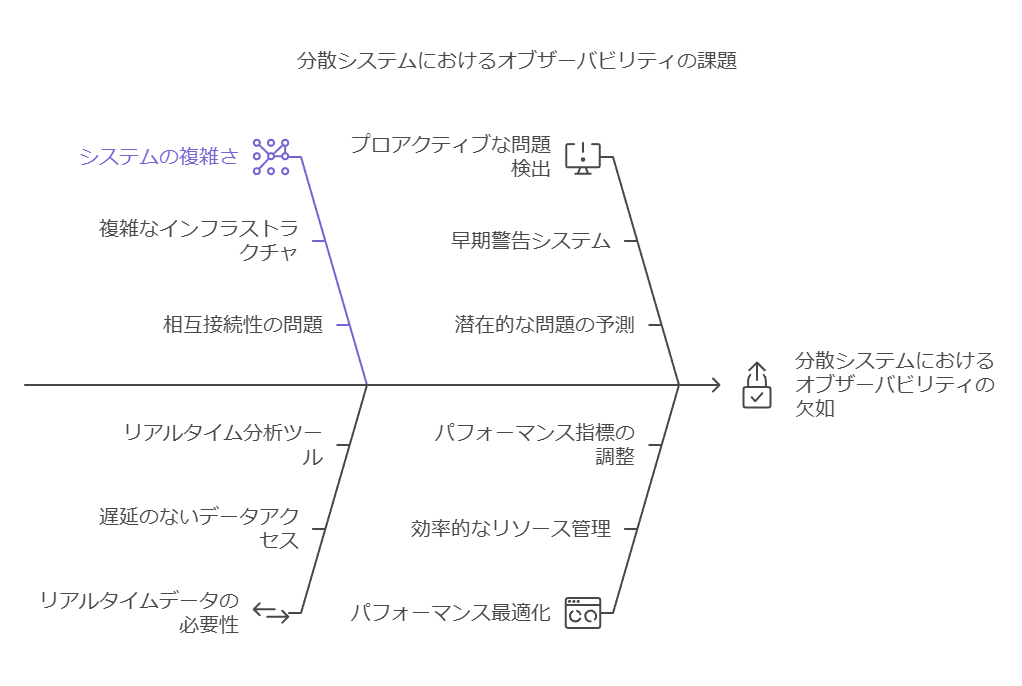
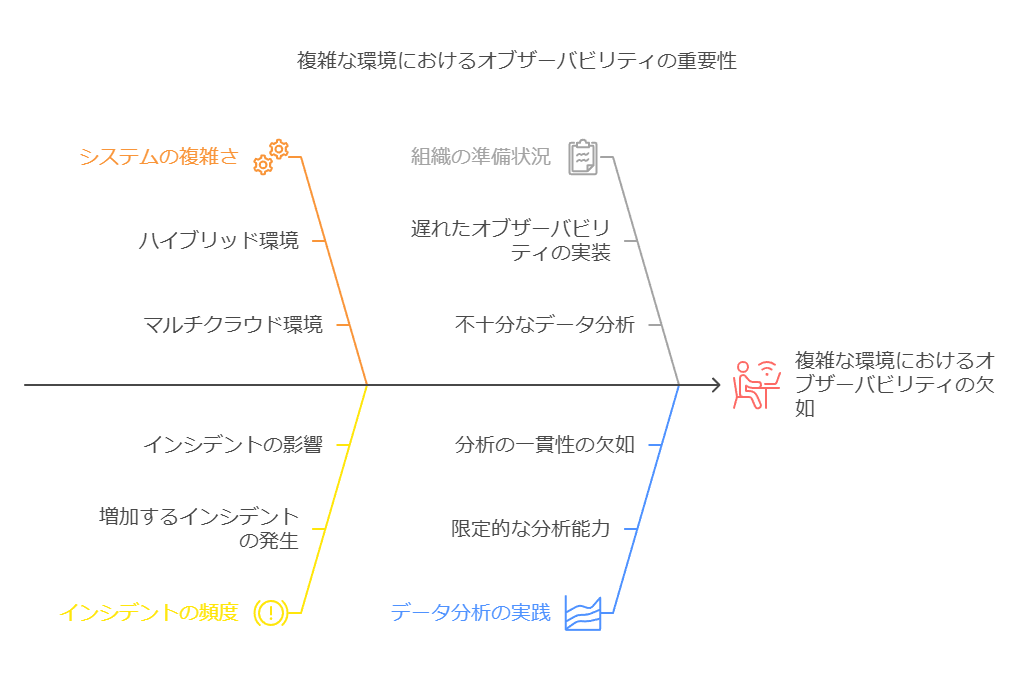
現代のクラウドネイティブ環境では、分散システムの複雑化が急速に進み、エンジニアリングチームに対する要求も高まっています。システムの安定性、拡張性、信頼性の確保を目指しつつ、チームはイノベーションも推進する必要があります。しかし、これらの目標を達成する際、可視性の不足やリソースの最適化、トラブルシューティングの困難さが大きな障害となり、クラウド環境の複雑さが現実的な課題として浮上しています。
システムのセキュリティと信頼性を確保するにはオブザーバビリティプラクティスの導入が欠かせない
クラウドネイティブ環境の安定した運用には、オブザーバビリティ(可観測性)の導入が不可欠です。システムのパフォーマンスや動作をリアルタイムで可視化し、インシデント発生の前兆を捉えることで、トラブルシューティングを迅速化し、情報に基づくデータ駆動型の意思決定が可能になります。これにより、システムの信頼性が高まり、エンジニアリングチームの効率的な運用と持続的な改善文化を醸成することができます。
オブザーバビリティはジャーニーであり、早期の導入が重要
クラウドネイティブ環境が進化する中で、オブザーバビリティの重要性はますます増しています。特にエンジニアリングリーダーにとって、オブザーバビリティは分散システムの複雑性を管理し、最新の技術トレンドに適応するためのツールです。これを導入することで、より効果的に課題を克服し、イノベーションを加速させる基盤を築くことができます。オブザーバビリティは単なる導入ではなく、常に改善とチーム間の協力を求める継続的なプロセス(ジャーニー)です。早期にこの道を歩み始めることが、将来の成功の鍵となります。
RFPでのオブザーバビリティソリューション選定のチェックリスト
以下の要件を満たすオブザーバビリティソリューションを選定することが、クラウドネイティブ環境の最適化に不可欠です。
大量のデータ取り込み、分析、可視化が可能か?
OpenTelemetryベースのインストルメンテーションに対応しているか?
リアルタイムの監視およびアラート機能を備えているか?
拡張性とパフォーマンスが十分か?
分散トレーシングとサービス依存関係の自動マッピング機能があるか?
ログの収集と分析を一元化できるか?
高度な分析とアノマリ検出機能を持っているか?
インシデント対応やインシデント後の分析において、チームのコラボレーションを促進できるか?
既存のシステムと互換性があり、統合可能か?
ビジネス指標、メトリクス、トレース、ログのカスタマイズが可能か?
リアルユーザー監視と外形監視が統合されているか?
クラウドネイティブ環境のためのオブザーバビリティ活用法
クラウドネイティブ環境の複雑さに直面している多くの組織にとって、オブザーバビリティの導入は避けられないステップです。
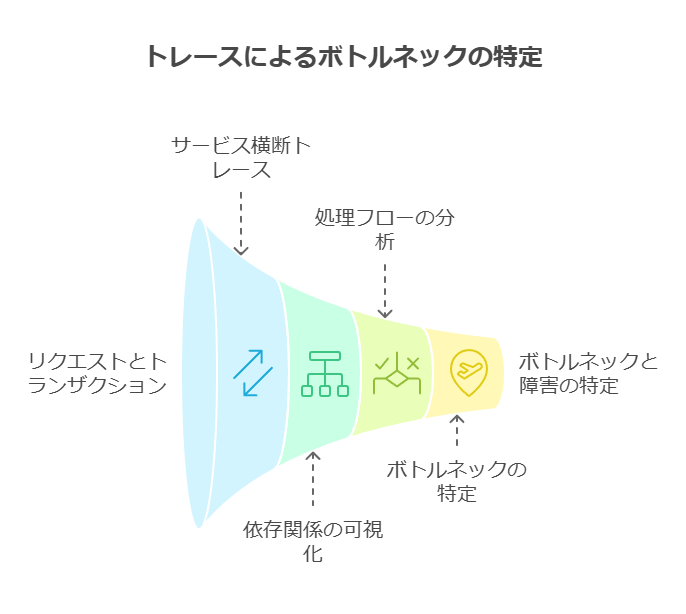
分散トレーシングとサービス依存関係マッピングによる根本原因分析
分散トレーシングは、複雑な分散システムにおける各リクエストの処理フローをエンドツーエンドで可視化するための重要なツールです。複数のサービス間でのリクエストの流れを追跡し、タイミングやコンテキストデータを収集することで、サービス間の依存関係やシステム内のボトルネックを明確に把握できます。これにより、パフォーマンス低下の根本原因を迅速に特定し、適切な対応が可能となります。
サービス依存関係マッピングを活用すると、システムの各サービスの関係が視覚化され、問題発生時の根本原因分析やパフォーマンスの最適化がより正確に行えます。アプリケーションの変更や新サービスのデプロイ、古いサービスの除去に伴う問題も、動的なサービスマップがあれば発生源を迅速に特定し、対応をスピードアップできます。
実例
「大規模なトランザクションエンジンを構築しましたが、システム障害が発生するとトラブルシューティングが非常に困難でした。」
「モノリシックなアーキテクチャからマイクロサービスに移行した際、障害が発生するたびに、問題調査がとても手間がかかる状態でした。」
インシデント対応とインシデント後分析のコラボレーションを促進
最新のオブザーバビリティソリューションは、インシデント対応およびインシデント後の分析において、エンジニアリングチーム間での効果的なコラボレーションを促進します。システムのメトリクス、トレース、ログデータを可視化し、リアルタイムで共有することで、迅速かつ効率的なインシデント対応が可能になります。これにより、共同で問題の根本原因を調査し、効果的な緩和策を実施することができます。
インシデント後の分析では、問題の原因を正確に特定し、その結果から得られた教訓をチーム全体で共有することで、システム全体のレジリエンス(復元力)や信頼性の向上に役立てることができます。これにより、類似の問題の再発を防止し、長期的な運用効率が向上します。
リアルユーザー監視 (RUM) と外形監視によるデジタルエクスペリエンスの最適化
顧客体験を重視する組織が増加する中、RUM(リアルユーザー監視)と外形監視を組み合わせたデジタルエクスペリエンス監視が、エンジニアリングチームにとって非常に有効な手法として注目されています。RUMは、実際のユーザー行動に基づいたエクスペリエンスを測定・可視化することで、顧客に直接影響する問題の検出や迅速な解決に寄与します。
一方、外形監視は、ユーザー体験全体をプロアクティブにテストし、潜在的な問題を顧客に影響が及ぶ前に発見するのに役立ちます。この2つの監視手法を、システムのメトリクス、トレース、ログデータと組み合わせることで、エンドユーザーに影響する問題の優先順位をより効果的に判断し、迅速な解決策を実行することが可能です。
このように、オブザーバビリティは単なる監視ではなく、システムの信頼性やパフォーマンスを維持・向上させるための戦略的なツールです。
ツールの合理化とベンダーの削減で可視性を向上
複数のツールを使用する状況が増えると、システム全体の可視性を確保するのが難しくなります。そこで、ベンダーの統合とツールの合理化により、システム全体の情報共有と可視性の向上を図ることができます。必要なツールに絞ることで、チームへの負担を最小限に抑えながら、最大限のパフォーマンスと可視性を確保できます。
データの調査によると、ツールの統合の余地は多く存在します。すべてのチームが同じ種類のデータに関心を持っているわけではありませんが、セキュリティデータやデジタルエクスペリエンスデータを共有することで、異なる部門間でシステム全体を正確に把握するためのインサイトを提供できるようになります。これは、システム運用の合理化だけでなく、全体的なビジネス成果の向上にもつながります。
ベンダーやツールにおける「最善の組み合わせ」を見つけるための第一歩として、ツール間のギャップを明確化することが重要です。すべてのチームを対象にツールを棚卸しし、各ツールの使用目的やその必要性を把握することで、不要な重複を解消できます。特に、複数のDevOpsチームが異なるツールを使用している場合、ツールセットが無秩序に増加しがちです。不要なギャップや重複を見極めることが、ツールの最適化につながります。
この取り組みは、セキュリティを開発初期段階から組み込むDevSecOpsにも効果的です。多くの組織がDevSecOpsへの移行を進めており、最新の調査(Splunkのセキュリティレポート2022)では、75%の組織がすでに導入しています。この機会を活用して、セキュリティプロセスをさらに強化することを検討すべきです。
オブザーバビリティ成熟度を高めるためのスキル教育
オブザーバビリティの導入は、クラウドサービスの普及と共に進化してきました。特に、クラウドネイティブアプリケーションの拡大に伴い、その重要性は今後も高まり続けるでしょう。オブザーバビリティに成熟した組織は、パブリッククラウドへのアプリケーションデプロイ率が高い傾向にありますが、その割合は依然として50%以下にとどまっています。また、調査によると、92%の組織がマルチクラウドおよびオンプレミス環境で運用を行っています。
このように、システム環境がますます複雑化する中で、オブザーバビリティの成熟をゴールではなく、継続的な取り組みと捉えることが非常に重要です。技術の進化やシステムの複雑さに対応するためには、スキル教育への投資を行い、チームが新しい技術やツールを習得し続けられる環境を整備する必要があります。
オブザーバビリティの継続的な改善を支えるためには、チーム全体のスキルを強化し、リアルタイムのデータ分析や、システム全体の可視性を高めるためのインサイトを提供することが鍵となります。これにより、組織は将来的なシステムの複雑化にも柔軟に対応し、継続的な改善を行うための基盤を築くことができます。
リアルタイム監視の要件に対応する高度なメトリクス処理プラットフォーム
このプラットフォームは、大規模なクラウド環境におけるリアルタイム監視に特化しています。高解像度のダッシュボードとグラフを活用することで、リアルタイムでのデータ操作が可能となり、詳細なトラブルシューティングや根本原因の分析が迅速に行えます。また、動的なしきい値設定や複数の条件・複雑なルールに基づく予測機能により、平均修復時間(MTTR)の短縮が期待できます。
クラウドネイティブアプリケーションに最適化されたパフォーマンス監視とトラブルシューティング
クラウドネイティブのマイクロサービスアーキテクチャに対応した、最先端のアプリケーションパフォーマンス監視ソリューションです。オープンで柔軟なインストルメンテーションやNoSample TMMによる正確なトレーシング、拡張性の高いストリーミングアーキテクチャを利用し、AI駆動のインスタントトラブルシューティングにより、根本原因を迅速に特定することが可能です。これにより、システムの安定性とパフォーマンスが向上します。
コーディング不要でのインサイト取得
このプラットフォームは、クエリ言語に関する知識がなくてもログをコンテキストを維持したまま調査できる機能を提供しています。これにより、DevOpsチームやSREチーム、プラットフォームチームがアプリケーションやクラウドインフラの動作に影響を与えている要因を迅速に理解できるように設計されています。直感的な操作でログ、メトリクス、トレースデータをリアルタイムに相関付け、即座に有用なインサイトを得ることができます。
エンドツーエンドの可視化でユーザーエクスペリエンスを改善
Webブラウザからバックエンドサービスまでの高精度なデータをエンドツーエンドで可視化し、問題をピンポイントで特定して顧客への影響を最小限に抑えることができます。マルチページやシングルページのアプリケーションを問わず、フレームワークに依存せず、ユーザーエクスペリエンスデータを分析可能です。これにより、アプリケーション全体で一貫したパフォーマンスを保証できます。
合成モニタリングによるユーザーエクスペリエンスのさらなる向上
このオブザーバビリティスイートは、高度な合成モニタリングと連携し、アーキテクチャ全体でのトラブルシューティングを強化します。APIやサービスのアップタイム、バックエンドサービスや基盤インフラの健全性を測定することが可能で、これによりプロアクティブにカスタマーエクスペリエンスを向上させます。さらに、API、ブラウザ監視、Web最適化ツールを活用し、ユーザーエクスペリエンス全体をリアルタイムに改善します。
インテリジェントな自動インシデント対応で運用効率を最大化
インテリジェントな自動インシデント対応とコラボレーション機能により、オンコール作業が効率化されます。これにより、インシデント管理を自動化し、過剰なアラートを削減しながら、システムのアップタイムを増やすことが可能です。さらに、適切なアラートを正しい担当者に迅速に届けることで、インシデントの検出から解決までの時間を短縮し、全体的な運用効率が向上します。
このような高度なオブザーバビリティツールを活用することで、企業全体のパフォーマンスが向上し、顧客満足度の向上にも直結することが期待されます。