目次
データコンサルタントとして、以下の視点で文章を段階的に変更します。まず、データウェアハウスの定義とその役割を明確にし、次にその利点と課題を整理します。最後に、データウェアハウスを有効に活用するためのインフラ要素を具体的に説明します。
データウェアハウスの定義と役割を明確化:
データウェアハウスとは何か、その目的や役割を明確にすることで、クライアントがその意義を理解しやすくします。
「データウェアハウスの概要と役割
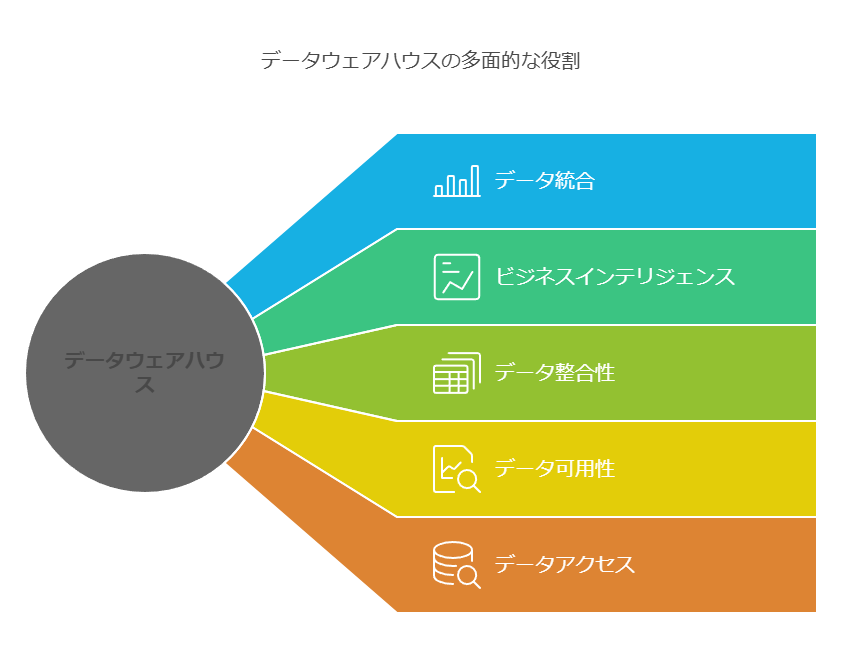
データウェアハウスは、分散したアプリケーションデータを1つの統合された物理的な場所に集約し、ビジネスインテリジェンスや分析に適したデータ基盤を提供します。企業内で生成される膨大なデータが様々なシステムやアプリケーションに分散している中、データウェアハウスはこれらのデータを一元管理し、データの整合性、可用性、アクセス性を向上させる重要なアーキテクチャソリューションです。」
データウェアハウスの課題と解決策の整理:
データウェアハウス自体が持つ限界や課題を説明し、それを補完するためのインフラの重要性を説明します。
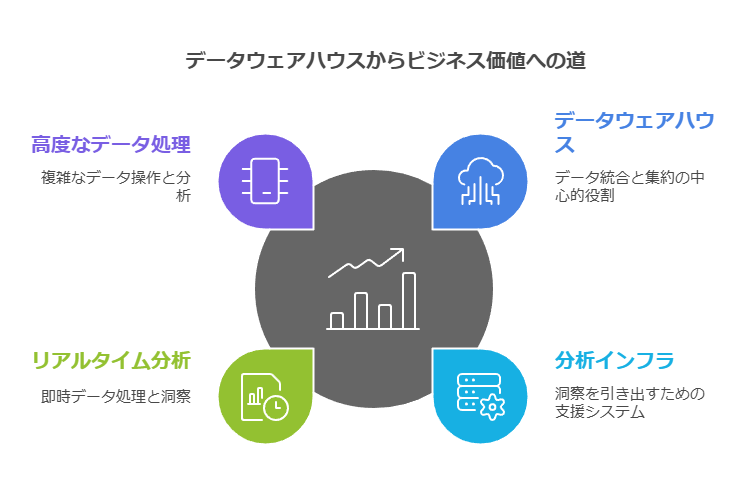
「データウェアハウスの限界とインフラの必要性
データウェアハウスは、データの統合と集約に役立ちますが、物理的にデータを集めるだけでは十分ではありません。データの分析や活用には、その周辺を支えるインフラが不可欠です。特に、リアルタイム分析や高度なデータ処理を必要とする場合、データウェアハウス単独では限界があります。そのため、データウェアハウスを中核に据えた分析インフラを整備し、ビジネス価値を引き出すことが重要です。」
分析インフラ要素の具体的な説明:
データウェアハウスの価値を最大限に引き出すための分析インフラ要素を整理し、それぞれの役割を明確にします。これにより、企業がどのような準備をするべきか理解できるようにします。
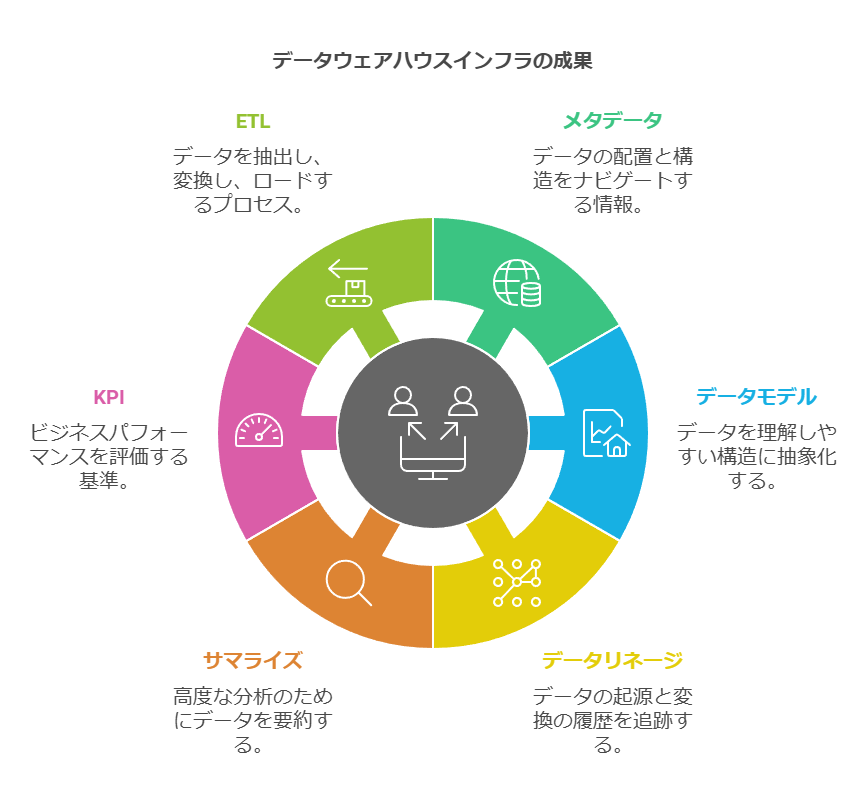
「データウェアハウスを支える分析インフラの要素
データウェアハウスのデータを効果的に活用するためには、いくつかの重要なインフラ要素があります。これらの要素は、データ分析の効率を向上させ、ビジネスに即した意思決定をサポートします。
メタデータ:
メタデータは、データの配置や構造をガイドする役割を持ち、どのデータがどこに保存されているかを示す情報です。メタデータを活用することで、データの検索や管理が容易になります。
データモデル:
データモデルは、データウェアハウス内のデータを抽象化し、エンドユーザーがデータを理解しやすくするための構造を提供します。データの相互関係やビジネスのロジックに基づいて設計されます。
データリネージ:
データリネージは、データの起源や変換の履歴を追跡し、データの信頼性や正確性を保証するための仕組みです。データがどのように生成され、加工され、現在の形になったかを示します。
サマライズ:
サマライズは、データを要約し、高度な分析や意思決定をサポートするためのアルゴリズムです。これにより、複雑なデータを簡潔にまとめ、主要な指標に基づいたインサイトを提供します。
KPI(主要業績指標):
KPIは、企業の目標達成度を評価するための基準となる指標であり、データウェアハウス内のデータを活用してパフォーマンスを測定します。
ETL(Extract, Transform, Load):
ETLは、アプリケーションからデータを抽出し、必要な形式に変換してから、データウェアハウスにロードするためのプロセスです。ETLは、データの一貫性と信頼性を保つための重要な技術です。」
最後に、データウェアハウスとその周辺のインフラを適切に設計することの重要性を強調し、クライアントに対して次のアクションを提案します。
「データウェアハウスを最大限に活用するために
データウェアハウスは、企業がデータを一元管理し、分析や意思決定を支援するための強力な基盤です。しかし、その真の価値を引き出すためには、周辺の分析インフラの整備が欠かせません。これにより、企業はデータを活用したインサイトを迅速に得ることができ、競争力を維持するための意思決定をサポートすることが可能です。次のステップとして、貴社のデータウェアハウス環境を評価し、必要なインフラの拡充を検討してみてはいかがでしょうか。」
このように、データウェアハウスの概念を整理し、その重要性やインフラの必要性をクライアントに伝えることで、具体的な次のアクションに繋げることができます。
データコンサルタントの視点から、履歴データやデータウェアハウスに関する課題と、現代のデータ管理における新たなニーズを考慮しつつ、文章を段階的に整理し、クライアントに対してより明確かつアクション可能な提案ができる内容に変更します。
履歴データの重要性とデータウェアハウスの役割:
まず、データウェアハウスが解決する履歴データの課題とその重要性を強調します。履歴データがどのようにビジネスに価値をもたらすのかを説明し、データウェアハウスの基本的な利点をクライアントに理解させます。
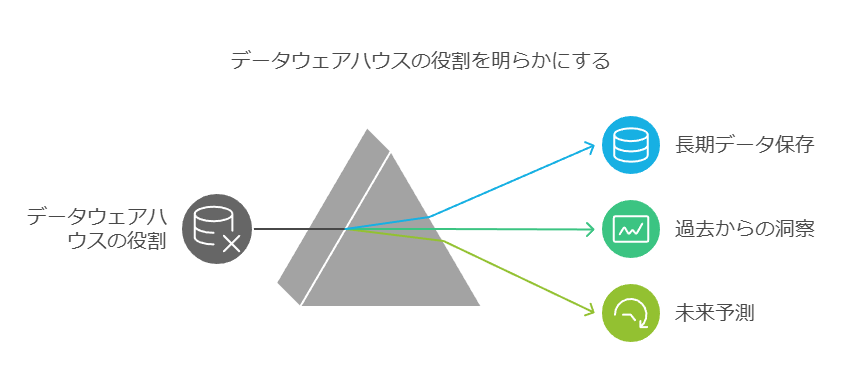
「履歴データの管理におけるデータウェアハウスの進化
従来、組織はデータの保存期間を短期間に制限していました。多くの場合、データは1週間、1か月、あるいは四半期分しか保持されず、長期にわたる履歴データの蓄積は困難でした。しかし、データウェアハウスの導入により、10年やそれ以上の長期間にわたるデータの保存が可能となり、これまで分析が困難だった時系列データの活用が現実のものとなりました。
たとえば、顧客の購買履歴を長期的に分析することで、過去の購買パターンから将来の行動を予測することができるようになり、ビジネスにとって重要なインサイトが得られます。データウェアハウスにより、過去のデータが未来を予測するための貴重な判断材料となり、データの保存期間がビジネス価値を生む重要な要素となりました。」
構造化データと非構造化データの限界:
次に、データウェアハウスの限界に触れ、特に構造化データに対する制約を説明します。また、非構造化データの急増や多様化するデータソースに対応する必要性を示します。
「データウェアハウスの限界と非構造化データの増加
データウェアハウスは、構造化データやトランザクションデータの集約と分析において非常に有効ですが、非構造化データの処理には限界があります。現在、企業はコールセンターの会話データ、インターネット上の行動データ、IoTデバイス、画像、動画、音声など、多様なデータソースを扱うようになっており、これらのデータは従来のデータウェアハウスだけでは処理しきれません。
さらに、機械学習(ML)や人工知能(AI)の進化により、SQLを使用しないデータ処理や、反復的なアルゴリズムが必要となり、データウェアハウスの範囲外のデータが増大しています。これに対応するためには、新たなデータ管理のアプローチが必要です。」
現代のデータ管理に必要なインフラの拡張:
最後に、現代のデータ管理において、データウェアハウスを補完する新しいインフラやテクノロジーの導入が不可欠であることを提案します。これにより、クライアントは新しいデータ戦略の構築に向けて、どの方向に進むべきかを理解できます。
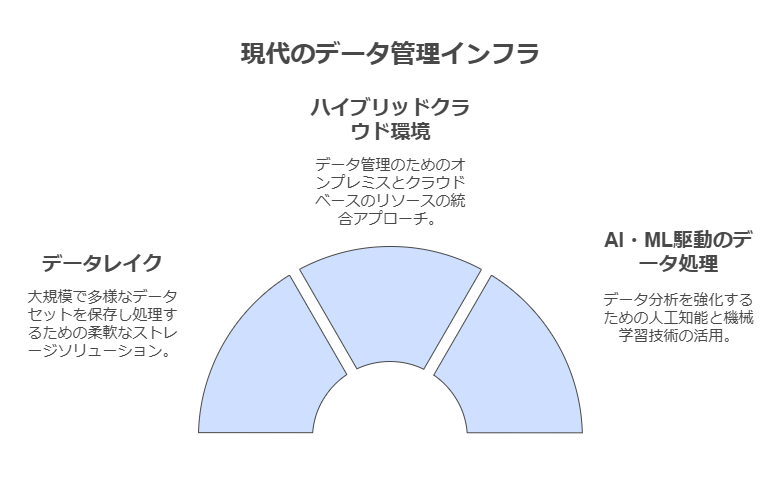
「現代のデータ管理インフラの必要性
企業が取り扱うデータの種類は急速に多様化しており、これまでのデータウェアハウスでは対応できない範囲が広がっています。特に、非構造化データ、機械生成データ、リアルタイムデータに対応するための新しいデータインフラの構築が必要です。これには、データレイクやハイブリッドクラウド環境、AI・MLを活用した高度なデータ処理基盤が含まれます。
データウェアハウスは依然として重要な役割を果たしますが、それを補完する新しいソリューションの導入により、企業はあらゆる種類のデータを効率的に管理し、ビジネス価値を最大化することが可能です。」
これまでの分析を踏まえ、クライアントに次のアクションを提案します。具体的な方向性を示し、データウェアハウスの活用と合わせて新たなデータ管理戦略の構築を促します。
「次のステップ – データ管理戦略の再考
データウェアハウスは依然として企業のデータ管理における基盤であり、特に長期的な履歴データの保存と分析において重要な役割を果たします。しかし、データの多様化とテクノロジーの進化に伴い、従来のデータウェアハウスだけでは対応しきれない課題が生じています。
これからのデータ戦略には、データレイクやクラウドネイティブなソリューションを含むハイブリッド環境の整備や、AIや機械学習を活用した非構造化データの分析基盤の構築が不可欠です。貴社の現状を評価し、次世代のデータ管理インフラを見据えたアプローチを検討してみてはいかがでしょうか。」
このように、データウェアハウスの利点と限界を整理し、クライアントが次に取るべき具体的なステップを提案することで、彼らのデータ戦略構築に役立つ情報を提供します。
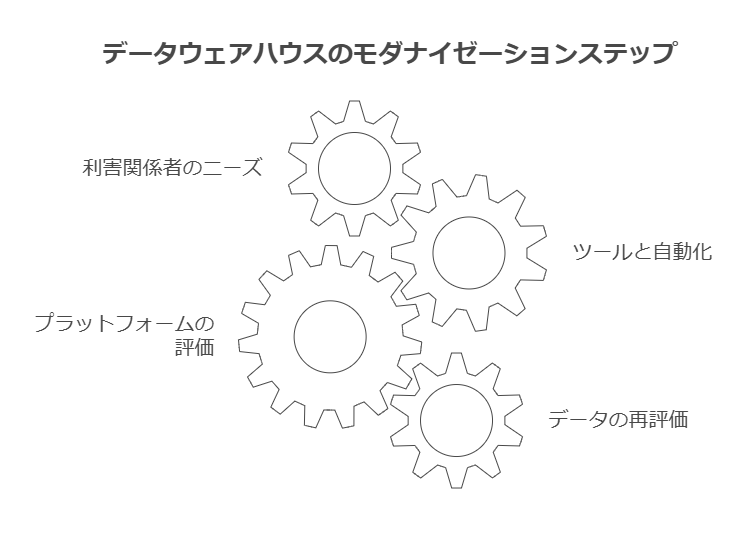
クラウドデータウェアハウスモダナイゼーション設計の重要事項
1. 利害関係者のニーズの把握
クラウドデータウェアハウスのモダナイゼーションを進める際、まず利害関係者(ステークホルダー)の要件を明確にする必要があります。企業の意思決定者、IT部門、データアナリスト、エンドユーザーなど、各グループは異なる視点と期待を持っています。
必須要件(要求):
経営陣:意思決定に必要なリアルタイムでのデータ分析とレポートの提供。
IT部門:システムのスケーラビリティ、安全性、そして低コストな維持管理。
データアナリスト:アクセスしやすく、クエリの応答速度が速いデータプラットフォーム。
希望要件:
柔軟なカスタマイズ機能:特にデータサイエンスチームやマーケティング部門は、柔軟で直感的なデータ操作ができる環境を求めます。
自動化機能:データフローや統合プロセスの自動化により、手動作業の軽減と効率性の向上を望んでいます。
2. ツールと自動化の有効活用
クラウドデータウェアハウスをモダナイズする際、ツールと自動化機能の選定と連携は極めて重要です。モダナイゼーションにおいて以下の点を検討することが必要です:
データ管理とデータ統合ツールの統合:複数のツールが連携して機能しているか、それとも断片化されているかを確認します。例えば、データ管理プラットフォームでETL(抽出、変換、ロード)プロセスが一貫して行えるか、データセキュリティ機能が十分であるかが重要です。
自動化機能の導入:データの統合、クリーニング、処理を自動化することで、人的リソースを削減し、リアルタイムのデータ更新を実現できます。データのボリュームが増加しても対応できる柔軟な自動化は不可欠です。
3. データ管理プラットフォームの評価
クラウドデータウェアハウスのモダナイゼーションにおいて、データプラットフォームの機能性がビジネスニーズに合致しているかどうかを評価します。具体的な評価ポイントは以下の通りです:
接続性:複数のデータソースから容易にデータを取り込み、必要に応じて他システムと連携できるか。
使いやすさ:技術スキルの異なるユーザーが簡単にデータ操作やクエリができるUI/UXが提供されているか。
迅速な統合:異なるデータソース間の統合がスムーズかつ高速で行えるか。
エンドツーエンドのソリューション提供:データ収集から保存、分析まで一貫したソリューションが提供されているか。
拡張性:データ量の増加に伴い、システムが無理なくスケールアップできるかどうか。
4. データの再評価:企業の最大資産としてのデータ活用
データは今や企業の最も重要な資産の一つです。そのため、クラウドデータウェアハウスをモダナイズすることで、データをより効率的かつ戦略的に活用し、ビジネス価値を引き出す必要があります。
データドリブンの意思決定支援:クラウドベースのデータウェアハウスを活用することで、リアルタイムのデータに基づいた迅速な意思決定が可能です。これにより、競争優位性を確保し、より良い顧客体験を提供できます。
サイロ化されたデータの統合:従来のデータサイロ化は、企業全体でデータを活用するための大きな障害となっていました。クラウド環境への移行により、部門横断的なデータ統合が容易になります。
5. クラウドインフラストラクチャの活用
多くの企業は既にクラウドへの移行に成功しており、その結果、データ管理の柔軟性とセキュリティを大幅に向上させています。例えば、Google BigQueryなどのクラウドデータウェアハウスのソリューションは、以下のような特徴を持ち、ビジネスの変化に迅速に対応できる基盤を提供しています:
柔軟性:データボリュームの増加に対応しやすく、企業が必要とするリソースに応じてスケールアップやスケールダウンが可能です。
セキュリティ:データの暗号化やアクセス管理が強化され、クラウド上でも安全なデータ管理が可能です。
中断の少ない移行:既存の業務を混乱させることなく、クラウドへの移行がスムーズに行えるため、ビジネスに与える影響を最小限に抑えられます。
6. モダナイゼーションのタイミング:今が最適な時期
クラウドデータウェアハウスをモダナイズするためのテクノロジーは、既に様々な業界で実績があります。今こそ、データウェアハウスのモダナイゼーションに取り組み、将来的なビジネス成長に向けて基盤を整える絶好の機会です。現代の競争の激しい市場では、データ活用によるビジネス価値の最大化が、企業の成功に直結します。
データコンサルタントの視点から、クラウドデータウェアハウスのモダナイゼーションは、ビジネスの成長とデータ戦略の最適化を図るために欠かせない取り組みです。
クラウドデータウェアハウスの課題と解決策
1. インフラストラクチャの簡素化と高度な分析機能の追加
多くのクライアントが直面している共通の課題は、データウェアハウスのインフラストラクチャの簡素化と、それに付随するAI、機械学習、セルフサービス分析の機能追加です。これらの最新技術をビジネスユーザーにも活用できる形で提供することは、デジタル変革の中核となります。技術革新とビジネスの変化は、常に密接に関連しており、単なるITの改善だけでなく、業務プロセスや企業文化の適応が求められます。
コンサルタントの視点:
簡素化されたインフラは、運用コスト削減と業務のスピードアップにつながります。データウェアハウスをクラウドに移行することで、インフラ管理の手間が軽減され、スケーラビリティや自動化による効率向上が期待されます。
ビジネスユーザー向け機能の強化により、IT部門の負担を軽減し、データ活用の幅を広げることが可能です。セルフサービス分析の導入で、意思決定プロセスをよりデータドリブンにシフトすることができます。
2. SQL インターフェースを活用した業務の効率化
BigQueryのようなクラウドベースのデータウェアハウスを利用することで、データサイエンティストの負担を軽減し、従業員全体にデータの取り扱いを広げることができます。特に、SQLインターフェースが標準的に利用できることで、多くの社員が既存のスキルを活かしてデータ活用が可能になります。
コンサルタントの視点:
データサイエンス業務の分散化:データサイエンティストの業務が集中しがちだったデータ準備やモデルトレーニングの作業を、他のチームやビジネスユーザーに移管することができ、効率的なワークフローが実現します。これにより、データサイエンティストはより高度な分析や機械学習モデルの開発に集中することができます。
データサイロの解消:クラウドベースのデータウェアハウスにより、プロジェクトごとにデータをサイロ化して保管する必要がなくなり、組織全体でのデータ共有が容易になります。
3. 大規模コンピューティングの活用による成長の促進
クラウドインフラストラクチャによる大規模なコンピューティングリソースを活用することで、従来のオンプレミス環境では不可能だった規模でのデータ処理が可能になります。これにより、時間とリソースを節約し、企業が新しいビジネスチャンスを見つけやすくなります。
コンサルタントの視点:
機械学習の導入拡大:例えば、予測分析やAI技術は、小売業のような業界においてビジネスモデルを変革する役割を果たしています。データウェアハウスの高度なコンピューティング機能を使うことで、AIや機械学習の導入が迅速に進み、ビジネスの意思決定を支援する新たなツールとして機能します。
予測分析の導入:ビジネスの正確な予測を通じて、より効果的な意思決定ができるようになり、売上予測や顧客セグメントの作成がリアルタイムで行えるようになります。
4. 組み込みの高度な分析機能の利活用
Google Cloud の BigQuery を利用することで、企業は高度な分析機能を活用し、リアルタイムで大規模なデータセットを分析することができます。これにより、ビジネスインサイトの共有や顧客行動の深い理解が可能になり、結果的にプロダクトエクスペリエンスの向上につながります。
コンサルタントの視点:
機械学習モデルの簡便化:BigQuery に組み込まれた機械学習機能を利用すれば、複雑な手順を踏むことなく、SQLステートメントを使って直接データセットに対してモデルを構築し、デプロイすることが可能です。
セルフサービス分析の促進:データサイエンティストやデータアナリストに限らず、ビジネスユーザーも直接予測分析に取り組むことができ、データの民主化が実現します。これにより、企業全体でのデータ活用が加速します。
5. すぐに始められる分析環境の整備
Googleのデータウェアハウスソリューションは、迅速な導入と容易な使用が可能であり、ビジネスユーザーがすぐに高度な分析やAIを活用できる環境を提供します。これにより、データ活用の障壁が下がり、企業全体でのデータ利用が進みます。
コンサルタントの視点:
データとユーザーの距離を縮める:ツールの直感的な操作性や高度な分析機能により、データの利用が特定の部門に偏ることなく、広範なユーザー層に提供されます。データドリブンな意思決定を支える基盤として、ビジネスの成長を後押しします。
クラウドベースのデータウェアハウスは、インフラ管理の効率化と高度な分析機能の導入によって、企業のデジタル変革を加速します。データの管理・活用を強化し、AIや機械学習を組み込むことで、ビジネス全体のパフォーマンスを向上させ、競争優位性を確保するための強力な基盤を構築することが可能です。

データウェアハウスの活用とビジネスへの影響
1. データウェアハウスのスケーラビリティと効率的な運用
現代のビジネス環境では、最新のデータに基づく意思決定が競争優位をもたらします。BigQueryを利用することで、データウェアハウス自体に分析機能を組み込むことができ、より多くのユーザーがデータにアクセスし、リアルタイムでインサイトを活用する環境が整います。
コンサルタントの視点:
スケーラブルなインフラ:BigQueryはユーザー数が増加してもスケールするため、増え続けるデータ量とユーザーのニーズに柔軟に対応できます。
コンピューティングの分離:コンピューティングリソースをストレージから分離し、ビジネスの要求に応じて拡張可能です。これにより、リソースの効率的な活用が可能になり、コスト管理も容易になります。
2. ITチームの役割の進化
クラウドベースのデータウェアハウスの導入により、ITチームの役割も進化しています。これまでITチームが担っていたバックアップや復元、データの複製といった作業は、クラウドの自動化機能で対応可能になります。これにより、ITチームは時間を節約し、より価値の高い新機能開発にリソースを集中させることが可能です。
コンサルタントの視点:
新機能開発に注力:運用管理の負担が軽減されることで、IT部門はビジネスの競争力を高める新しいデジタル機能やイノベーションに集中できるようになります。
セキュリティの強化:クラウドソリューションは、自動化されたバックアップとデータ保護機能を提供し、機密データの分類や秘匿化を容易にすることで、セキュリティ面でも安心感を提供します。
3. データドリブンな意思決定と業務の変革
20th Century Foxの事例では、従来のデータサイエンティストによる分析が中心だった業務が、クラウドベースのソリューションを活用することで大幅に効率化されました。特に、BigQueryのシンプルなSQLインターフェースとBigQuery MLの機械学習機能を使うことで、データサイエンティスト以外のマーケティングアナリストでも高度な分析が行えるようになりました。
コンサルタントの視点:
データの民主化:データサイエンティストの専門的な作業に依存せず、多くのビジネスユーザーが自らデータ分析を行えるようになることで、迅速な意思決定が可能になります。
マーケティングの最適化:BigQuery MLを使った観客セグメントの作成により、マーケティングチームはデータに基づいたターゲティングキャンペーンを実施し、広告効果を最大化できるようになりました。
4. データ分析を活用した顧客エクスペリエンスの向上
データドリブンなアプローチを採用することで、企業はカスタマーエクスペリエンスを大幅に改善できます。BigQueryを利用した高度な分析により、顧客行動の詳細な理解が可能となり、ターゲットを絞ったキャンペーンやプロダクトエクスペリエンスの向上につなげることができます。
コンサルタントの視点:
ビジネスインテリジェンスの共有:複数の部門でデータの共有が容易になり、数回のクリックで重要なビジネスインサイトを可視化し、全社的な意思決定を強化することができます。
カスタマーエクスペリエンスの改善:マーケティングチームは、より細かいセグメントに対してパーソナライズされたアプローチを行い、顧客体験を向上させ、ビジネス成果の向上を実現します。
5. デジタル化の促進とビジネス成長への貢献
BigQueryを活用することで、企業はデジタル化を加速し、業務プロセスの効率化だけでなく、新たなビジネスチャンスを探ることが可能になります。予測分析や機械学習の導入は、ビジネスの競争力を強化し、長期的な成長をサポートします。
コンサルタントの視点:
合理的な費用管理:スケーラブルなクラウド環境を活用することで、使用量に応じたコスト管理が可能となり、リソースの最適な配分を実現します。
新たな成長機会の探索:AIや機械学習を活用することで、顧客セグメントの予測分析や売上予測など、ビジネスの意思決定に直結するデータを迅速に提供できます。
BigQueryのようなクラウドベースのデータウェアハウスは、データをリアルタイムで活用し、ビジネスプロセス全体をデータドリブンに変革するための強力なツールです。企業はこれを活用して、効率的な運用、コスト削減、さらには顧客体験の向上を実現し、長期的な成長を促進できます。
データウェアハウスの最適化とリアルタイム分析の重要性
1. データ分析の民主化とスケーラビリティの必要性
従来、データ分析業務はアナリストやデータサイエンティストといった専門チームに依存していました。これにより、定期的なレポート作成やビジネスチームからの要求に応じた分析が行われていましたが、データの急激な増加や高度な分析要求により、これらの専門家にかかる負担が増大しています。
コンサルタントの視点:
データの民主化:高度な分析を全てのチームに開放し、専門チームに依存しないデータ活用を推進することが重要です。これにより、各部署が独自にリアルタイムでインサイトを得られ、迅速な意思決定が可能になります。
スケーラブルなインフラ:ビジネス全体でデータ分析の重要性が増しているため、スケーラブルなデータウェアハウスが必要です。クラウドベースのソリューションは、データ量やユーザー数に応じた柔軟な対応を実現します。
2. リアルタイムデータの出現によるビジネスへのインパクト
ビジネス環境の変化により、データの処理速度と対応力が求められています。これまではバッチ処理による定期的なレポートが一般的でしたが、リアルタイムでのデータ処理やストリーミングデータの活用が必要となっています。
コンサルタントの視点:
リアルタイムデータの統合:データウェアハウスは、バッチデータの処理に加えて、リアルタイムのストリーミングデータを同時にサポートする必要があります。これにより、ビジネス機会が発生した瞬間に即座に対応することが可能です。
クエリのパフォーマンス向上:従来のシステムではハードウェアコストやパフォーマンスが制約となっていましたが、クラウドベースのデータウェアハウスは、コスト効率を維持しながら複数のクエリを同時に処理し、迅速な意思決定を支援します。
3. 各業界でのリアルタイムデータのユースケース
データウェアハウスがもたらすメリットは、業界を問わず、的確かつ迅速な意思決定をサポートする点にあります。具体的なユースケースとして、以下の例が挙げられます。
コンサルタントの視点:
eコマース:リアルタイムのクリックストリーム分析を通じて、ユーザーの行動に基づいた動的なセグメント化を行い、マーケティングのターゲティングを強化します。
小売:POSトランザクションのリアルタイム分析により、在庫管理の精度が向上し、欠品や過剰在庫のリスクを最小化します。
モバイルゲーム:ユーザーの動作に応じた即時のフィードバックを提供し、ゲーム体験を向上させるための調整を行います。
製造:IoTデータをリアルタイムで分析し、業務効率の改善や予測メンテナンスを実現し、生産性の向上を図ります。
4. リモートワークがもたらす柔軟性と効率性
リモートワークの普及により、従来の通勤やオフィス勤務に関連する負担が軽減され、従業員の生産性とワークライフバランスが向上しています。データウェアハウスをクラウドに移行することで、リモート環境からでも安全かつ効率的にデータを活用できる環境が整います。
コンサルタントの視点:
ワークライフバランスの向上:通勤の負担がなくなることで、従業員は仕事とプライベートをバランスよく両立できます。クラウドベースのデータウェアハウスは、どこからでも安全にアクセスできるため、リモートワークにも最適です。
業務効率の向上:WEB会議やオンラインコラボレーションツールの導入により、会議時間が短縮され、業務の効率化が図られます。クラウド上でのデータ共有とコラボレーションが容易になることで、意思決定のスピードも向上します。
5. データドリブンな意思決定が競争優位をもたらす
業界を問わず、データを活用して迅速かつ的確な意思決定を下すことが、企業にとって競争優位をもたらす重要な要素となっています。データウェアハウスのモダナイゼーションにより、リアルタイムのインサイトと効率的なデータ活用を可能にし、ビジネスの成長を促進します。
コンサルタントの視点:
データドリブン経営の推進:リアルタイム分析を活用することで、ビジネスのあらゆる局面で迅速かつ的確な判断が下せるようになり、競争力の向上に寄与します。
継続的なイノベーション:データウェアハウスの進化により、新たなビジネスモデルの創出や、より高度なデータ活用を通じたイノベーションが促進されます。
データウェアハウスのモダナイゼーションは、単なる技術的な改善にとどまらず、ビジネスの意思決定プロセス全体を変革する力を持っています。リアルタイムデータの活用と分析能力の向上により、企業は持続的な成長を実現し、競争力を強化することが可能です。
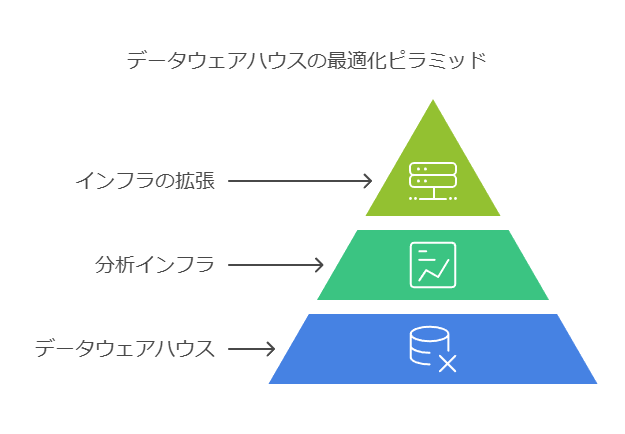
データウェアハウスにおけるAI・機械学習の導入と未来の技術展望
1. AI・機械学習の導入は未来の話ではなく、現実的なステップ
人工知能(AI)や機械学習は、かつては特定の大企業や研究機関だけが利用する技術と見られていました。しかし、現在ではこれらのツールは手軽に導入できるようになり、あらゆる企業にとって現実的なソリューションとなっています。
コンサルタントの視点:
導入のしやすさ:今日のAIや機械学習は、以前ほど複雑ではなくなっており、企業が持つ既存のデータを活用することで、短期間で運用を開始できます。特に、クラウドベースのプラットフォームを利用することで、初期コストや開発リソースを抑えながらスケーラブルなソリューションを展開できます。
競争優位性の強化:AIや機械学習の活用により、企業は業務プロセスを自動化し、顧客ニーズを予測するなど、従来では実現できなかった効率化と成長機会を享受できます。
2. 人間の限界を超えるためのAI・機械学習
データ量の急増や市場の複雑化に伴い、人間の速度やリソースでは十分に対処できなくなっています。こうした背景から、AIや機械学習がデータ処理や意思決定プロセスを補完し、ビジネスの即応性を高める必要があります。
コンサルタントの視点:
スピードと自動化:AI・機械学習は、大量のデータから迅速かつ正確に洞察を得る手段として、既存のビジネスプロセスを強力に支援します。これにより、リアルタイムでの市場変動や顧客行動に対応し、ビジネスチャンスを逃さない体制を構築できます。
成熟した技術の利点:現在のAI技術は高度に発展しており、デプロイや運用も容易です。クラウドベースのデータウェアハウスでは、追加のインフラや複雑な設定を必要とせず、機械学習モデルを直接活用できます。
3. データサイエンティストの不足を補完するためのセルフサービスAI
AIや機械学習の導入には、プログラミングスキルや専門的な知識が必要であり、これが導入のハードルとしてしばしば指摘されます。多くの企業は、データサイエンティストを雇うことが困難であり、予測分析のためのモデル構築にも大きなコストがかかります。
コンサルタントの視点:
セルフサービスAIの利活用:従来のプログラミングやデータサイエンスに頼らないツールが増えており、SQLに精通したデータアナリストでも、簡単な操作でAIを活用できる環境が整備されています。例えば、BigQuery MLなどのプラットフォームを使えば、SQLベースで予測分析モデルを構築し、データウェアハウス内で直接分析を行うことが可能です。
コスト効率の向上:セルフサービス型のAIツールを導入することで、データサイエンティストのチームに依存せず、企業全体でAIを活用できる体制を築くことができます。これにより、コスト削減と迅速な価値創出が可能になります。
4. データのスコープと品質の課題を解決する
AI導入における主な課題として、データのスコープや品質、スタッフのスキル不足がしばしば挙げられます。2019年のGartner調査によると、多くの企業がAIを効果的に活用するための準備が十分でないことがわかっています。
コンサルタントの視点:
データ品質の向上:AIや機械学習の効果を最大化するためには、データの品質とスコープの改善が不可欠です。データクレンジングや適切なデータガバナンスを行い、モデルが正確な予測を提供できるようにすることが重要です。
スキルギャップの解消:AI導入の際には、スタッフのスキル向上が課題となります。しかし、今日のAIツールはユーザーフレンドリーなものが多く、技術的なスキルがなくても導入できるサポート体制が整っています。また、教育プログラムやトレーニングを通じて、社員がAIのメリットを理解し、業務に活用できるような支援も行うべきです。
5. AI導入の課題と解決策
AIを効果的に活用するための課題は多岐にわたりますが、それらは適切な計画とツールを用いることで解決可能です。データのスコープと品質の向上、スキルギャップの解消、そしてAIの実際のビジネス活用に対する理解がカギとなります。
コンサルタントの視点:
課題の段階的解決:まずは小規模なプロジェクトから始め、徐々にAIの適用範囲を広げることで、リスクを最小化しつつ効果的な導入を進めることが重要です。最初のステップとして、既存のデータウェアハウスにAI・機械学習機能を追加し、簡単な予測モデルの構築や実験的な分析から始めることを推奨します。
理解と教育の促進:AIのメリットや具体的な活用方法について、全社的な理解を深めるための教育を行い、AIの導入を推進する文化を醸成することも重要です。
データウェアハウスにAIや機械学習を統合することで、企業は迅速かつ精度の高い意思決定を行い、競争力を大幅に向上させることが可能です。これからのビジネスにおいて、データ活用とAIの融合は不可欠な要素となります。
データコンサルタント視点による改善提案: リアルタイムデータ統合とクラウド移行のベストプラクティス
1. リアルタイムデータとバッチデータの統合に向けた課題と解決策
ビジネスユーザーが取り扱うリアルタイムデータには、ソーシャルメディアのアクティビティ、モバイルのインタラクションデータ、ネットワークログなどがありますが、多くの場合、これらはバッチデータと分離された異なるシステムで扱われています。この分断が原因で、企業はデータ全体をビジネスにどのように活用すべきか、全体像を把握することが困難になっています。
コンサルタントの視点:
データ統合の必要性:リアルタイムデータとバッチデータを一元的に処理するための統合されたアーキテクチャが必要です。複数のデータソースがある場合、それぞれのデータがもたらすインサイトを組み合わせることで、より正確かつ迅速な意思決定が可能になります。
技術的な統合ソリューション:クラウド上でこれらのデータソースを効率的に統合するためには、Apache BeamのようなオープンソースSDKやGoogle CloudのDataflowを使用することで、バッチ処理とストリーミング処理を統合し、データの統合運用を実現することが推奨されます。
2. クラウド移行時の課題とその対処法
多くの企業は、既存のオンプレミスアーキテクチャをクラウドに移行する際、従来の課題をそのままクラウドに引き継いでしまうことがあります。特に、リアルタイムストリーミングの課題は未解決のままであり、多くの企業がストリーミングデータの活用に至っていません。しかし、リアルタイムデータ処理は、顧客体験の向上やビジネス競争力強化において重要な要素となります。
コンサルタントの視点:
クラウド移行のベストプラクティス:クラウド移行時には、オンプレミスの問題を解消するために、クラウドネイティブなソリューションを採用することが重要です。データの分断やリアルタイム性の欠如を解消するために、ストリーミングとバッチ処理を一元管理するアーキテクチャを設計する必要があります。
リアルタイム処理の価値:リアルタイムでのデータ処理は、eコマースのパーソナライズや製造業における予防保守、財務リスク管理など、様々なユースケースで大きな価値を提供します。こうした機能は、企業の競争優位性を大幅に向上させます。
3. ストリーミングデータ処理とDataflowの活用
Google CloudのDataflowを使用することで、企業は複雑な操作をせずにリアルタイムのストリーミングデータを分析できるようになります。特に、Apache Beamを通じてバッチ処理とストリーム処理を統合することで、開発者は選択する言語に柔軟性を持たせることができ、システムの移植性も確保されます。
コンサルタントの視点:
Dataflowによるシンプルなデプロイ:Dataflowを活用すれば、データアナリストがSQLセマンティクスを使用してストリーミングパイプラインを容易にデプロイでき、追加のトレーニングやエンジニアリングリソースを必要とせずに、リアルタイムのデータ分析が可能になります。
コード再利用のメリット:ストリーミング、バッチ、オープンソースフレームワーク間でコードを再利用できるため、企業全体での開発効率が向上します。また、既存のエコシステムにおける投資を最大限に活用できます。
4. BigQueryを中心としたデータ分析基盤の強化
BigQueryは、標準SQLインターフェースを提供し、どのチームでも容易にクエリを記述できるため、データアクセスが簡便です。また、Lookerの統合により、データの可視化やレポート作成も容易になり、ビジネスユーザーがデータに基づく意思決定を迅速に行える環境が整います。
コンサルタントの視点:
エンタープライズ全体でのデータ利用促進:BigQueryは、スケーラブルなアーキテクチャを備えており、1秒間に最大100万行のデータを取り込むことが可能です。これにより、データ分析のタイムラグが最小限に抑えられ、リアルタイムデータを迅速に意思決定に活用できる環境が構築されます。
Lookerによる可視化とコラボレーションの強化:Lookerの統合により、ビジネスユーザーは簡単にダッシュボードやレポートを作成し、チーム内外でのコラボレーションが円滑に行えるようになります。これにより、データドリブンな意思決定が組織全体で促進されます。
5. データドリブンなビジネスへの移行
リアルタイムデータとバッチデータを統合し、クラウドベースのデータ分析基盤を活用することで、企業はより迅速で正確な意思決定を行えるようになります。これにより、ビジネスはデータドリブンな戦略に基づいて、顧客体験を向上させ、競争力を強化することが可能です。
コンサルタントの視点:
データドリブン文化の醸成:リアルタイムデータ処理の利点を全社的に理解し、データドリブンな意思決定を推進する文化を築くことが重要です。BigQueryやDataflowなどのツールは、すでに実績のあるソリューションであり、企業のデジタルトランスフォーメーションを加速させるための効果的な手段です。
これらのアプローチを実践することで、企業はデータの価値を最大限に引き出し、リアルタイムデータを活用した競争力のあるビジネス基盤を構築することができます。クラウドネイティブなアプローチとデータ統合戦略は、未来のビジネスをリードする鍵となります。
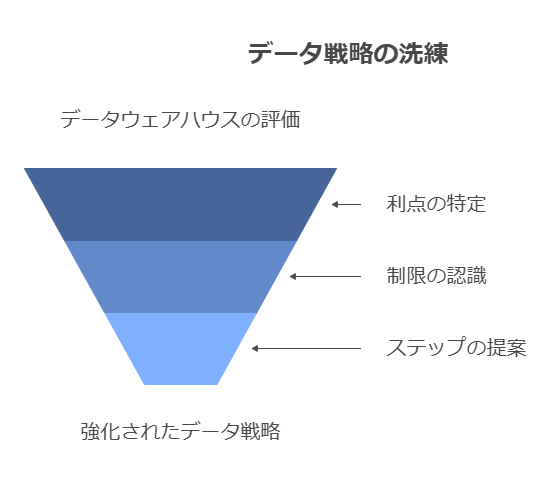
データウェアハウスの信頼性とセキュリティ管理の強化
1. 透明性を確保するデータアクセスの重要性
Google Cloudの透明性機能は、管理者が顧客データにアクセスする際に、リアルタイムでログを記録し、定期的な監査を実施することで、そのアクセスの有効性を確認できる仕組みを提供します。これにより、データアクセスの透明性と信頼性が向上し、顧客に安心感を提供します。
コンサルタントの視点:
透明性による信頼の強化:企業は、アクセス透明性を高めることで、顧客やパートナーとの信頼を築くことができます。特に、データガバナンスにおける透明性は、セキュリティ対策の一環として、重要なコンプライアンス要件を満たすためにも不可欠です。
自動監査による運用効率の向上:リアルタイムのアクセスログと自動化された監査プロセスにより、セキュリティ管理を効率化し、運用コストを削減します。また、異常なアクセスが検出された場合にも迅速な対応が可能です。
2. GO-JEKの事例に見るデータ管理のベストプラクティス
GO-JEKは、Google Cloudを活用して膨大なデータを一元管理し、数百万人のユーザーにサービスを提供しています。BigQueryとData Catalog APIを用いたデータウェアハウスの構築により、データの統合と管理が容易になり、数千人のデータアナリストが効率的にクエリを実行できる環境が整っています。
コンサルタントの視点:
スケーラビリティとアクセス管理のバランス:データアナリストやビジネスアナリストが安全にデータにアクセスできるよう、Cloud IAMを利用したアクセス制御が不可欠です。これにより、企業はデータを安全に保ちながらも、柔軟にデータを利用できる環境を提供できます。
統合的なデータ管理プラットフォームの価値:BigQueryとData Catalogのようなツールは、膨大なデータを効率的に管理・活用するための強力なプラットフォームを提供します。これにより、企業全体のデータ活用の効率が飛躍的に向上します。
3. 大規模なデータ保護のための多層セキュリティ
Google Cloudのデータウェアハウスには、データの転送中と保存時に自動暗号化が施され、アクセスは監査済みの権限を持つロールやサービスに限定されます。また、クラウドインフラ全体にわたる多層構造のセキュリティアプローチにより、データの保護と信頼性が確保されています。
コンサルタントの視点:
多層セキュリティアーキテクチャの重要性:データ保護において、ハードウェアからソフトウェア、運用プロセスに至るまで、すべてのレイヤーでセキュリティ対策が施されていることは、セキュリティリスクの低減に不可欠です。特に、大規模なデータ環境では、ハードウェアレベルでのセキュリティも重要な役割を果たします。
自動化された暗号化プロセス:データの暗号化と監査機能が自動化されていることで、運用負荷を軽減し、セキュリティに関する人的エラーを減少させることができます。
4. データ追跡と管理ツールの活用
Google Cloudのデータ管理ツールとして、Cloud Data Loss Prevention (DLP)やData Catalogなどが提供されています。Cloud DLPは、クレジットカード番号や社会保障番号などの機密データを自動的に検出・分類し、ポリシーに基づいて秘匿化します。また、Data Catalogは、メタデータの管理を容易にし、データの迅速な検出や管理をサポートします。
コンサルタントの視点:
機密データの自動検出と保護:Cloud DLPを活用することで、機密データを自動的に特定し、ポリシーに従った管理が可能となります。これにより、データの漏洩リスクを大幅に削減でき、コンプライアンス要件にも対応します。
メタデータ管理の効率化:Data Catalogは、データの検出や分類、アクセス管理をシンプルにするため、データガバナンスを強化するための重要なツールです。これにより、組織内でデータを適切に利用し、効率的な運用を実現します。
5. IAMを活用した一元的なアクセス管理
Cloud Identity and Access Management (IAM)は、アクセス制御とセキュリティポリシーの一元管理を提供し、組織全体でのセキュリティ管理を強化します。これにより、セキュリティポリシーが統一され、異なるチーム間でのデータアクセスにおける可視性が向上します。
コンサルタントの視点:
アクセス管理の一元化によるセキュリティ向上:IAMを活用することで、各ユーザーやチームのアクセス権限を一元的に管理し、誤った権限付与を防ぐことができます。これにより、内部的なセキュリティリスクを最小限に抑えます。
可視性の向上とセキュリティポリシーの統一:セキュリティポリシーの一元管理により、組織全体でのデータアクセスにおける透明性が確保され、セキュリティ基準の遵守が徹底されます。
データウェアハウスの信頼性とセキュリティを高めるためには、アクセス透明性や多層セキュリティ、データ管理ツールの活用が不可欠です。これにより、企業はデータガバナンスを強化し、リアルタイムデータを安心して活用できる環境を構築できます。また、クラウド上でのデータ管理を効率化することで、運用コストを削減しながらも、高度なセキュリティを維持することが可能です。
クラウドデータウェアハウスのモダナイゼーションの青写真 – データコンサルタント視点
この青写真では、エンタープライズ向けのクラウドデータ管理ソリューションを活用し、モダンなクラウドデータウェアハウスの導入と最適化を支援するフレームワークを構築します。各ステップにおいて、データの品質、セキュリティ、スケーラビリティを確保しながら、AIや機械学習(ML)を取り入れた高度なデータ活用のアプローチを提案します。
1. データカタログ化とデータガバナンスの強化
データカタログ化: モダナイゼーションの第一歩として、データを一元的に管理するデータカタログを整備します。これにより、データ設計者は移行対象データの探索、キュレーション、管理が可能になり、データの品質向上と制御を効率的に行えます。カタログ化は、データの分類や優先順位付けにも役立ち、クラウド移行におけるデータの全体像を把握しやすくします。
データガバナンスの強化: オンプレミスやクラウド環境を問わず、すべてのデータに対して一貫したデータ制御を適用するためのデータガバナンスを強化します。特に、移動中やアクセス中のデータに対するセキュリティを確保することで、リスク軽減とコンプライアンス遵守を実現します。
AIとMLの活用: AI/MLを活用することで、データディスカバリの自動化や非構造化データのオンボーディングを効率化し、生産性の向上とインテリジェントな意思決定を支援します。
2. データの効率的な複製と大量取り込み
クラウドオブジェクトストアへのデータ移行: データの複製や大量取り込みを効率的に行うために、スケーラブルなクラウドオブジェクトストアを活用します。これにより、クラウド環境で大量のデータを迅速かつ柔軟に処理でき、ビジネス要件に応じたリアルタイム分析や迅速なデータ更新が可能となります。
3. ストリーミングデータの効率的な収集と処理
メッセージングシステムの活用: Apache KafkaやAWS Kinesis、Azure Event Hubといったメッセージングシステムを用いて、ストリーミングデータを効率的に収集します。これにより、高スループットでデータをリアルタイムに処理し、クラウド内でのストリーミングアナリティクスの実行を可能にします。
4. APIおよびアプリケーション統合の最適化
API統合とリアルタイムオーケストレーション: さまざまなSaaSアプリケーションやオンプレミスアプリケーション間のデータ同期、リアルタイムプロセスのオーケストレーションを支援します。例えば、NetSuiteからSalesforceへのデータ同期のように、APIを活用してビジネスプロセスを最適化し、データフローを自動化します。
5. クラウドデータ統合の効率化
クラウドプラットフォーム間のデータ統合: 複数のクラウド環境で運用されるデータを、シームレスに接続、統合、同期する仕組みを構築します。これにより、企業全体でデータの一貫性を保ち、クラウド間のデータ移行や統合作業の負荷を軽減します。
6. 技術と業務プロセスの連携
技術と業務の連携強化: クラウドデータ統合技術を活用し、異なるソースから取得したデータを統合・クレンジングし、ビジネス価値の高い情報に変換します。このプロセスにより、業務部門と技術部門が連携してデータドリブンな意思決定を支援できるようになります。
7. 高度なデータキュレーションとレポート生成
データのクレンジングとキュレーション: データが統合・クレンジングされると、高度にキュレーションされたデータがクラウドデータウェアハウスに保存され、業務レポートや視覚化ダッシュボードといった下流のアプリケーションに入力されます。これにより、データの整合性を保ちながらビジネス分析を強化し、より正確な意思決定が可能になります。
8. 拡張可能なアーキテクチャの導入
クラウドデータレイクとMLの統合: クラウドデータウェアハウスに加え、柔軟性のあるコンピューティング能力を備えたクラウドデータレイクや機械学習モデルを活用することで、高度なアナリティクスを実現します。この拡張可能なアーキテクチャにより、従来のデータウェアハウジングを超えた、予測分析やAIドリブンのインサイト生成が可能になります。
データコンサルタントの提言
データのカタログ化とガバナンス強化を最優先とし、移行対象データの可視化を進める。
ストリーミングデータや大量データの効率的な取り込みを実現し、リアルタイム処理能力を向上させる。
API統合やリアルタイムプロセスを活用し、SaaSアプリケーション間のデータ連携を強化する。
クラウドデータレイクやMLの導入でアナリティクスの範囲を拡大し、データ活用の柔軟性と効率性を高める。
これらのアプローチを統合することで、企業全体でのデータモダナイゼーションを推進し、ビジネスの競争力を強化します。