
目次
データコンサルタントの視点から、データ活用戦略の明確さと技術的側面を強調しました。
1. データファースト戦略の基盤構築
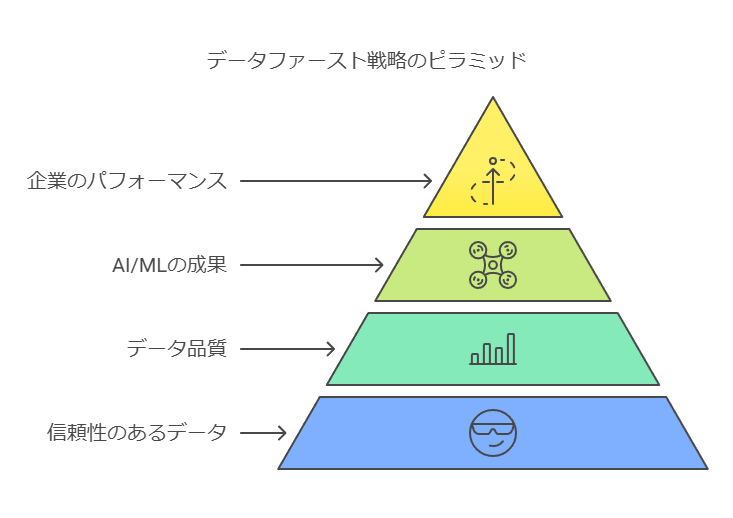
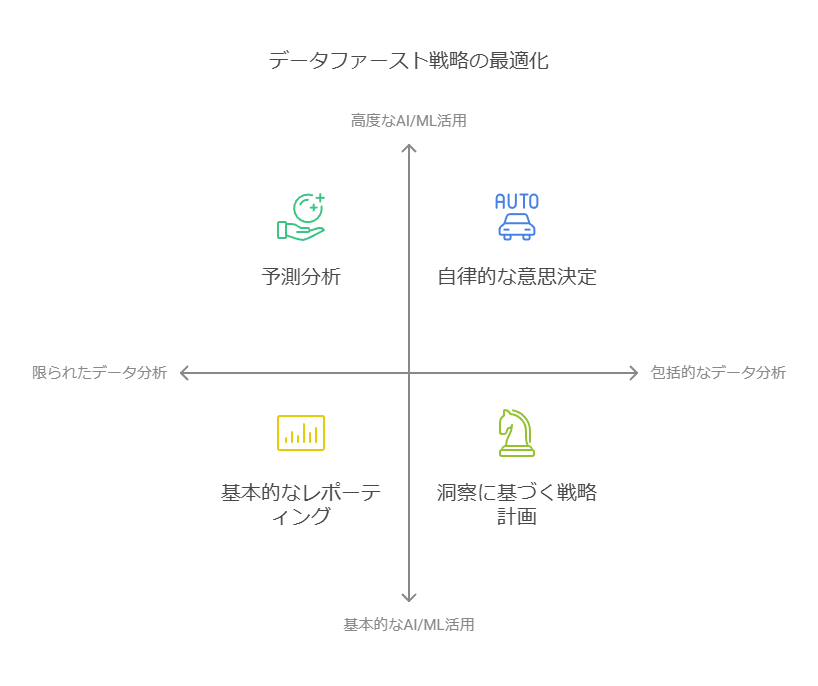
データファースト戦略は、企業がビジネスインサイトを分析し、AI/MLを活用したアプローチを実現するための重要な基盤を提供します。この戦略により、企業はデータ分析とAI/MLインサイトの両方を有効に活用できますが、それぞれの役割には明確な違いがあります。本書では、この違いを整理し、企業が最適なデータ戦略を構築するための指針を提供します。
2. 分析インサイトの役割
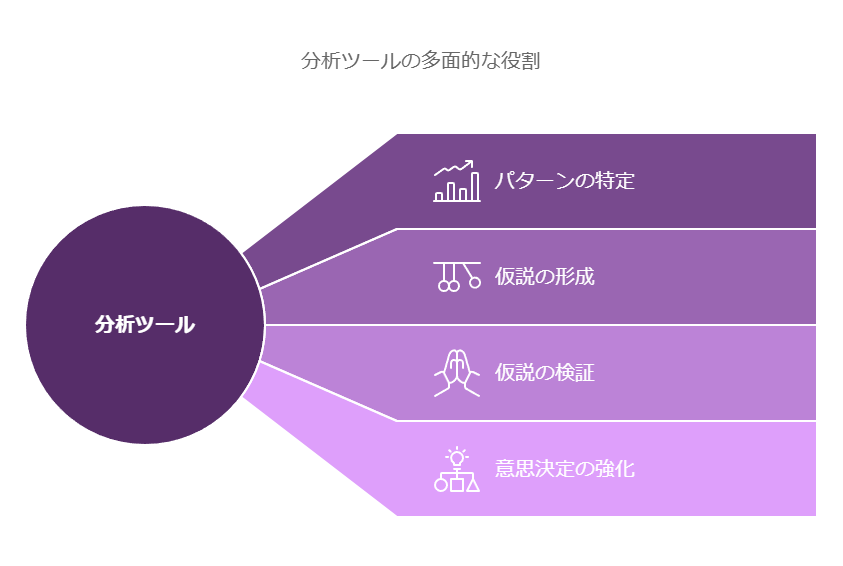
分析ツールは、データセットの中からパターンや関係性を明らかにし、ダッシュボードなどの形式で視覚化することで、企業が「何が起きたのか」を把握する手助けをします。これにより、データサイエンティストやエンジニアが得られたインサイトに基づいて仮説を立て、さらに分析を進めてその仮説を検証します。例えば、製造業では異常を早期に発見し、最適なメンテナンススケジュールを決定することが可能です。多様な分析手法を用いることで、企業は意思決定に役立つ多角的な情報を得ることができます。
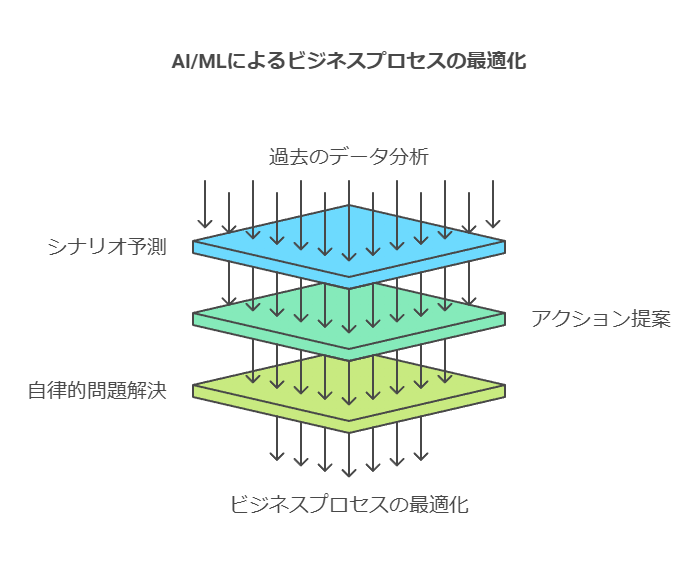
3. AI/MLによる予測と自律的な判断
一方で、AI/MLは自律的な方法でビジネスプロセスを最適化します。AI/MLは、過去のデータだけでなく未来のシナリオを予測し、最適なアクションを提示することで、人間の介入を必要とせずにビジネス課題を解決します。これは、単なる予測を超え、ビジネスに直結する実用的なソリューションを自動的に生成します。たとえば、アメリカ国立気象局はAI/MLを活用し、過去の気象データとリアルタイムの変化を基に、ハリケーンの進行経路を予測するモデルを構築しています。このようなモデルは、自律的にテストと学習を行い続けるため、高品質で信頼性の高いデータセットが不可欠です。
4. データ品質の重要性
AI/MLモデルが高精度かつ自律的に運用されるためには、信頼できるデータが不可欠です。質の高いデータは、AI/MLの予測精度や意思決定の質を左右し、最終的には企業全体のパフォーマンスにも影響を与えます。データの精度と信頼性を確保し、適切に管理・活用することが、データファースト戦略の成功に直結するのです。
ここでは、分析インサイトとAI/MLの違いを明確にし、それぞれがどのように企業の意思決定や業務効率に貢献するかを具体的に示しています。データコンサルタントとして、データの品質や管理の重要性を強調し、技術的な側面とビジネス価値のバランスを意識しています。

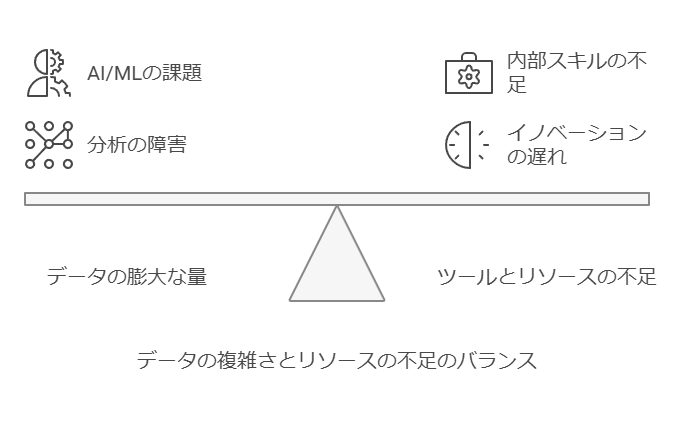
データ活用による競争力向上の課題
データを活用して隠れた有益な情報を引き出せば、企業の競争力は飛躍的に向上します。しかし、データの価値を最大限に引き出すことは容易ではありません。現代の企業は、エッジからクラウドに至るまで膨大なデータを生成していますが、その膨大なデータ量が逆に分析インサイトやAI/MLインサイトの活用を阻害していることが少なくありません。また、データユーザーにはイノベーションを推進するための適切なツールやリソースが不足しており、IT部門も複雑化する分析・AI/MLエコシステムを管理する内部スキルやリソースが十分ではない状況です。
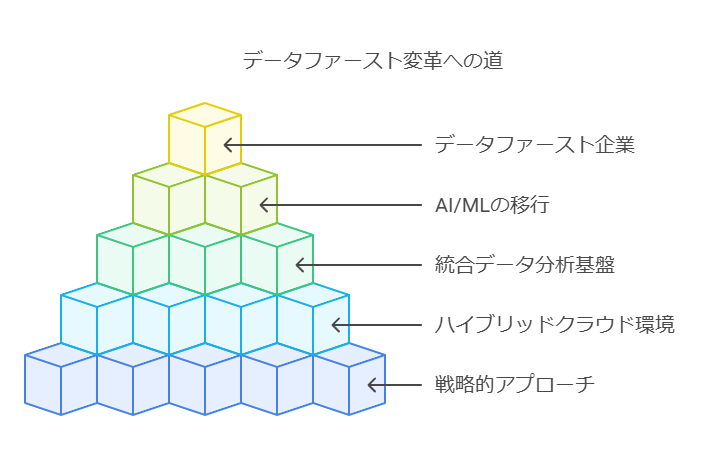
データファースト戦略の重要性
こうした課題に対応するために、お客様企業のデータファースト変革を推進する戦略を策定しました。データの活用を阻む課題であるデータ、リソース、人員、プロセス、そしてテクノロジーに対する戦略的なアプローチを提供し、ハイブリッドクラウド環境でAI/MLや分析ワークロードをスムーズに運用できるようサポートします。ソリューションを活用することで、統合データ分析基盤の構築や、AI/MLのパイロットから本稼働への移行といった重要なマイルストーンを達成し、データファースト企業へと進化する道筋を明確に描くことが可能です。
分析とAI/MLを組み合わせたビジネス推進
データファーストモダナイゼーション戦略は、企業が分析インサイトとAI/ML主導のインサイトを同時に引き出し、ビジネスの成長を促進するために大きな力を発揮します。分析ツールとAI/MLは同じデータを異なるアプローチで活用し、ビジネスプロセスを支援しますが、使用する技術は企業のビジネス成果の目標やチームのスキルセットに応じて異なります。ある企業はAI/ML導入の初期段階で高度な分析を駆使し、他の企業はデータパイプラインを整備しつつ、AI/MLモデルのスケールアップに備えます。
適切な技術選定とコスト最適化
どのフェーズにあっても、技術選定や導入においては不要な支出や最適でない方法を避けることが重要です。こうした複雑な意思決定を支援し、データ、リソース、人員、プロセス、テクノロジーの課題を明確に把握することで、データファースト戦略を成功に導きます。具体的には、統合データ分析基盤の確立とプラットフォーム戦略の策定、フレキシブルな消費オプションを活用したAI/MLのパイロットから本稼働へのスムーズな移行をサポートします。
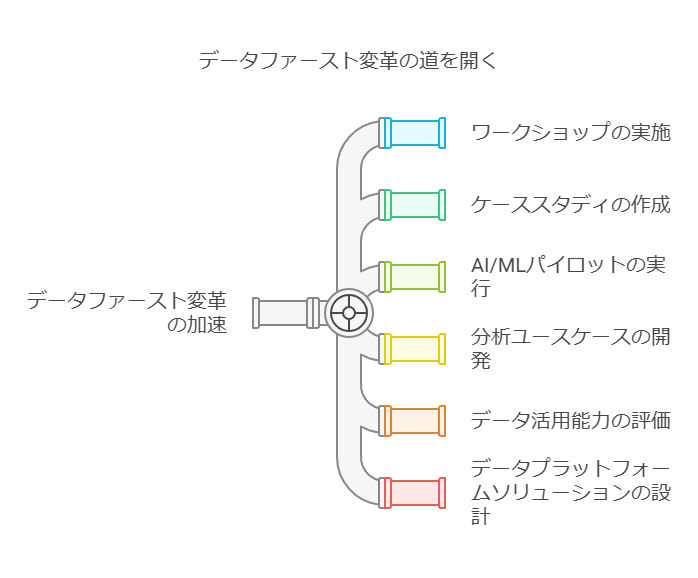
データファーストジャーニーの加速
企業がデータファーストの変革を加速させるために、ワークショップやケーススタディ作成、AI/MLパイロット運用の迅速な実行、分析ユースケースの開発、データ活用能力の評価、データプラットフォームソリューションと消費オプションの設計などを通じて、お客様がそれぞれのニーズに応じた最適なロードマップを描けるよう支援します。これにより、企業は内部の主要関係者の足並みを揃え、効果的なデータ戦略を推進できるようになります。
ここでは、データの価値を最大限に引き出すための戦略的な取り組みを強調しつつ、技術的な詳細とビジネスインパクトを明確にしています。データコンサルタントとしての視点から、導入の具体的なフェーズやリソース配分、技術選定の重要性を示し、企業が直面する課題をどう解決できるかを提案しています。

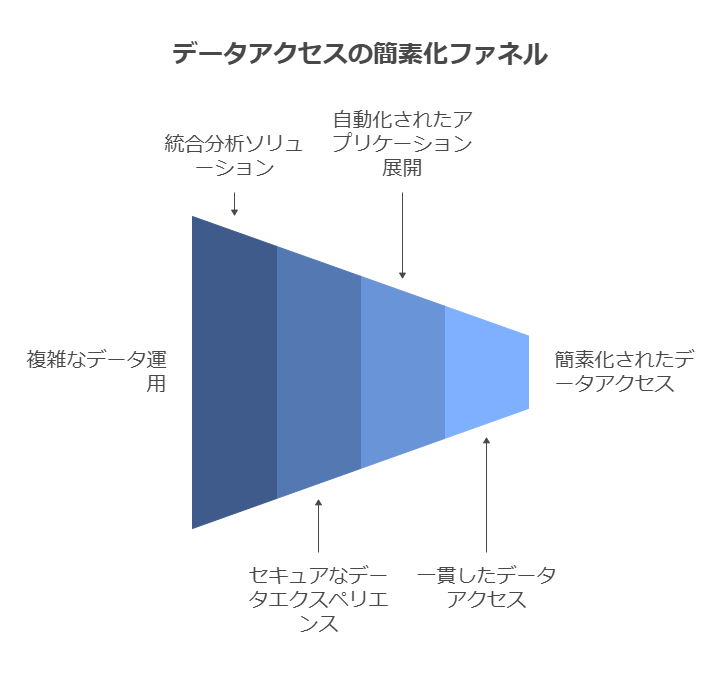
データファーストモダナイゼーションによる懸念の解消
データファーストモダナイゼーション戦略は、統合分析ソリューションを通じて、企業が直面する複雑なデータ運用の懸念を効果的に解消します。シンプルで一元化されたセキュアなデータエクスペリエンスを提供し、あらゆるプラットフォームへのアプリケーションの展開や移行を自動化とオーケストレーションをベースにサポートします。このアプローチは、すべてのデータを単一のプラットフォームに統合するのではなく、異なる環境間で一貫性を持たせたデータアクセスのパターンを提供し、アクセスを簡素化、標準化、自動化します。
このソリューションにより、各ユーザーは自動化された接続を介してバックエンドシステムにアクセスでき、データの局所性やガバナンス、コンプライアンスを遵守しつつ、必要なデータに安全にアクセスすることが可能となります。
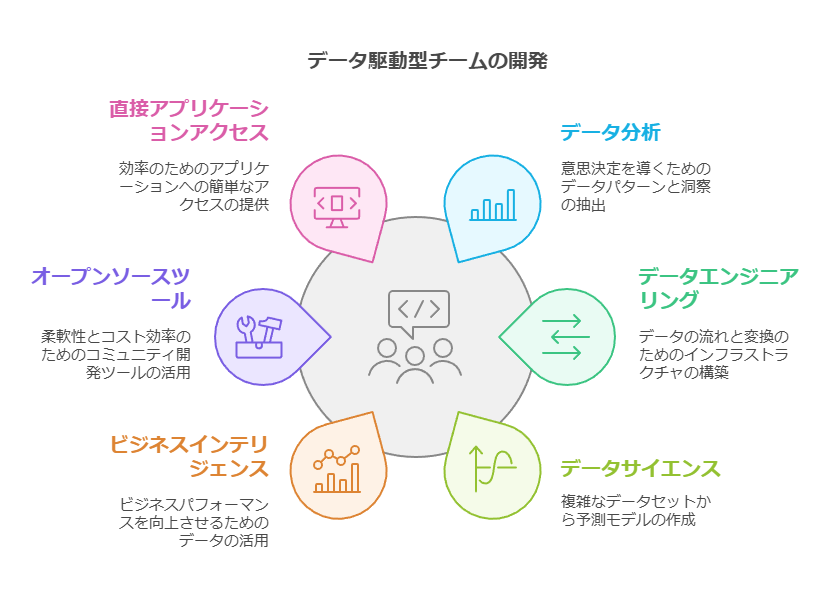
データチームの開発支援
データ分析、データエンジニアリング、データサイエンス、ビジネスインテリジェンス(BI)チームの開発を加速するための強力なサポートを提供します。ソリューションは、さまざまなデータタイプだけでなく、オープンソースツールやフレームワーク、アプリケーションへの直接アクセスも可能にします。これにより、各ユーザーはセルフサービスでBIレポート、分析、AI/MLソリューションを迅速に作成できる専用のエクスペリエンスやライブラリを利用できます。
さらに、事前構成済みのテンプレート、アプリケーションストア、データモデルの構築やパイプラインの運用を加速するための認定ISVソリューションも提供され、データ活用の効率が大幅に向上します。
独自仕様のソリューションからオープンソースへの移行
独自仕様のソリューションによる技術的負債や将来的な制約に対する懸念に関しては、アドバイザーが適切なテクノロジー選定をサポートします。独自仕様のツールやシステムをオープンソースのツールやアプリケーション、ライブラリ、フレームワークに置き換えることで、技術的な足かせを回避します。
これにより、お客様はアプリケーションの再フォーマットや書き換えを行わずに、ワークロードを柔軟に異なるインフラやクラウド環境へ移行することが可能です。この柔軟性は、業界標準APIのサポートによって実現され、将来的な拡張や変化に対応可能な基盤を構築します。
総括
データファーストモダナイゼーション戦略は、企業が直面する複雑なデータ運用課題を解決し、データアクセスや分析を効率的かつ安全に実行できる環境を提供します。また、独自仕様からオープンソースへの移行を支援し、柔軟性とスケーラビリティを兼ね備えたデータ運用基盤の構築をサポートします。これにより、ビジネスの俊敏性を高め、長期的な成功へと導きます。
ここでは、データの運用課題に対して具体的なソリューションを提示し、サポートがどのようにビジネス価値を向上させるかを強調しています。
アジャイルなオープンソース環境の確立による生産性向上
アジャイルでオープンな環境を導入することにより、データチームと分析チームはセルフサービスでツールへのアクセスが可能となり、アプリケーション開発や分析のスピードが大幅に向上します。これにより、各チームは新たなツールの学習に費やす時間を最小限に抑え、迅速に業務に取り組むことができ、ビジネスに有益なインサイトをより早く得ることが可能となります。
統合分析ソリューションは、従来の独自仕様のソリューションに伴う制約を排除し、クラウドに匹敵するシンプルで柔軟なユーザーエクスペリエンスを提供します。アプローチは、特定のクラウドプラットフォームへのデータ移行や、独自ツールの強制使用によってイノベーションを遅らせることはありません。データファーストモダナイゼーション戦略では、自由に選択できる展開環境やツールの活用により、ビジネスに有益なインサイトを得るまでの時間を短縮し、データドリブンな意思決定を加速させることが可能です。
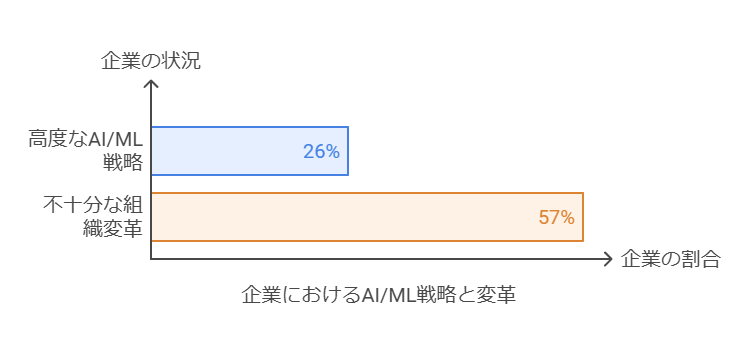
AI/MLパイロットから本稼働へのスムーズな移行
今日、多くの企業が何らかの形でAI/MLを導入していますが、そのうち進んだAI/ML戦略を実行している企業はわずか約3割程度に過ぎません。また、AI/MLを使用している企業の57%は、期待されている組織の変革がまだ十分に実現されていないと報告しています。
サポートにより、AI/MLのパイロット運用から本稼働への移行はスムーズに行えます。私たちは、既存のAI/MLワークフローを効率的に拡張するためのツールとプラットフォームを提供し、IT部門、データチーム、開発者が最大限のパフォーマンスを発揮できる環境を整えます。このプロセスを通じて、各組織のAI/ML導入を最適化し、より広範なビジネス成果と競争優位性の向上を実現します。
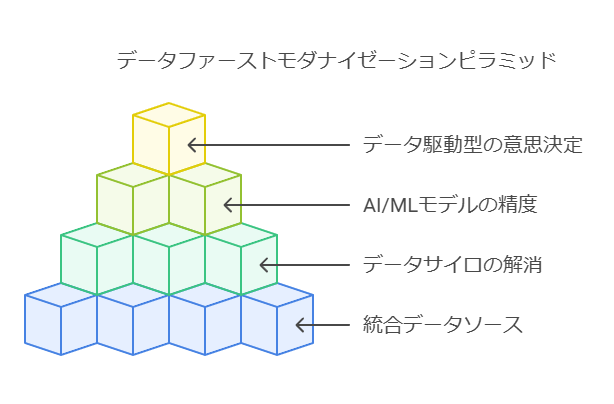
統合データソースの構築とデータファーストジャーニーの加速
データファーストモダナイゼーション戦略により、AI/ML主導のインサイトを得るための統合データソースの構築が可能です。このアプローチにより、データサイロの解消やデータの一元管理が促進され、AI/MLモデルの精度と効率が向上します。また、戦略は、企業のデータファーストジャーニーを加速させ、データ駆動型の意思決定を支えるインフラを強化します。
これにより、データ活用の範囲を広げ、各チームが独自のデータニーズに応じて柔軟に対応できる環境を提供し、ビジネスに必要なインサイトを迅速に得ることが可能です。
ここではリューションが提供する柔軟性と効率性を強調し、企業のAI/ML導入を具体的にどのようにサポートするかに焦点を当てています。また、AI/MLのパイロットから本稼働への移行をスムーズに進めるためのプロセスを強調しています。


エッジとは何か?
エッジとは、データが生成され、その場で処理や意思決定が行われる場所を指します。エッジは特定のデバイスや場所に限定されるものではなく、次のような多様な環境で見られます。
工場の製造現場
建物の屋上や施設
屋外の携帯電話通信基地局
農場の納屋
自律走行車
石油やガスの掘削プラットフォーム
エッジはネットワークの外側に位置し、データソースに最も近い場所です。ただし、企業やクラウドのデータセンターからは数百〜数千マイル離れていることもあります。エッジは、リアルタイムでデータに基づいた意思決定が求められる場所です。
エッジでのデータ処理
エッジでは、デバイスが大量のデータを生成し、そこにはデータ取得や処理に関する独自の課題が発生します。すべてのデータが必要なわけではなく、エッジアプリケーションだけが一時的なデータと重要なデータを区別する能力を持っています。このため、エッジにおける多くの意思決定は、データが生成された場所に近いところで行われることが多いです。
最新のデータ管理およびインジェストアプリケーションを活用することで、AI(人工知能)やML(機械学習)を用いて、データ処理の判断を自動化できます。これにより、機密データ(個人情報、医療情報、クレジットカード情報など)を自動的に識別し、適切にマスク処理を行うことで、データ漏洩や不正アクセスのリスクを低減します。
コンサルタントとしての視点
エッジ環境でのデータ処理は、従来の中央集権型システムとは異なり、分散されたリアルタイムの意思決定が求められます。データ量が増加し続ける現代において、エッジでの効率的なデータ管理と処理は、企業の競争優位性を強化する重要な要素となります。エッジ戦略を活用することで、クライアントは必要なデータを迅速に処理し、AIやMLによる自動化を実現しつつ、セキュリティやコンプライアンスも確保することが可能です。
エッジは単なる場所ではなく、ビジネスインテリジェンスや迅速な意思決定の中心となるデジタル革新のフロンティアです。企業がデジタル変革を進める中で、エッジの役割は今後ますます重要性を増していくでしょう。
エッジ現状分析と課題:
多くの企業が、業界固有のユースケースに合わせて独自にデータプラットフォームを構築し、AI/MLソリューションを展開しています。この流れは自然なことですが、AI/MLの専門知識を持つリソースを確保したり、適切なパートナーを見つけることが大きな課題となっています。実際に、組織の約6割程度が、AI/MLの導入時に「専門知識不足」と「ROI(投資対効果)の測定」を主要な障壁として挙げています。
このような課題を乗り越え、AI/ML導入によって確実に成果を得るためには、適切な専門知識と最適化されたインフラの両方が不可欠です。
ソリューション提案:
そこで、パートナーは、モデルトレーニングや開発ソフトウェアと、ハイパフォーマンスコンピューティング(HPC)を統合したAI/ML向けインフラを提供します。これは、即時に導入可能なターンキーソリューションであり、初日からモデルのトレーニングと開発に対応できるよう設計されています。このソリューションには、エキスパートによるサポートとインストールサービスが含まれており、企業のAI/ML開発を加速させます。
さらに、分散トレーニングなどの高度な機能が標準で搭載されているため、コードの書き換えやインフラの再構成を行わずに、GPUクラスター全体で効率的にMLを実行できます。また、ハイパーパラメーターの自動最適化機能を使用することで、短期間で精度の高いモデルを自動的に発見し、トレーニングが可能です。
ビジネス成果への連携:
このような柔軟でスケーラブルなアーキテクチャにより、企業はAI/MLモデルの精度を最大化し、バイアスを最小限に抑えつつ、ビジネスニーズに応じて規模を拡大できます。さらに、フレキシブルな消費モデルを活用することで、スーパーコンピューティング並みのスピードでAI/MLソリューションを実行し、データファーストモダナイゼーション戦略とAI/ML開発をシームレスに統合できます。
モデル精度向上とデータプライバシーの課題:
AI/MLモデルの精度は、概念実証(POC)から商用段階へ移行する価値を持つか否かの重要な要素です。モデルの精度は、トレーニングに使用するデータの質に大きく左右されます。しかし、多くの場合、データプライバシーや所有権に関する規制やポリシーが質の高いデータの活用を制約することがあります。
また、集中型のAI/MLトレーニングモデルでは、データの移動や複製が大量に発生し、それがシステム効率を低下させる原因にもなります。その結果、モデルに使用できるデータの質が低下し、トレーニングが非効率になるリスクがあります。
結論:
AI/MLインフラとソリューションは、これらの課題を解決するための柔軟でスケーラブルなアプローチを提供します。企業はこのインフラを活用することで、AI/MLモデルの精度を向上させ、バイアスを最小限に抑え、ビジネス目標を達成するための効率的なAI/ML運用を実現できます。

データファーストモダナイゼーションによる分散型AI/MLアプローチ
データファーストモダナイゼーションのアプローチでは、データが生成されるソースで直接MLモデルをトレーニングする、分散型のフレームワークを導入することで、AI/MLモデルの精度向上とバイアス削減を実現します。このアプローチにより、データプライバシーや所有権に関する規制に違反することなく、分散されたデータやサイロ化されたデータにアクセスできるため、法規制への準拠を維持しながら効果的にAIを活用することが可能です。
さらに、データソースでトレーニングを実施することで、転送されるデータはrawデータではなく学習に必要なデータのみとなり、データ移動や冗長性が大幅に削減されます。この効率化により、データ量が膨大になっても、モデルトレーニングの効果が損なわれることなく、スムーズなスケーリングが可能になります。
AI/MLのスケール拡大とビジネスニーズへの対応
ビジネスニーズに応じてAI/MLモデルをスケール拡大させるには、特に大規模なデータセットを処理する際に、HPC(ハイパフォーマンスコンピューティング)やスーパーコンピューティング(SC)へのアクセスが不可欠となります。しかし、その場合、HPCやSCを既存インフラと統合する際に、複雑な課題に直面することがしばしばあります。
このような課題に対しては、データサイエンスチーム向けにAI/ML実験を追跡する専用プラットフォームを展開し、異なるHPCインフラでもAI/MLワークロードと従来のHPC/SCワークロードを並行して実行できる統合アプローチが有効です。このような仕組みにより、最小限のコード変更やインフラ再構成でAI/MLモデルのスケールを迅速に拡大することが可能となり、技術的なボトルネックを回避しながら、AI/MLモデルの成長を促進できます。
イノベーションとコスト削減の最適化
このように、インフラ管理の複雑さを軽減することで、企業はインフラ維持にかける時間を減らし、イノベーションに集中できます。これにより、AI/MLの活用から迅速なビジネスインサイトを得ることができ、さらには大規模なコスト削減を実現するイノベーションを推進することが可能になります。最終的には、ビジネス目標に直結するデータファースト戦略の効果を最大化し、持続的な競争優位性を確立するための基盤を強化します。
このアプローチを採用することで、企業はインフラ管理から解放され、革新的なAI/MLソリューションを駆使して、持続的なビジネス成長を促進することができます。
フレキシブルな消費モデルによる次世代AI/MLのスーパーコンピューティング活用
企業がAI/MLモデルの規模を拡大し、POC(概念実証)から本稼働に移行する際、AI/MLチームとスーパーコンピューティングチーム、インフラ全体を統合して、ワークロードの管理を強化する絶好の機会が訪れます。この段階で、多くの企業はエクサスケールのスーパーコンピューティング技術をパブリッククラウドやプライベートクラウドを通じて、柔軟な消費モデルで活用する流れが加速しています。
特に、AI/MLモデルが急激に増加するデータや数百万、数十億に及ぶパラメータを処理するためには、柔軟で効率的なインフラストラクチャが不可欠です。フレキシブルな消費モデルにより、企業はスーパーコンピューティングの高速処理能力を必要に応じて利用でき、リソースを効率よく運用することが可能になります。この消費モデルは、データファーストモダナイゼーションの進展とともに、スピーディなAI/MLの実装と最適なコスト管理を実現します。
混合ワークロードとAI/MLの同時実行の課題解消
従来、スーパーコンピューティングアプリケーション(例:シミュレーション)とAI/MLモデルのトレーニングを同時に実行することは、インフラ負荷の観点で課題とされてきました。しかし、現代のエキスパートが開発したソリューションは、これらの課題を解消し、混合ワークロードの実行をスムーズにサポートします。
具体的には、以下のような高度な機能が提供されます:
コスト管理:リアルタイムでのワークロードとリソース使用量の監視により、コスト効率を最大化。
アプリケーションのスケジュール管理:各種アプリケーションの稼働タイミングを最適に設定。
インフラ管理:オペレーティングシステム、コンテナ、アクセラレータなどの管理を一元化。
このように、AI/MLとスーパーコンピューティングの統合は、データファースト戦略の中核を支える重要な要素となり、演算負荷が高いAIインサイトの生成をコスト効率よく進めるための最適な基盤を提供します。
スーパーコンピューティングの活用によるビジネス価値の最大化
フレキシブルな消費モデルを活用したスーパーコンピューティングは、膨大なデータ量を処理するAI/MLワークロードにとって、単なるコスト削減ツール以上の価値を提供します。これにより、企業はAI/MLのスピードを最大限に引き出しながら、迅速かつ高精度なインサイトを獲得し、データ駆動型のビジネス価値を最大化することが可能になります。
データコンサルタントとしての視点では、これらのスーパーコンピューティングのスケーラビリティと柔軟性が、企業のAI/MLの展開を飛躍的に加速させ、競争力強化に繋がる重要な要素であると捉えられます。

エッジクラウド現状の課題の整理
データの爆発的な増加に伴い、企業はエッジ、マルチクラウドといった多様化するエコシステム内で、データの流れや保管方法の複雑さに直面しています。この複雑さが、経営層にとってデータ管理の大きな課題となっており、結果として利用可能なデータの大部分が未活用のままとなっています。
データの重要性と成長率に関する具体的な情報
調査によると、今後2年間で企業データは年率40%のペースで増加する見込みです。しかしながら、企業が実際に活用しているデータの割合は非常に少なく、多くのデータがビジネスに活かされていないのが現状です。現在、企業は平均して全データの約40%をエッジからコアに定期的に転送していますが、この割合は今後57%に増加すると予測されています。即時にエッジからコアへ転送されるデータ量も、現在の8%から16%に倍増する見込みです。つまり、今後企業はさらに多くの移動するデータを管理する必要があります。
課題の要点とDataOpsの導入による解決策
この急激なデータ増加に対応するための一つのソリューションとして注目されているのが、DataOpsです。DataOpsは、データの生成者と使用者を効率的に結びつけるフレームワークであり、これを導入することで経営部門はビジネス成果の向上を期待できます。DataOpsを導入することで、データの移動や管理のプロセスを自動化・最適化し、データの価値を最大限に引き出すことが可能となります。
マルチクラウド環境におけるデータ管理の課題
今後の2年間で、企業はデータの急増に対応し、マルチクラウド環境内でのデータ管理に直面することが予測されています。特に、異なるクラウドプロバイダー間でのデータの移動や整合性を保つことが大きな課題です。また、ハイブリッドクラウド環境でのデータ管理も同様に重要なテーマとなりつつあります。これらの課題に対応するには、統合されたデータガバナンスと自動化されたデータ管理ツールの導入が不可欠です。
データ管理戦略におけるコンサルタントの提案
データコンサルタントとして、まず企業に対して提案できるのは、エッジからコアへのデータフローの可視化と最適化です。これにより、どのデータがビジネスにとって重要であり、どこで処理・保管されるべきかを明確にします。さらに、DataOpsの導入を通じて、データのライフサイクル全体を通じた効率化を図り、ビジネス成果を直接支援できるようになります。また、クラウド間のデータ移動を最適化し、リアルタイムのデータ活用が可能なインフラを構築することが重要です。
具体的なアクションとして、以下のステップを推奨します:
データガバナンスの強化:データの出所、移動、保管を追跡し、コンプライアンスやセキュリティ要件を遵守。
クラウド間のデータ統合戦略:異なるクラウドプロバイダー間のデータ整合性を保ち、ビジネスプロセスにおいてスムーズにデータを活用できる仕組みの構築。
自動化とAI活用:DataOpsに基づいた自動化を活用し、データ処理の手間を削減し、意思決定のスピードを向上させる。
これにより、企業はデータをより戦略的に活用し、成長と競争優位を実現できるようになります。
データコンサルタントとして、課題の要点を整理しつつ、DataOpsの導入やデータ管理におけるビジネス価値を強調し、企業の意思決定を支援する形で提示しました。
1: 現状の課題を明確にする
データの有効活用を阻む主な要因として、以下の5つが挙げられます。
収集したデータの利活用
データストレージの管理
必要なデータの収集の確実性
データのセキュリティ確保
異なるサイロに分断されたデータの統合・活用
これらの課題は、企業がデータから価値を引き出す際のボトルネックとなっています。
2: 課題解決のためのDataOpsの活用
DataOpsは、データの生成者と使用者をつなぎ、データフローを効率化する手法で、これらの課題に対する有力な解決策です。企業全体でDataOpsを最大限導入している企業は平均して10%程度にとどまっているものの、調査回答者の大半がDataOpsを「非常に」または「極めて」重要だと認識しています。
DataOpsの導入により、データ管理のプロセスが自動化され、異なるデータサイロ間のデータの統合が進むことで、データの価値を迅速かつ的確にビジネスに反映させることが可能です。
3: DataOpsによるビジネス成果
DataOpsは、他のデータ管理ソリューションと組み合わせることで、顧客ロイヤルティの向上や収益拡大といった具体的なビジネス成果をもたらします。特に、データの生成から利用までのプロセスがスムーズに連携することで、企業はリアルタイムの意思決定を行い、競争力を高めることができます。
4: セキュリティとストレージ管理の重要性
データセキュリティの強化は、企業の中央ストレージのニーズ管理を再考するうえで最も重要な要素となっています。調査回答者の3分の2は、データセキュリティが不十分であると認識しており、そのためデータ管理の最適化を図る際には、セキュリティが必須の要件とされています。
DataOpsの導入により、データの可視性が向上し、リアルタイムの監視やリスクの予測が可能となるため、セキュリティ対策が強化されると同時に、運用コストの削減にも寄与します。
5: データの増加と管理の重要性
データは、現在から未来にかけて急速に増加し続けています。世界人口が78億人に達し、リモートワークの拡大やIoT、エッジコンピューティング、AIといったテクノロジーの普及により、消費者向けデバイスとエンドポイントのデータ量は増え続けています。これらが企業データの膨大な増加を引き起こす主な要因です。
6: データコンサルタントの提案
企業がこのデータの急増に対応するためには、データガバナンスの強化が不可欠です。DataOpsや他の自動化ツールを活用することで、データの出所や流れ、利用の可視化が可能になり、データの「増加」と「無秩序な膨張」をコントロールできます。経営層は、これらのツールを通じてデータ管理の効率性を向上させ、データのビジネス価値を最大化する戦略を打ち立てるべきです。
具体的には以下のアプローチが有効です:
データライフサイクルの全体最適化:エッジからコアへのデータフローの管理を強化し、必要なデータが効率的に利用されるようにする。
セキュリティとガバナンスの強化:データの移動と利用におけるセキュリティを徹底し、リスクを未然に防止する体制を整える。
リアルタイムの意思決定を支援するインフラ:データをリアルタイムで取得・活用できる仕組みを整備し、迅速な意思決定をサポート。
これにより、企業はデータの急増と複雑化に対応しつつ、ビジネス成果を向上させることが可能です。