
データ品質の重要性:クレンジングと名寄せによる信頼性向上
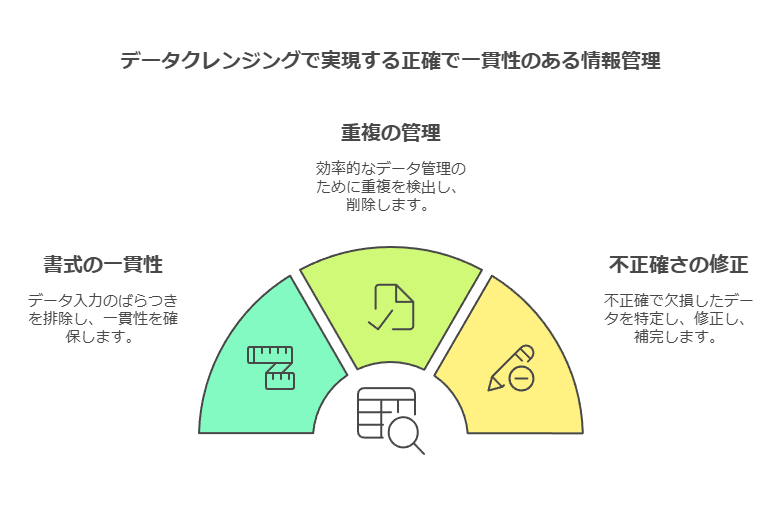
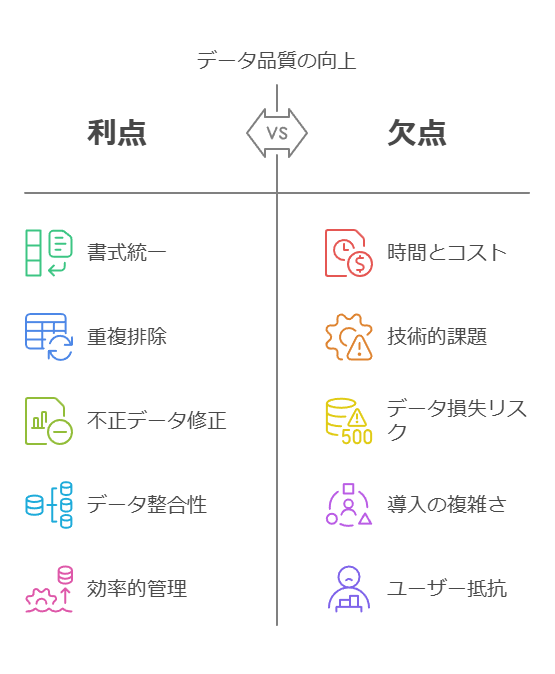
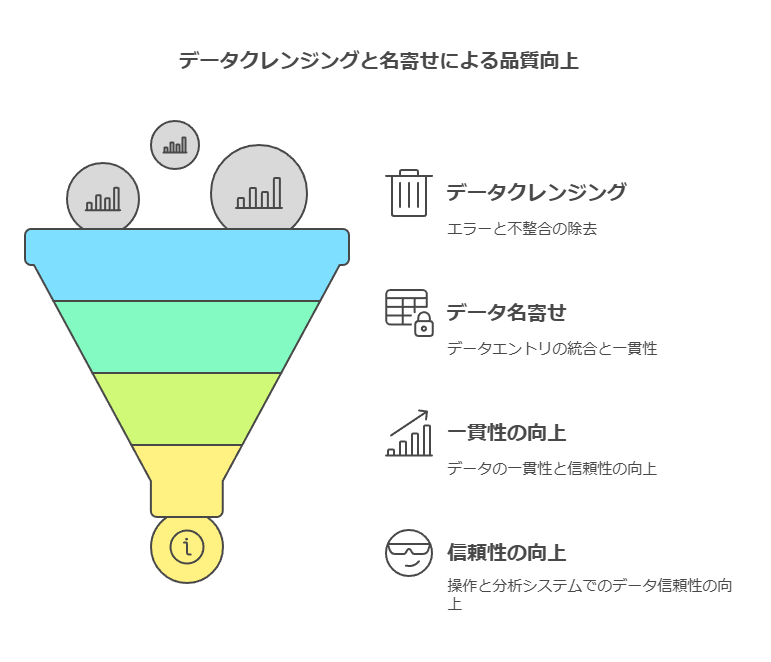
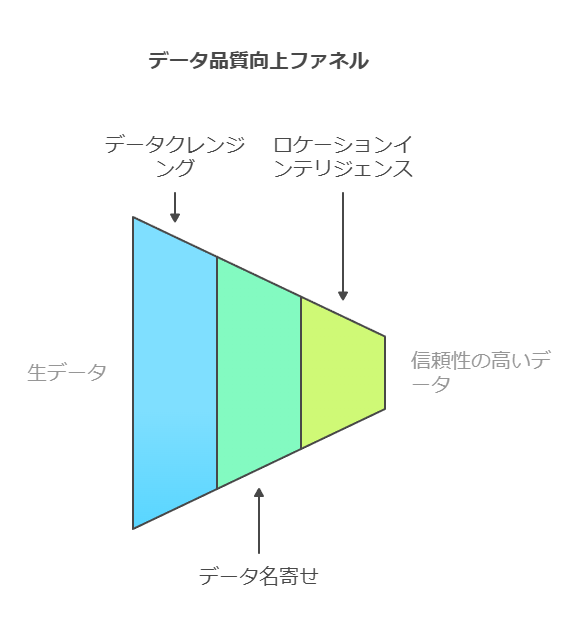
データ品質の向上は、**データクレンジング(データの整理・修正)と名寄せ(同一データの統合)**を通じて実現されます。これにより、正確で一貫性があり、運用システムおよび分析システム全体で利用可能なデータを構築することが可能です。具体的には、以下の機能が提供されます。
書式・表記の統一:データ入力時のフォーマットのばらつきを排除し、一貫性を持たせます。
重複データの判断:同一データの重複を検出し、効率的なデータ管理を行います。
不正・欠損データの特定・訂正・補完:データの欠損や不正確な値を特定し、必要な補完を行います。
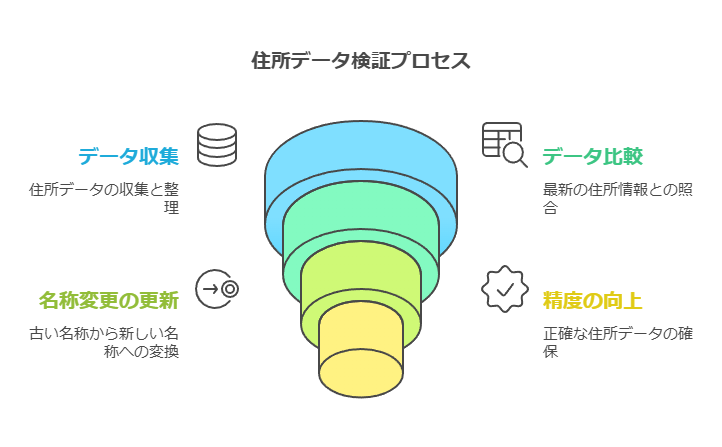
住所検証とデータ精度の向上
住所データの正確性を確保するための検証機能も重要です。最新の住所情報と比較して、入力された住所がどの程度の精度を持つか(県、市町、丁番地レベルで)を判断し、古い市区町村名から新しい住所への変換も可能です。これにより、顧客データや運用データの精度を高め、各部門が正確なデータに基づいて業務を進めることができます。
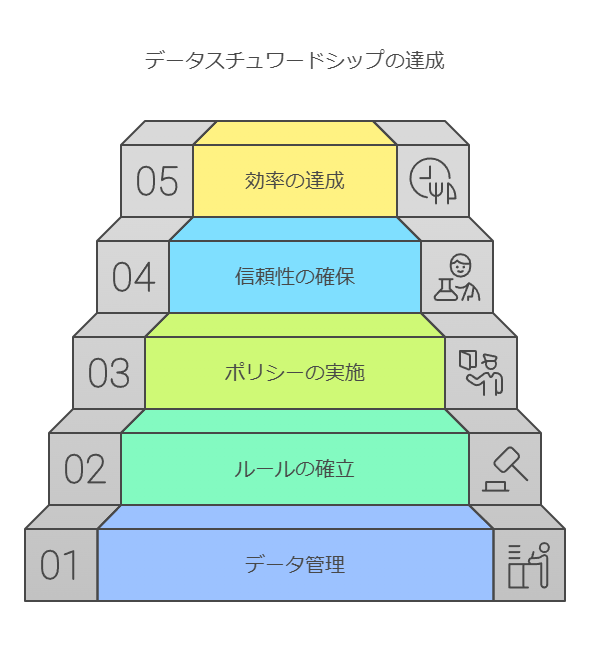
データスチュワードシップの推進
データスチュワードシップは、データの適切な定義や利用を推進する役割を担います。これにより、データの信頼性を確保し、組織全体でのデータ利用を効率化します。データの整備だけでなく、組織内でのデータ活用に関するルールや方針を徹底することが不可欠です。
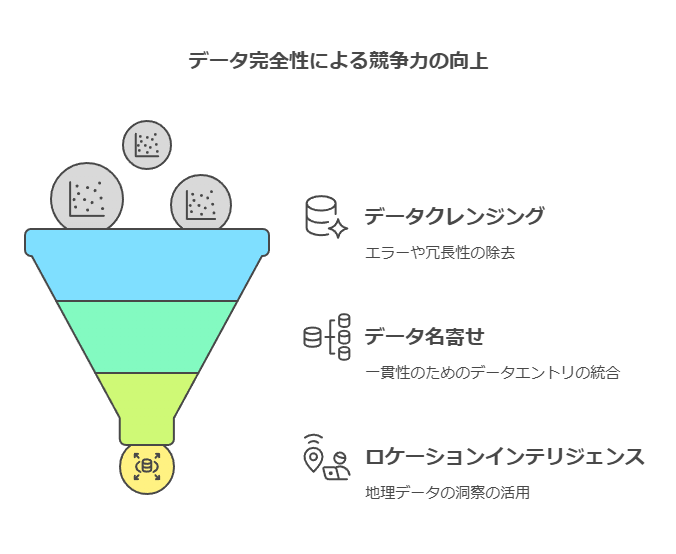
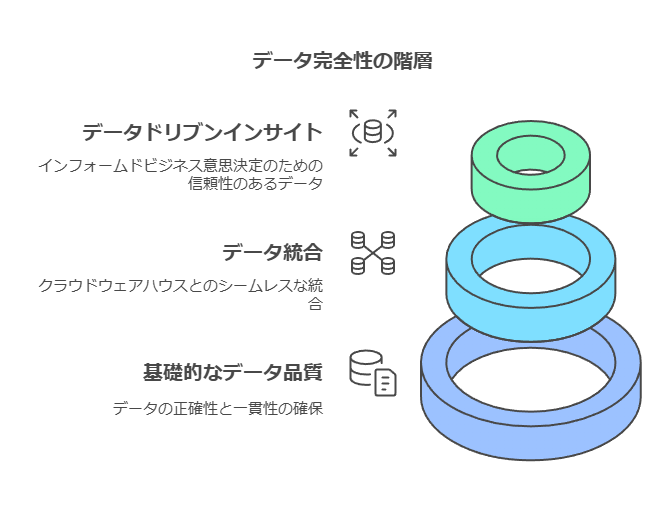
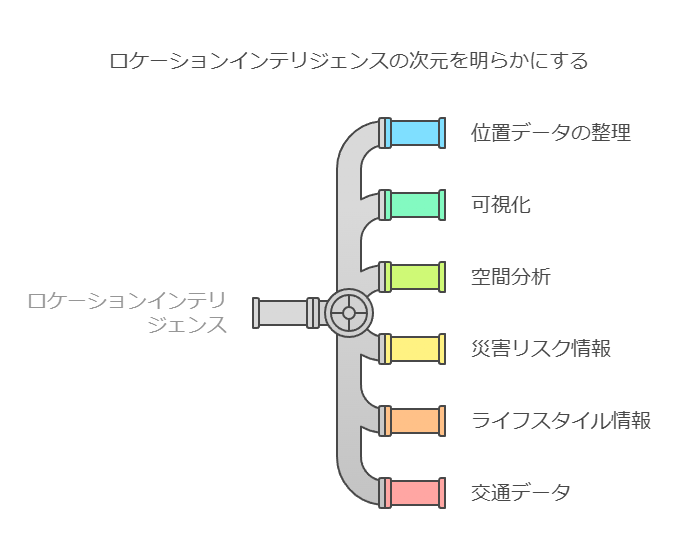
ロケーションインテリジェンスとデータ完全性の向上
ロケーションインテリジェンスは、2019年にPreciselyがGISソフトウェアを活用して実現したカテゴリーです。この技術は、ジオコーディング(地理座標の追加)を通じて位置データを整理し、地図上での可視化や空間分析を可能にします。
一見、ロケーションインテリジェンスはデータ完全性とは直接関連がないように思われますが、実際にはデータ完全性を強化するための重要な要素です。位置データに加えて、災害リスク情報やライフスタイル情報、交通・人口流動情報、時系列統計データなどを統合することで、新たな関係性や傾向を分析し、より正確な意思決定をサポートします。
データ強化とビジネスへの応用
データ強化は、最新のロケーションデータ、ビジネスデータ、消費者データを提供し、企業内のデータ資産をさらに充実させることを目指します。U.S.の場合、住所や行政区画、人口統計、道路情報など9000を超える属性や、400以上のデータセットを利用可能にすることで、企業のデータ強化を支援します。
これにより、企業は社内外のデータを統合・補完し、ビジネス戦略の策定に必要なインサイトを得られるようになります。
データ完全性の実現とクラウドプラットフォームの連携強化
Precisely Data Integrity Suiteは、データ完全性をワンストップで実現し、データドリブン型経営を支援するための包括的なソリューションです。クラウド型データウェアハウス(DWH)であるSnowflake、Amazon Web Services(AWS)、Microsoft Azureとの連携も強化されており、アップデートも進んでいます。
さらに、機能拡充を進める中で、企業が必要とするデータ管理機能を包括的に提供することが目指されています。今後も、さらなる機能強化と進化が予定されています。
結論:データ完全性の戦略的向上による競争力強化
企業がデータ完全性を高めるためには、データクレンジングや名寄せ、ロケーションインテリジェンスの活用が不可欠です。これにより、企業はデータドリブン型経営を推進し、より的確な意思決定を行い、競争力を強化することが可能になります。また、クラウドプラットフォームとの連携によって、より高度なデータ管理が実現されます。
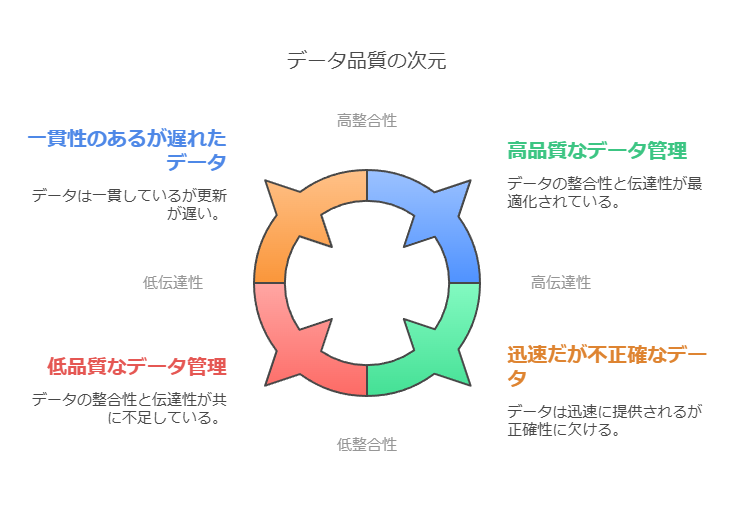
データの正確性、伝達性、整合性の重要性を強調しつつ、具体的なビジネス事例を通じて、データの品質が意思決定に与える影響を明確にしました。
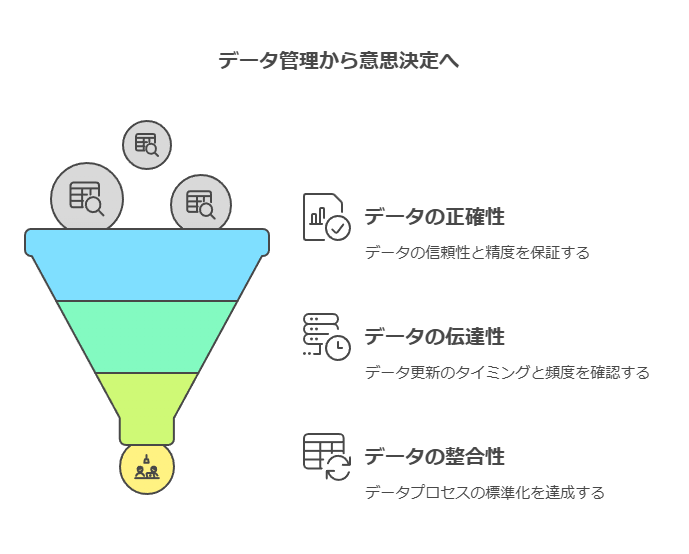
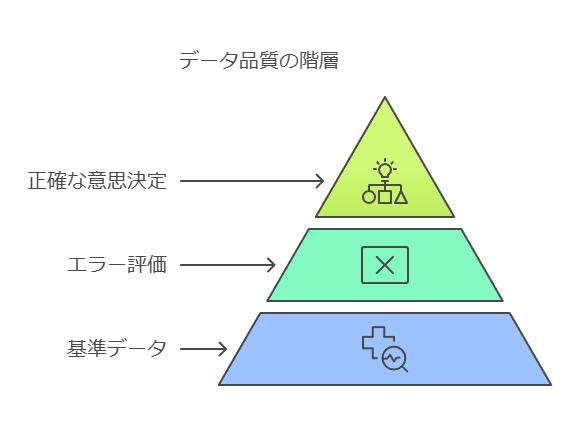
データの正確性、伝達性、整合性の確保が意思決定の鍵
企業がデータを活用する際、データ品質の3つの重要な要素である正確性、伝達性、整合性を適切に管理することが、正確で迅速な意思決定を支える要因となります。それぞれの要素に焦点を当て、データコンサルティングの視点からどのように評価し管理すべきかを解説します。
正確性:データはどの程度信頼できるか?
データの正確性は、意思決定の基盤となる重要な要素です。大規模なデータセットが社内またはサードパーティから提供される場合、統計的サンプリングを活用して、認証済みの基準データと比較し、エラー率を評価することが不可欠です。このプロセスにより、データの整合性と信頼性を高め、誤ったデータに基づくリスクを軽減します。例えば、保険会社では保険引き受け時に、不正確な住所情報や顧客データがリスクの誤評価に繋がるため、データの正確性を保証することが重要です。
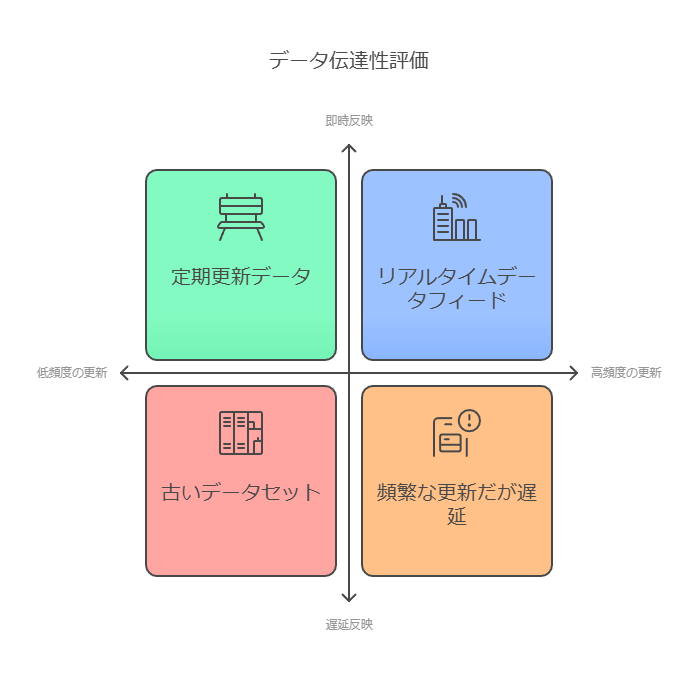
伝達性:データの更新頻度とタイミングの確認
データの伝達性とは、データセットがどの程度の頻度で更新され、どれだけタイムリーに変更が反映されるかを意味します。データが適切に更新されていなければ、古い情報に基づく意思決定が行われ、ビジネスリスクが増大します。たとえば、自然災害後に損害地域の空中写真がどのくらいのタイムラグでデータセットに反映されるのかを確認することで、迅速な対応が可能になります。また、不動産開発などでも、最新の建設状況をタイムリーに把握し、正確な保険引き受けに役立てることが求められます。
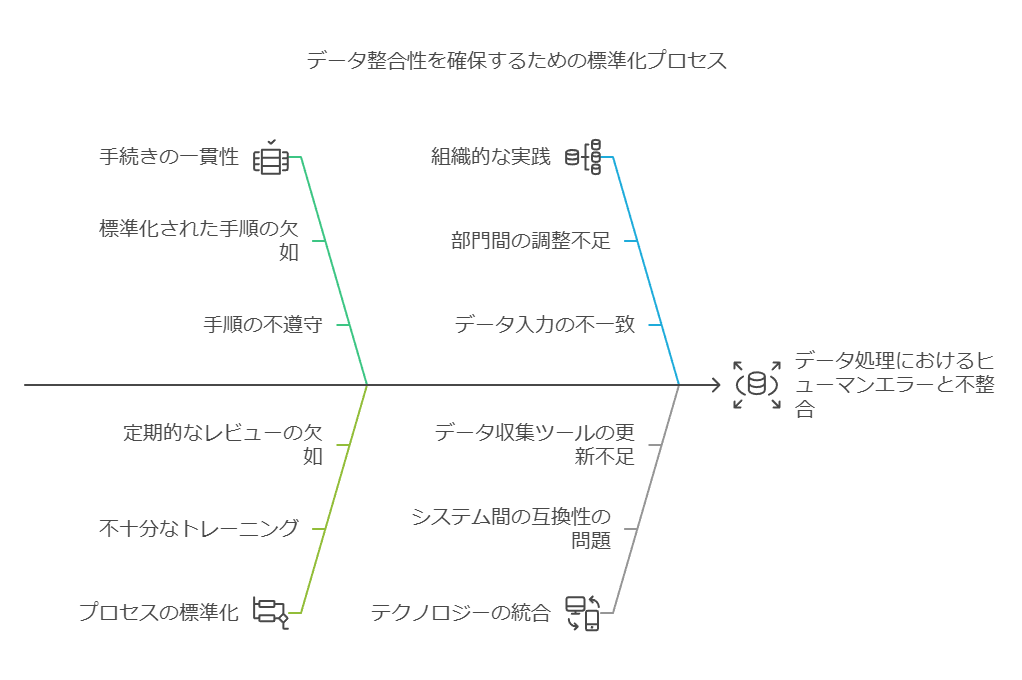
整合性:データプロセスの標準化が鍵
データの整合性を保つためには、データの入力、保管、抽出、分析のプロセスにおいて、一貫した手続きが必要です。明確に文書化された手順に基づいた標準化されたプロセスを全社で徹底することで、データ処理におけるヒューマンエラーや不整合を防ぎます。これにより、データの信頼性が向上し、データ分析結果に対する信頼も確立されます。データ管理ルールの策定と実施は、データ品質を長期的に維持するために不可欠です。
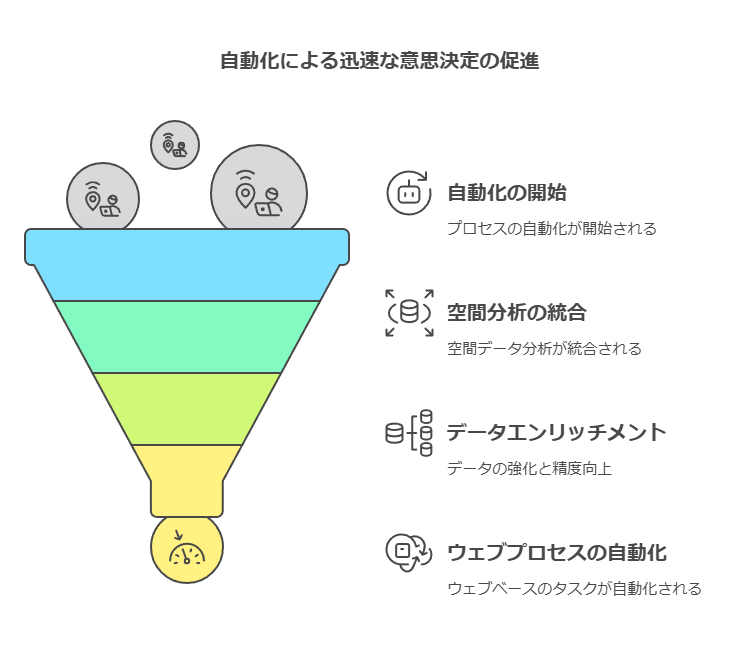
ビジネス事例:質の高いデータが保険会社の意思決定を強化
ある大手保険会社は、幅広い財産および傷害保険商品を提供する中で、保険引き受けと価格決定を効率化するために、Preciselyのジオアドレッシング、空間分析、データエンリッチメントソリューションを導入しました。これにより、ウェブベースのプロセスが自動化され、多くの場合、人的介入なしに契約が完了するようになりました。
Preciselyソリューションは、データへの迅速なアクセスと正確な意思決定をサポートし、エージェントと内部スタッフの時間を大幅に節約しました。結果として、よりスムーズな保険引き受けと価格決定が実現し、競争優位性が向上しました。
結論:データ品質の管理がビジネスの成長を左右する
データの正確性、伝達性、整合性を適切に管理することで、企業は迅速かつ正確な意思決定を行い、ビジネスの成長を促進します。データコンサルタントとして、これらの要素に焦点を当てたデータ管理戦略を導入することで、長期的なビジネスの成功を支援します。
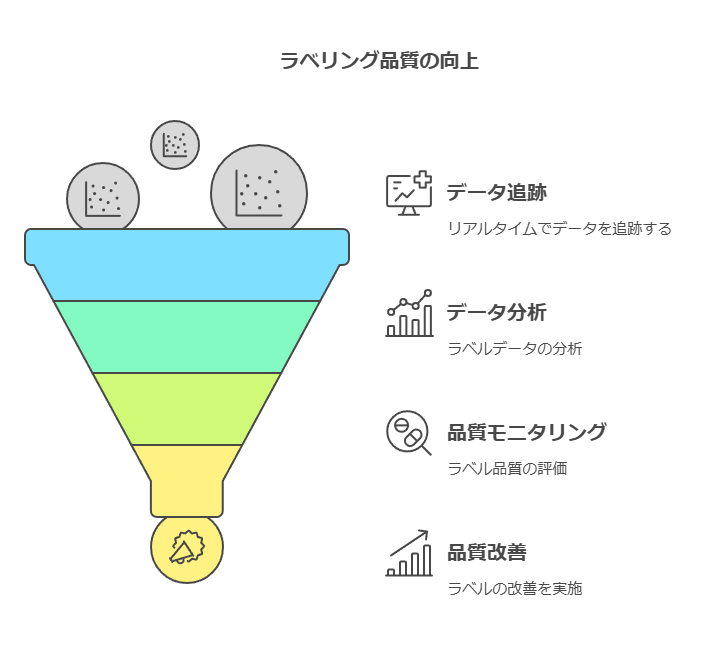
製品ライフサイクル全体を通じてラベリングの品質を向上
データに基づいたアプローチで製品ライフサイクル全体を通じてラベリングの品質を向上させます。リアルタイムのデータ追跡と分析により、ラベル品質のモニタリングと改善が可能になります。
スピードと効率を向上して初回で正しい変更管理を実現します。
データに基づいた変更管理システムを導入することで、スピードと効率を向上させ、初回で正確な変更を実現します。リアルタイムデータに基づく意思決定が可能になります。
包括的なデジタル・ソリューションを活用すると、煩雑なラベリング・プロセスを迅速で無駄のない、規制に準拠したプロセスに変えることができます。
包括的なデジタル・ソリューションにより、リアルタイムでデータを管理し、ラベリング・プロセスの煩雑さを解消します。データを活用した自動化と規制対応の効率化を実現し、無駄のないプロセスへと変革します。
SaaSのデプロイメントを介して、シーメンスの医療機器向けPLMソリューションであるTeamcenterXと統合することで、Labeling & UDIソリューションの可能性を最大限に引き出すことができます。
SaaSデプロイメントを活用し、シーメンスの医療機器向けPLMソリューション「TeamcenterX」とのシームレスなデータ統合を実現します。これにより、Labeling & UDIソリューションの可能性を最大限に引き出し、リアルタイムでのデータ活用と効率的なプロセス管理が可能となります。
シーメンスのLabeling & UDIソリューションを使うと次のことが可能です。
シーメンスのLabeling & UDIソリューションを使用することで、データ中心のアプローチを取り入れ、次の成果を達成できます。
ラベリング作業のデータ追跡を実現
設計とエンジニアリングの並列処理をデータ活用で最適化
ラベルデータの一貫性を確保し、出力までのプロセスを自動化
各市場のUDI要件に対応したデータ管理と保管を保証
このように、データの可視性と精度向上により、ラベリングプロセス全体がより効率的かつ透明性の高いものになります。
データ品質の重要性
ライフサイエンス企業は、R&D(研究開発)や臨床試験、そして日常業務を効率的に管理するために、多種多様なフォーマットで受信する膨大なリアルワールドデータ(RWD)を扱っています。これには、臨床アプリケーションや医療IoT(loMT)デバイスなどからの構造化および半構造化データが含まれます。しかし、このデータはしばしば品質に問題を抱えています。
データの課題
ライフサイエンス企業が扱うデータは「欠損値だらけ」であり、「矛盾や潜在的な偏り、ノイズが多い」と指摘されています。このようなデータは、効果的な分析を行う上で大きな障害となります。データのインジェスト(取り込み)、クリーニング、整理に多くのリソースを割いたとしても、レガシーシステムに依存している場合、短時間で高精度な分析を行い、実用的なインサイトを得ることは困難です。
データサイロ化の問題
ライフサイエンス企業のデータは、次の2つのサイロに分離されていることが多いです。
コマーシャルデータ:売上やマーケティングの記録など
規制対象データ:臨床試験結果や検査報告など
これにより、データ間の連携が阻害され、全体的な分析が難しくなるという課題があります。
データ統合による効率化
データ統合ソリューションを採用することで、ライフサイエンス企業は多様なデータセットを一元化されたデータリポジトリに統合できます。このリポジトリは、OLTPデータベース、臨床アプリケーション、loMTデバイスなどのさまざまなデータソースから、構造化および半構造化データを取り込みます。
これにより、データサイエンティストやアナリティクスチームは、自動整理ツールを用いてデータを効率的かつ迅速に分析できます。さらに、PythonやRを使用したデータクエリを実行し、機械学習を統合することも容易になります。このプロセスにより、データサイロの問題を解消し、リアルタイムでのインサイト獲得が可能になります。
組織全体でのデータ活用
データサイロを解消し、コマーシャルデータと規制対象データを一元化することで、組織全体でのデータ活用が可能になります。SASコネクターなどの統合ツールを活用することで、信頼性の高い唯一の情報源(SSOT: Single Source of Truth)にアクセスできるようになります。この統合により、データのコピーをサイロ間で移動させる必要がなくなり、リアルタイムなインサイトの取得や迅速な臨床試験のアナリティクスが可能になります。
イノベーションの加速
ライフサイエンス企業内のデータサイエンティストやアナリティクスチームは、統合されたデータリポジトリを活用し、発見から開発、製造、商品化までの製品ライフサイクル全体にわたるイノベーションを加速できます。これにより、組織の多様な分析ニーズに対応し、競争力のある市場での迅速な意思決定を支えるデータドリブンな組織が実現します。
コンサルタントの視点でのまとめ
データ品質の向上とデータサイロの解消は、ライフサイエンス企業が抱える大きな課題です。効率的なデータ統合によって、データサイエンティストが価値あるインサイトを迅速に得ることができ、製品開発や臨床試験における意思決定を加速させることが可能です。
効果的なデータ品質診断による課題解明
多くの工数をかけた調査でも解明できないデータ活用の課題要因に直面している企業向けに、RUFUの「データ品質診断」は、これらの問題を特定するための有効な手段です。この診断では、DWH(データウェアハウス)やデータ基盤に適切な形でデータが蓄積されているかを精査します。Big Query、Redshift、Snowflake、DatabricksなどのクラウドDWHを導入している企業でデータ活用に課題を感じている方は、ぜひご参加ください。
データドリブン経営に不可欠なデータ集約・可視化
経営者が迅速かつ正確な意思決定を行うためには、全社に散在するデータを集約し、リアルタイムに可視化することが不可欠です。NDIソリューションズでは、以前から経営データの活用に対するニーズがありましたが、ITリソースの不足により、その実現が困難でした。データ集約と可視化が実現すれば、迅速な経営判断が可能となります。
非IT部門主導でのデータ活用に立ちはだかる障壁
経営企画部門が主体となってデータを活用しようとする際、以下のような課題が頻発します。
データの分散: 各部門で異なるシステムを使用しているため、どこにどのデータが存在するかが把握できず、データの集約に時間がかかる。
ITスキルの不足: 経営企画部門には、データ収集や加工に必要なITスキルが不足しているため、作業が滞る。
膨大なデータ量: Excelなどの手作業では対応できない膨大なデータが存在し、これを扱うためには高度なデータ処理技術が必要。
これらの課題を解決するためには、データ基盤の強化とともに、経営企画部門でも簡単に操作できるツールの導入が必要です。
人事イベントに伴うオペレーション業務のリスク
入退社や異動の際に必要な手続きが増えることで、人事データやアカウント権限の管理が複雑化し、オペレーション業務が肥大化します。特に、退社時に適切なアカウント削除やデータ管理がなされなかった場合、重大なセキュリティリスクが発生する可能性があります。これにより、人事部門やシステム管理者の負荷が増大し、対応漏れのリスクが高まります。
スピード感ある意思決定を阻むデータ管理の問題
新しい分析視点の追加やデータソースの統合には、IT部門や外部ベンダーへの依頼が必要になるため、意思決定のスピードが低下するケースがあります。このような柔軟性とスピード感の欠如は、データドリブン経営の大きな障壁となっています。
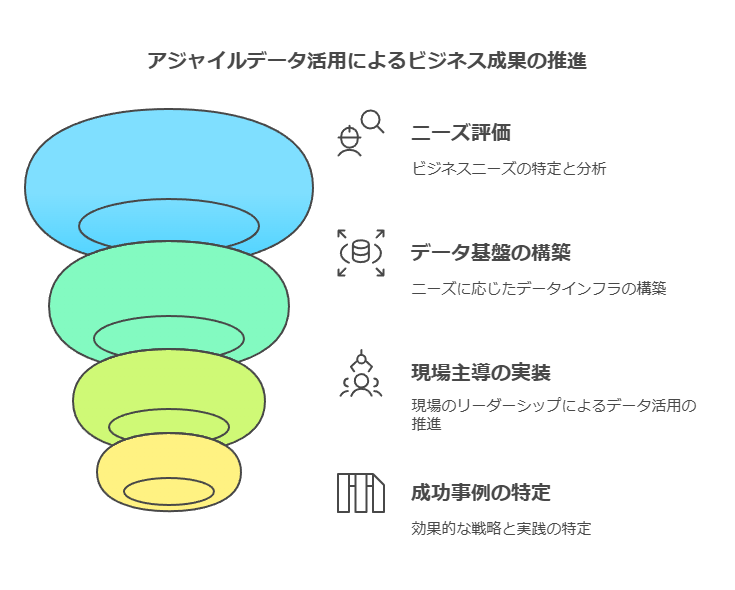
アジャイルなアプローチによるデータ活用の促進
これらの課題に対して、アジャイルなデータ活用法を採用することで、現場のニーズに即した柔軟かつ迅速なデータ基盤の構築が可能です。実際の成功事例を通じて、どのようにして現場主導でデータ活用を進め、ビジネス成果に直結させるかを具体的に解説します。また、デモンストレーションを交えて、現場で使えるデータ活用ツールの操作方法もご紹介します。
分散管理された人事データとアカウント権限管理の課題
多くの企業では、部門ごとに人事データやアカウント権限を分散管理しており、その結果、異動や出向などの際に大きな手間がかかるケースが見られます。特に、大規模な組織では、フォーマットやツールの違いが業務効率を低下させ、管理の負担を増大させています。
時系列に基づく人事データ管理によるガバナンス強化
時系列データを活用した一元的な人事・組織マスタの管理は、ガバナンス体制の強化と業務負荷の軽減に大きく貢献します。このアプローチにより、異動や退社時のデータ管理リスクを低減し、システム管理者や人事担当者の業務効率を向上させることができます。
データプレパレーションの革新とエコシステムの活用による分析基盤強化
1. Snowflakeによる効率的かつ高速なデータプレパレーション
データ活用の初期段階におけるデータプレパレーションは、分析プロジェクト全体の生産性を左右する重要なプロセスです。Snowflakeは、専用の仮想ウェアハウスを通じて、SQLを用いた効率的なデータの取り込み、変換、クエリ実行環境を提供します。このアーキテクチャは、他のユーザーや部門のワークロードからの影響を排除し、安定したパフォーマンスを確保します。
SnowflakeのSQLは、特定のケースにおいてApache Sparkなどの分散処理フレームワークと比較しても、データプレパレーションの処理効率で優位性を示すことが報告されており、機械学習(ML)タスク実行前のデータ準備にかかる時間を大幅に短縮します。これにより、分析サイクルの遅延を緩和し、より迅速なインサイト獲得と意思決定を支援します。
2. 充実したパートナーエコシステムによる柔軟なツール選択
Snowflakeは、確立された主要なデータサイエンス技術から最新の新興技術まで、広範なツール・サービスとの接続性を確保しています。この充実したパートナーエコシステムにより、企業は特定のニーズや既存環境に合わせて最適なデータサイエンスツールを選択し、それらをSnowflakeという一貫性のある統合データプラットフォーム上で連携させることが可能です。
さらに、SnowflakeはAWS S3をはじめとする各種ストレージサービスへのシームレスなデータエクスポート機能を有しており、あらゆるデータサイエンスツールからのユニバーサルなアクセスを実現します。これは、データサイロを解消し、組織横断的なデータ活用と高度な分析環境の構築を促進します。
企業ポータルの情報活用における課題とパーソナライゼーションによる解決
大規模な組織において、社内ポータルや取引先・パートナー向けポータルは、情報の一元管理、効率的な情報共有、業務プロセスの標準化、部門間コミュニケーションの活性化といった目的で導入されます。しかしながら、利用者の増加やコンテンツの肥大化に伴い、以下のような課題が生じることが少なくありません。
情報過多と探索性の低下: 大量の情報が流通する結果、個々の利用者が必要な情報へ迅速にアクセスすることが困難になる。
ナビゲーションの複雑化: ポータルの構造が複雑化し、直感的でないインターフェースが利用者のストレスや非効率性を招く。
これらの課題は、ポータル本来の目的達成を阻害し、生産性の低下に繋がりかねません。
パーソナライゼーション導入の戦略的メリット
上記のようなポータルにおける情報活用の課題に対し、データに基づいたパーソナライゼーションの導入は極めて有効な解決策となります。
情報アクセシビリティの向上: 利用者一人ひとりの属性、役割、関心事、利用履歴などに基づいて最適化された情報を提供することで、必要な情報へのアクセス時間を大幅に短縮し、業務効率を向上させます。
ユーザーエンゲージメントの強化: 関心の高い情報やツールが優先的に表示されることで、利用者のストレスを軽減し、ポータルの利用満足度と活用頻度を高めます。
組織全体の連携と生産性向上: 各部門やチームのニーズに合わせたポータル環境を構築することで、部門内および部門間の情報共有と連携を強化し、組織全体の業務効率と生産性の向上に貢献します。
データドリブン・ポータル実現事例:Liferay DXPによる価値創出
パーソナライズされたポータル運用を実現するソリューションとして「Liferay DXP」は注目に値します。HPE社や郵船ロジスティクス社といったグローバル企業における活用事例は、ポータルを通じた業務効率化と生産性向上の具体的な道筋を示しています。
これらの事例から得られる主なポイントは以下の通りです。
役割ベースのコンテンツ配信: 利用者の役割や権限に応じて表示コンテンツを動的に変更し、情報へのアクセス権限と関連性を最適化。
アクセスログ分析とインサイト活用: 大規模ポータルにおける利用状況を詳細に分析し、コンテンツの利用頻度、検索キーワード、ナビゲーションパスなどを把握。
データに基づくユーザーターゲティング: 分析結果を基にユーザーセグメントを作成し、各セグメントに対して最適な情報や機能を提供することで、エンゲージメントを最大化。
これらのアプローチは、特に大規模組織特有の社内ポータル運用課題の解決に寄与し、情報活用のROIを最大化します。ポータルの利便性や活用効果に課題を感じている組織にとって、データドリブンなパーソナライゼーションは検討すべき重要な戦略です。
データ品質とデータ統制:信頼性の高いデータ活用の基盤
あらゆるデータ戦略の成功は、その根幹を成すデータの品質に大きく依存します。データ品質が担保されていなければ、分析結果の信頼性が損なわれ、誤った意思決定を導くリスクが生じます。
Qlik Talendなどのデータ統合・品質管理ソリューションは、以下のような領域で高品質なデータを確保し、ビジネス価値を創出するためのユースケースを提供します。
データ分析: 高品質なデータは、正確かつ信頼性の高い分析結果の基盤となり、より深い洞察と的確な予測を可能にします。
カスタマーリレーションシップ管理 (CRM): 正確で最新の顧客データは、顧客理解を深化させ、パーソナライズされた体験やプロアクティブな顧客サービスの提供を支援します。
リスク管理: 信頼できるデータは、潜在的なリスク要因の早期特定、影響評価、そして効果的な軽減策の策定を可能にし、事業継続性を高めます。
マーケティング: 精緻なデータに基づくセグメンテーションとターゲティングは、マーケティングキャンペーンの効果を最大化し、ROIを向上させます。
財務レポート: 誤りのない正確なデータは、規制遵守はもとより、経営判断に不可欠な信頼性の高い財務レポート作成の前提となります。
効果的なデータ統制(データガバナンス)体制の下でデータ品質を維持・向上させることは、持続的なデータ活用と競争優位性の確立に不可欠な取り組みです。
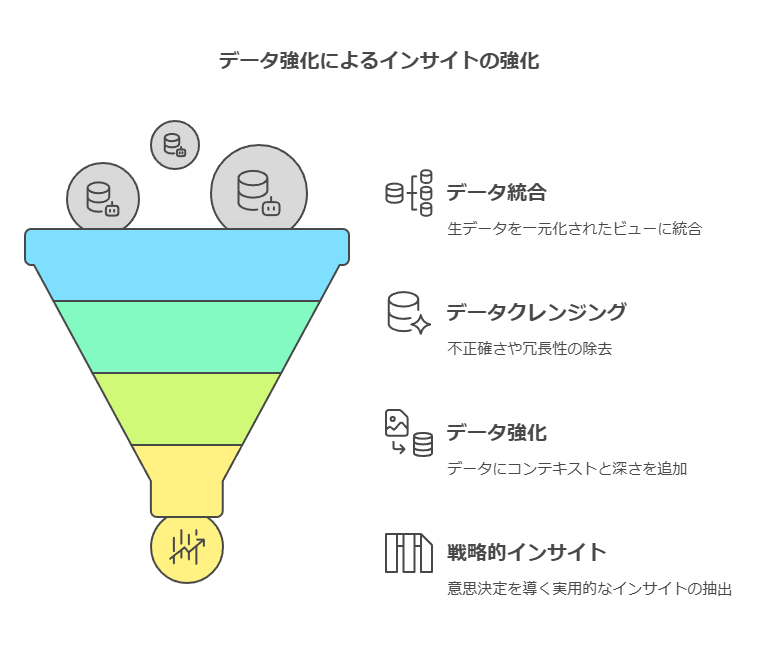
データエンリッチメントによる意思決定の高度化
企業が保有する内部データに外部データを組み合わせるデータエンリッチメントは、より深い洞察を引き出し、情報に基づいた的確な意思決定を実現するための鍵となります。PreciselyIDは、Preciselyが提供する400以上のデータセット、9000以上の属性を含む広範なデータカタログへのアクセスを容易にし、迅速なデータエンリッチメントを可能にします。
これらのデータセットには、郵便番号境界、国勢調査情報、世界の行政境界、主要な観光名所、建物の詳細属性、ジオデモグラフィック情報、さらには気象データ、洪水・火災リスク境界といった多岐にわたる情報が含まれています。これらの外部データを活用することで、例えば、顧客セグメンテーションの精度向上、商圏分析の深化、リスク評価の高度化、新規市場機会の特定など、多角的な分析と戦略策定が可能となり、データ駆動型のオペレーション最適化を促進します。
データ完全性確立への戦略的アプローチ:Precisely Strategic Services
データ完全性の確保は、データ資産価値を最大化し、データドリブンな経営を実現するための基盤ですが、その推進方法や優先順位付けに課題を抱える企業は少なくありません。Precisely Strategic Servicesは、このような課題に対応するため、カスタマイズされたコンサルティングサービスを提供し、データ活用の成熟度向上を支援します。
提供されるサービスには以下が含まれます。
データ完全性に関わるビジネスイニシアチブの明確化: 企業のビジネス戦略と連携したデータ活用目標を設定します。
KPIとビジネス目標に整合するデータプログラムの策定: 具体的な成果指標(KPI)に基づき、実効性の高いデータ活用プログラムを設計します。
戦略的ガイダンスと実行支援によるプロジェクト推進: 策定したプログラムの実行段階において、専門的な知見と実務的なサポートを提供し、プロジェクトの成功を確実にします。
全社的なデータ管理プログラムの構築と改善: 組織横断的なデータガバナンス体制の確立と、その継続的な改善を支援します。これには、専門家による現状評価と具体的な改善策の提示が含まれます。
特に保険業界においては、業界特有の課題や規制に対応した深い専門知識が求められます。Preciselyのデータプリンシパルは、保険分野における豊富な知見を活かし、データ投資効果の最大化を支援します。
イノベーションを追求し、データ主導型への変革を目指す保険業者にとって、データ完全性の確立は、急速に変化する市場環境への適応力と持続的成長を支える重要な要素です。データ品質向上の取り組みは、将来への戦略的投資として、早期に着手することが推奨されます。
空間分析:位置情報から新たなビジネス価値を創出する
地理情報は、現代社会においてスマートフォンや地図アプリケーション、フィットネストラッカーなどを通じて日常的に活用されています。ビジネスの領域においても、「位置」に関する正確な理解は、特に保険業界のような分野では、引受査定の精度向上、災害発生時の迅速な被災状況把握と対応、地域特性に応じた商品開発、不正請求の検知など、多くの重要な業務領域で不可欠な要素となっています。
しかしながら、地理空間データの潜在的な価値への期待が高まる一方で、その分析・活用は高度な専門性を要します。独自の空間分析機能を効果的に扱うには、専門的なスキルセットや知見が求められますが、これらのリソースが不足しているケースは少なくありません。最近のForresterの調査によれば、ビジネスリーダーの52%が、ロケーションインテリジェンスをより効果的に活用するために必要な専門技術や知識が自社に不足していると回答しており、この分野における課題の大きさが浮き彫りになっています。このギャップを埋めるための戦略的なアプローチとソリューションの導入が、空間分析による価値創出の鍵となります。
データガバナンスとデータ品質:信頼性の高いデータ活用基盤の構築
データドリブンな意思決定とビジネスイニシアチブの成功は、信頼性と有用性の高いデータに大きく依存します。インフォマティカが提供するデータガバナンスおよびデータ品質管理ソリューション群は、Snowflakeデータクラウド上に構築された企業データに対して包括的なガバナンスプログラムを適用し、その価値を最大限に引き出すことを支援します。
Snowflakeデータクラウドの戦略的活用を促進する主要機能は以下の通りです。
データガバナンス: データのビジネスコンテキスト(意味、目的、関連性)を明確化し、関連するプロセス、ポリシー、データオーナーシップを定義します。これにより、技術的な専門知識を持たないビジネスユーザーでもデータを容易に理解し、適切にアクセスできる環境を整備します。
データ品質管理: データ品質に関する評価指標(KPI)を設定し、スコアカードを通じて継続的に測定・監視します。これにより、データの正確性、完全性、一貫性などを維持・向上させ、分析結果の信頼性を担保します。
データカタログ: 組織内に存在するデータ資産(スキーマ、テーブル、列、ビジネス用語など)を網羅的に把握し、その定義、構造、来歴、関連性を可視化します。これにより、データ探索の効率化とデータ理解の深化を促進します。
データプライバシーとコンプライアンス: データプライバシーポリシーの適用、潜在的な情報漏洩リスクの特定と報告、データ主体からの要求(DSR)への対応、そして万が一の侵害発生時の影響分析といった機能を実行し、規制遵守とデータセキュリティを強化します。
データマーケットプレイス: 組織内のあらゆる従業員が、一貫性があり、適切に管理されたデータに対して、容易かつ広範にアクセスできるセキュアな環境を提供します。これにより、データサイロを解消し、全社的なデータ活用とコラボレーションを加速します。
データ戦略:潜在価値を引き出すダークデータの戦略的活用
効果的なデジタルトランスフォーメーション(DX)の推進は、組織内に存在するあらゆるデータを明確に理解し、戦略的に活用することが前提となります。多くの企業システムには、日常業務の中で生成・蓄積されながらも、十分に活用されていない「ダークデータ」が大量に存在します。これらは技術系システム(ログ、センサーデータ等)とビジネス系システム(過去の取引記録、顧客対応履歴等)の双方で発生し、必要な時に組織内で利用できるよう整理し、一元的にアクセス可能にする必要があります。
ダークデータには、サービス中断への迅速な対応、顧客体験の向上、新たな収益機会の発見といった、ビジネス改善に繋がる貴重なインサイトが埋もれています。その主な発生源としては、モバイルアプリケーション、マイクロサービスアーキテクチャ、IoTデバイス(例:モバイルPOS)、クラウド監視ツール、システム統合時のデータフィードなどが挙げられます。これらの多様なデータソースからリアルタイムでデータを収集・分析・活用できるデータプラットフォームを構築することは、クラウド導入の効果を最大化し、変化の速い市場環境における競争優位性を確立する上で不可欠です。
データレイクとデータウェアハウスの戦略的導入:SnowflakeによるEDW構築とELTアーキテクチャ
Snowflakeの最も一般的な活用シナリオの一つは、エンタープライズデータウェアハウス(EDW)としての利用です。EDWは、高度なアナリティクスやビジネスインテリジェンスを実行するための戦略的なデータストアとして機能します。クラウドデータウェアハウス(CDW)においては、多くの場合、ディメンショナルモデル(スタースキーマ、スノーフレークスキーマ等)を用いてデータが格納されますが、ユースケースに応じてデータボルトや運用データストア(ODS)といった他のモデリングアプローチも採用可能です。本稿では主にディメンショナルデータウェアハウスを前提としますが、後述するプラクティスの多くは他のモデルにも適用できます。
CDWに格納されたデータは、その上位に位置するレポーティングツールやアナリティクス製品から容易にアクセス可能である必要があります。そのため、CDWへのデータロード前には、複数のソースシステムからデータを抽出し、統合、変換、クレンジング、標準化といった一連のデータ準備プロセスが不可欠です(これは、データレイクに存在する生データと、CDWに格納される加工済みデータの重要な違いです)。
このデータ準備プロセスを効率化し、Snowflakeの処理能力を最大限に活用するためには、従来のETL(Extract, Transform, Load)アプローチではなく、ELT(Extract, Load, Transform)アプローチの採用を推奨します。具体的には、以下の2段階のプロセスでデータロードを実行します。
ステージング層へのロード: ソースシステムから抽出したデータを、可能な限り変換処理を施さずに(あるいは最小限の変換で)、Snowflake内のステージング層(またはランディング層)に迅速にロードします。インフォマティカのCloud Mass Ingestionのようなツールは、この一括ロード処理を効率的に実行するのに役立ちます。
後続層への変換・ロード: ステージング領域にロードされたデータを基に、必要なデータ変換、クレンジング、ビジネスロジックの適用を行い、分析・レポーティングに適した形式で後続のデータマート層やキュレーション層にロードします。Snowflakeの強力なコンピュートエンジンは、この変換処理を高速に実行します。
このELTアーキテクチャは、データロードの迅速化、変換ロジックの柔軟性向上、そしてデータレイクとデータウェアハウスのシームレスな連携を実現し、アジャイルなデータ活用基盤の構築に貢献します。