
目次
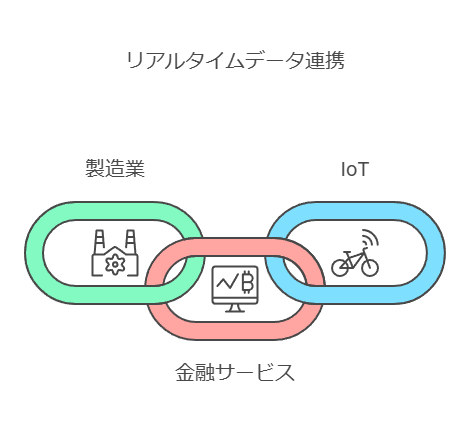
リアルタイムデータ連携の重要性と選定のポイント
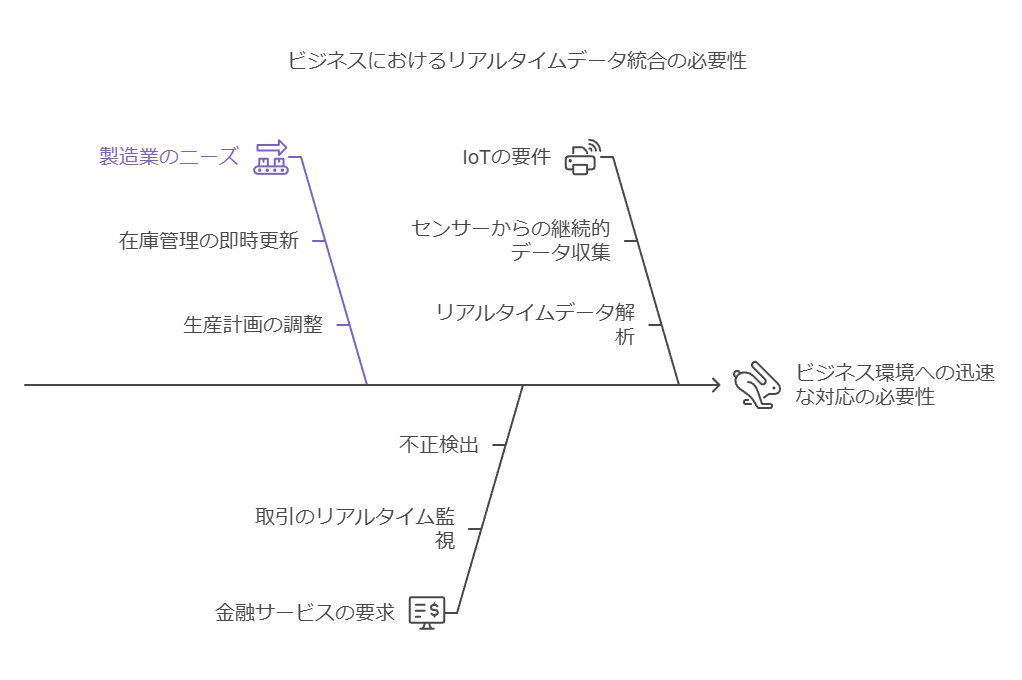
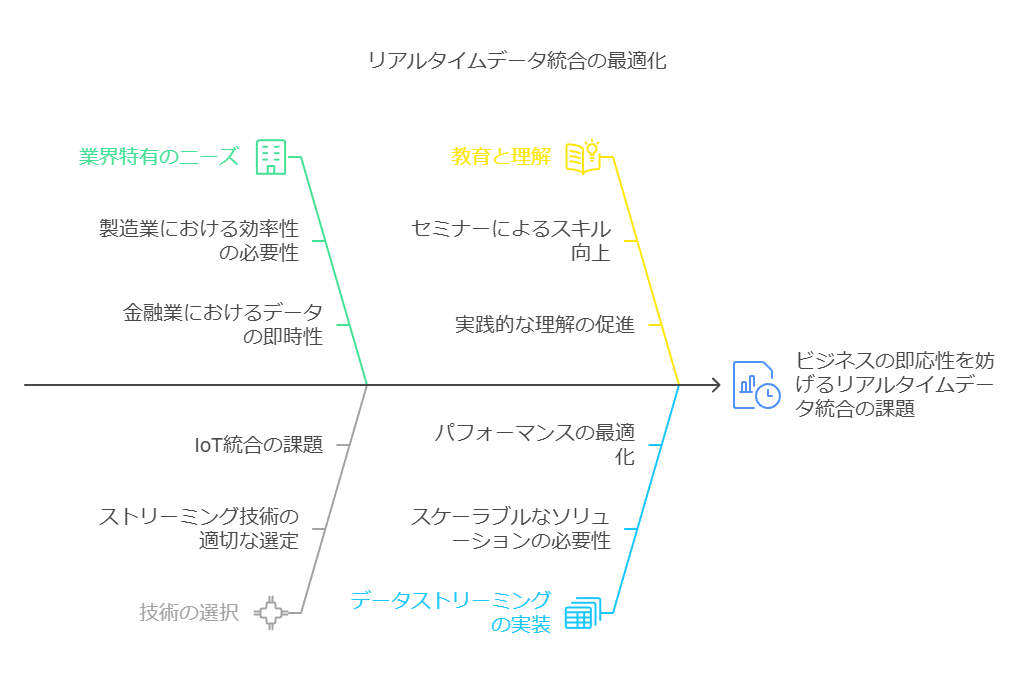
リアルタイムデータ連携が求められる背景
近年、ビジネス環境の変化に迅速に対応するためのデータ活用がますます重要視されています。これに伴い、システム間でリアルタイムにデータを連携させるニーズが急増しています。
リアルタイム連携が特に重要とされる分野の例を挙げると以下の通りです:
製造業:在庫管理や生産計画の即時反映。
金融業界:取引モニタリングや不正検知。
IoT:センサーからのデータ収集とリアルタイム解析。
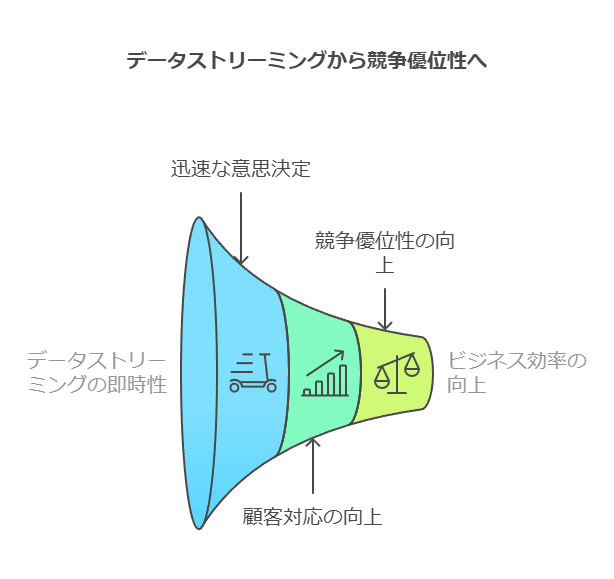
これらの分野では、データの即時性が業務効率化やパフォーマンス向上の鍵を握ります。適切にデータ連携が実現されれば、迅速な意思決定や顧客対応が可能となり、競争優位性を高めることができます。しかし、その実現には遅延のないデータストリーミングが不可欠です。
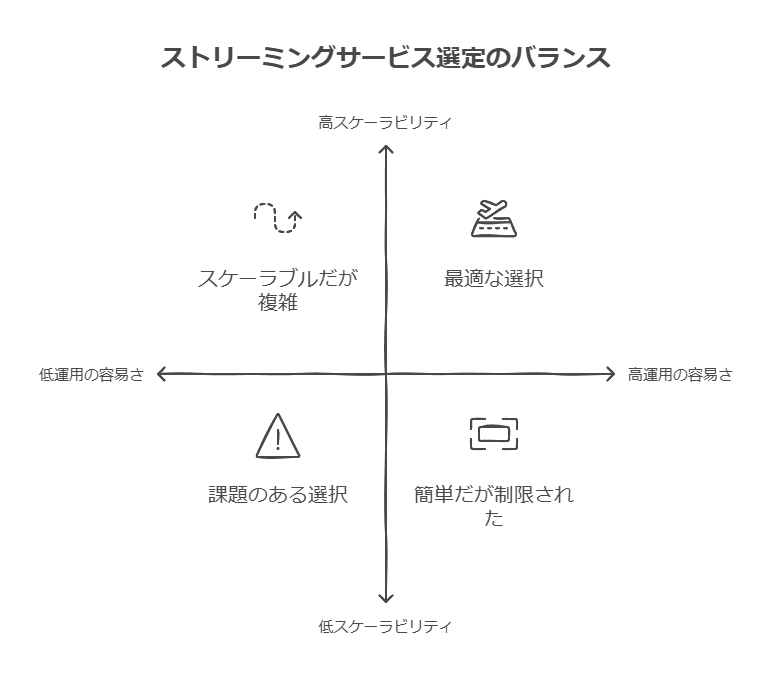
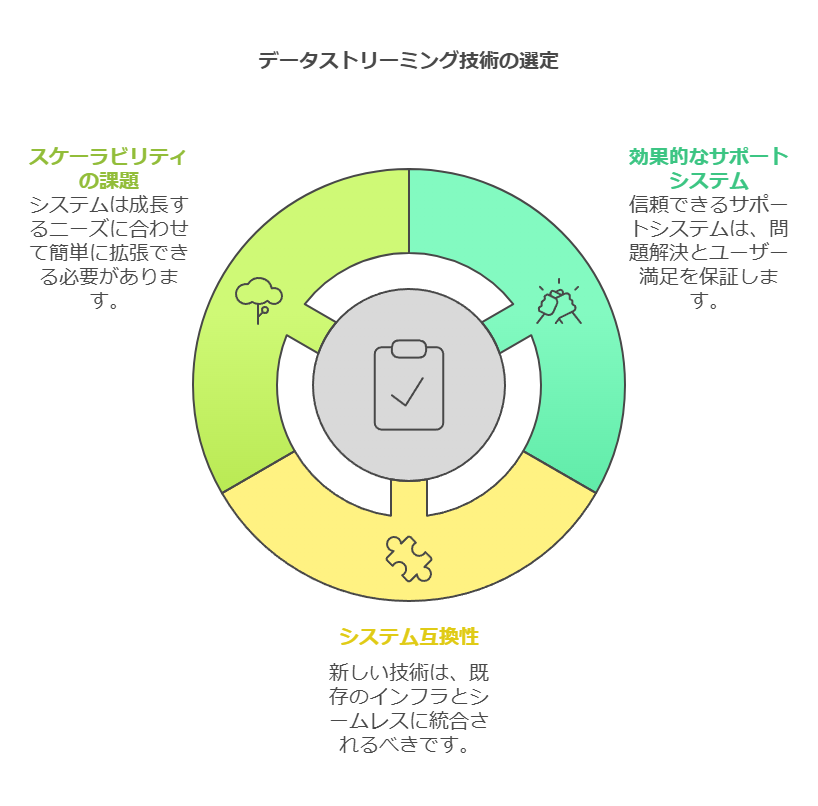
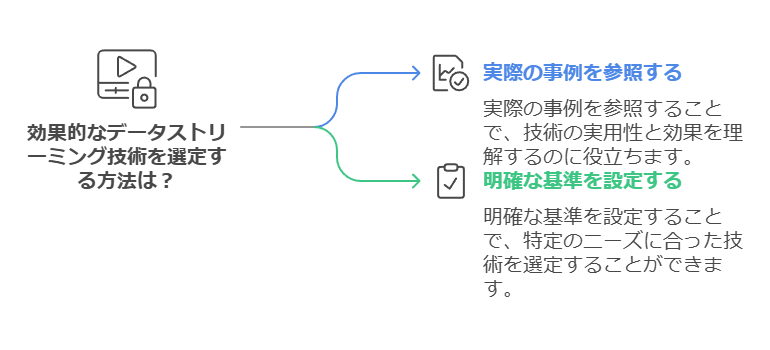
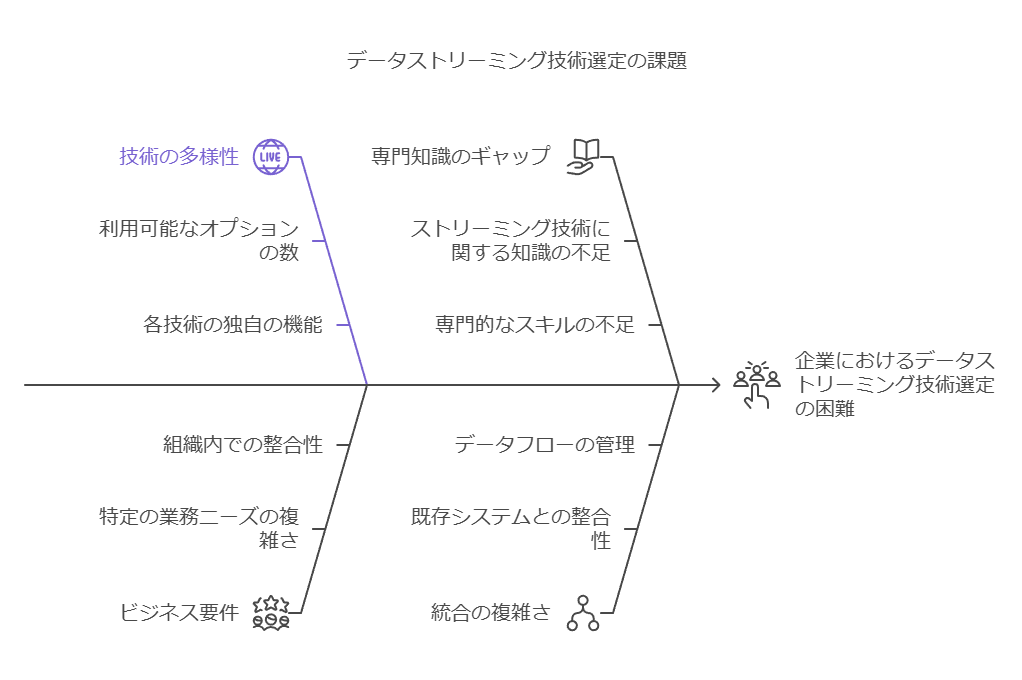
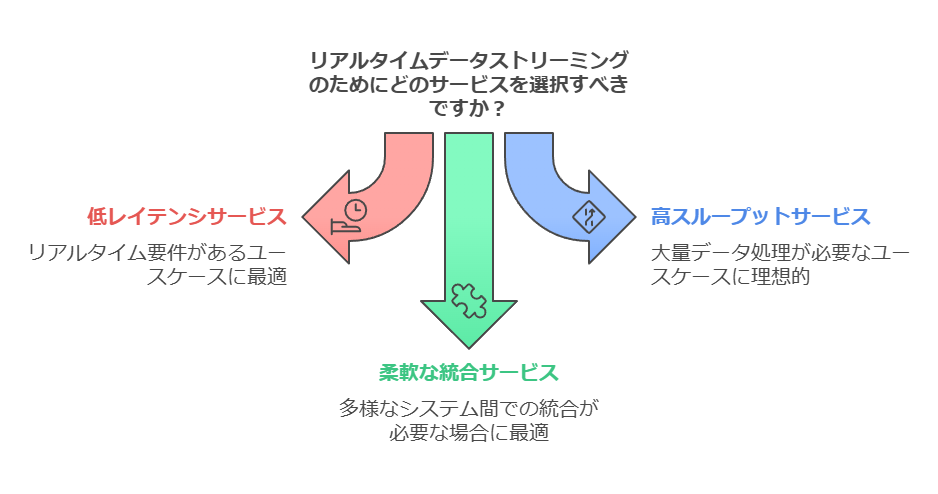
データストリーミング技術の選定における課題
多様なデータストリーミング技術が市場に出ている中で、以下のような課題に直面している企業も少なくありません:
何を基準に選べば良いかわからない
ストリーミングサービスの特徴や機能は各製品で異なり、自社に適したものを見極めるのが難しい。
例えば、データ量、システム連携の複雑性、リアルタイム性の要求度など、業務要件に応じた適切な基準設定が必要。
運用の容易さとスケーラビリティ
初期構築の容易さだけでなく、運用コストやシステム拡張時の対応力も重要。
サポート体制や互換性
導入後のトラブル対応や既存システムとの親和性が選定の鍵となる。
これらの課題を解消するためには、実際の活用事例を参考にしながら選定基準を明確にすることが重要です。
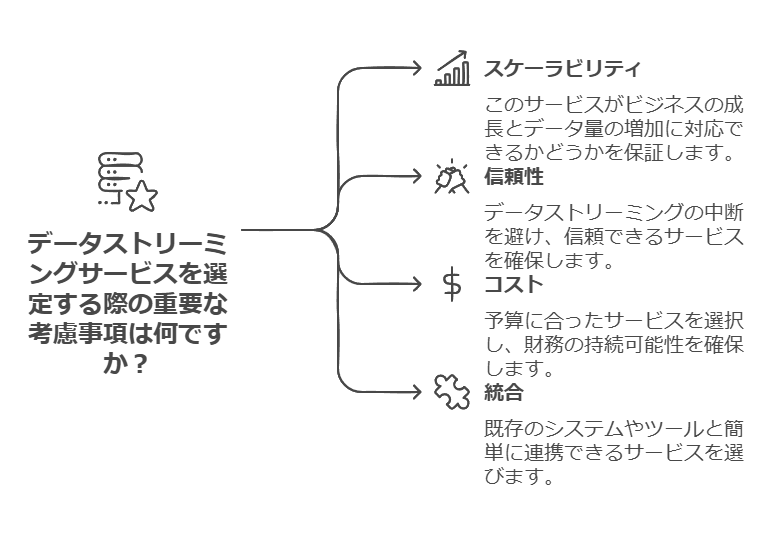
セミナー内容:ConfluentとGoogle Cloudによる具体的な解決策
データストリーミングサービスを選定する際の具体的なポイントを検討するとともに、以下のようなテーマを中心に確認します:
選定基準の明確化
業種や用途に応じた最適なサービス選定の方法を分かりやすく解説。
例:リアルタイム性が求められるユースケースでは、低レイテンシを重視した選択肢が重要。
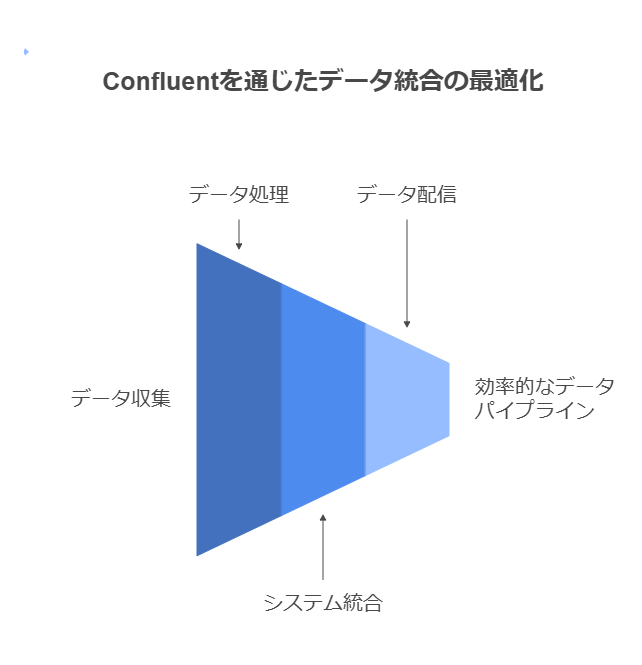
Confluentを活用したリアルタイムデータ連携
KafkaベースのプラットフォームであるConfluentを利用し、データの収集、処理、配信を効率化する方法。
他システムとの連携事例やデータパイプラインの構築方法を具体的に解説。
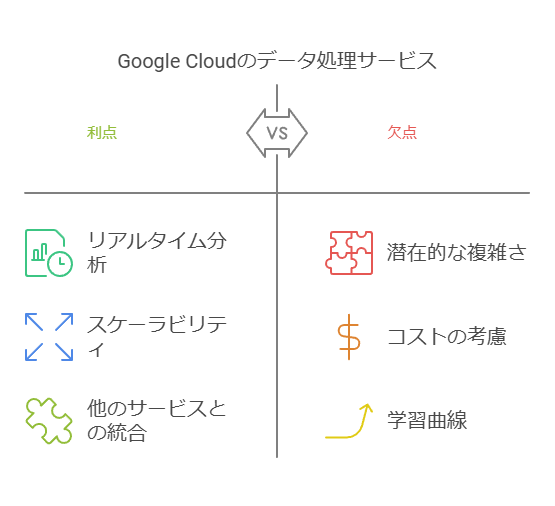
Google Cloudとの連携によるさらなる利便性
Google Cloudのデータ処理サービス(BigQueryやDataflowなど)と組み合わせたユースケースを紹介。
大量データのリアルタイム分析やスケーラブルなクラウド環境での運用のメリットを明らかに。
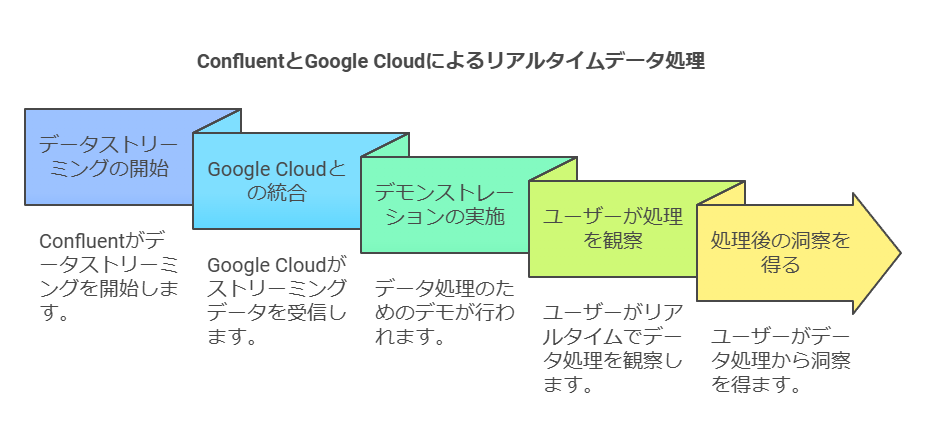
デモンストレーションによる実践的な理解
ConfluentとGoogle Cloudの連携によるリアルタイムデータ処理の流れを実演。
実際の操作画面や設定例を通じて、導入後のイメージを掴むことができます。
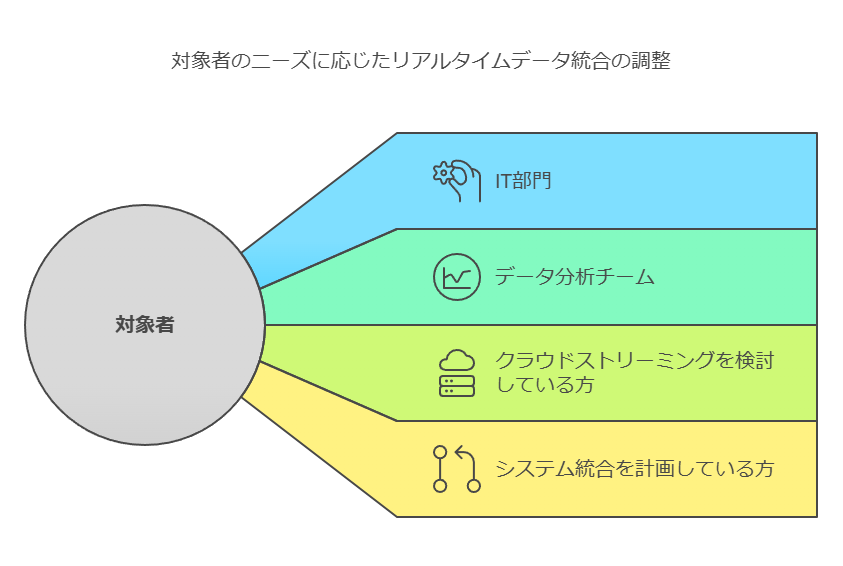
対象者と得られるメリット
対象者
リアルタイムデータ連携が求められる業務に携わるIT部門やデータ分析チームの方。
クラウド環境でのデータストリーミングを検討している方。
既存システムの統合や新規システム導入を計画している担当者。
検討のメリット
自社の業務課題に応じたストリーミング技術の選定ポイントが明確になる。
実際のユースケースを基に、自社での活用イメージを具体化できる。
リアルタイムデータ連携による業務効率化や迅速な意思決定の実現方法を学べる。
ぜひこの機会に、データストリーミング技術の活用可能性を深め、自社の課題解決に向けた第一歩を踏み出してください。

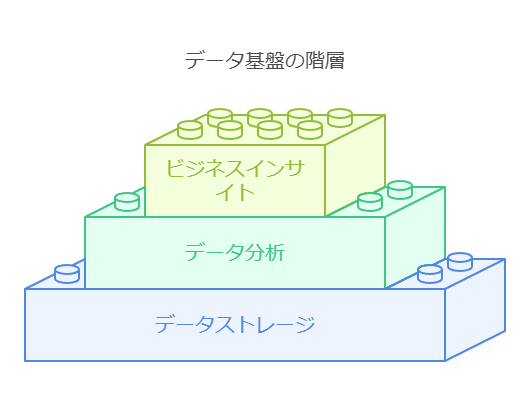
包括的なデータ基盤の必要性とその構成要素
包括的なデータ基盤の構築は、データ分析とデータストレージを効率的に統合することで、ビジネスインサイトの最大化を目指します。特に、データウェアハウスを活用することで、高度な基盤モデルや運用データを必要とするユースケースの実現が可能です。
具体例: 基盤モデルのカスタマイズ
自然言語クエリを用いて、ビジネスデータに関する深いインサイトを提供する基盤モデルや大規模言語モデル (LLM) の構築が代表例です。これにより、経営層やオペレーションチームは、迅速かつ的確な意思決定を支援するデータ活用が可能となります。
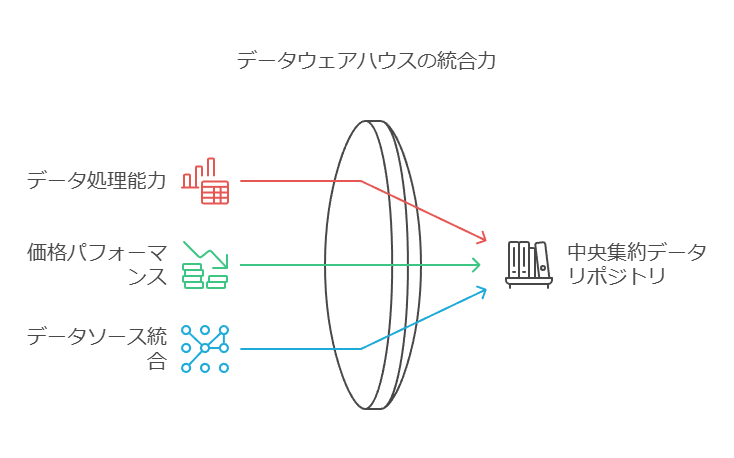
活用ツール: Amazon Redshift の優位性
高速かつスケーラブルなデータウェアハウスである Amazon Redshift は、ペタバイト規模のデータ処理において優れた性能を発揮します。他のクラウドデータウェアハウスと比較して最大6倍の価格パフォーマンスを誇り、Amazon S3やAmazon Auroraといった主要なデータソースと直接統合が可能です。これにより、広範囲なデータの利活用を一元化できます。
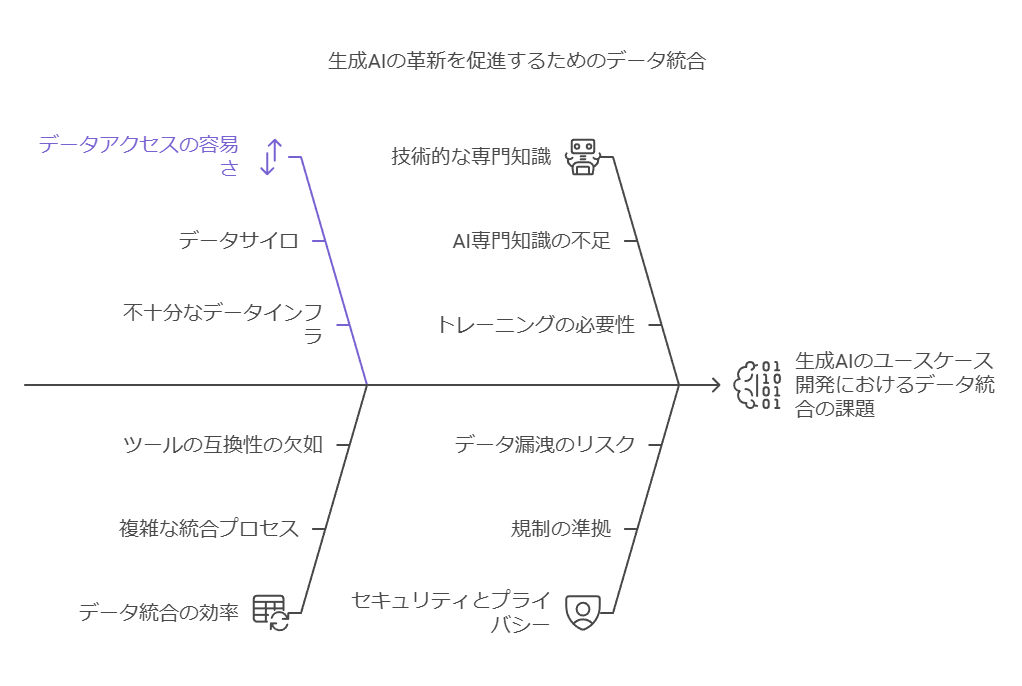
データ統合の重要性と実現方法
企業が生成AIをファインチューニングし、革新的なユースケースを開発するためには、データを効果的に連携し、容易にアクセス可能な方法を確立する必要があります。
(参考: 「生成 AI について CEOが知っておくべきこと」McKinsey Digital, 2023年)
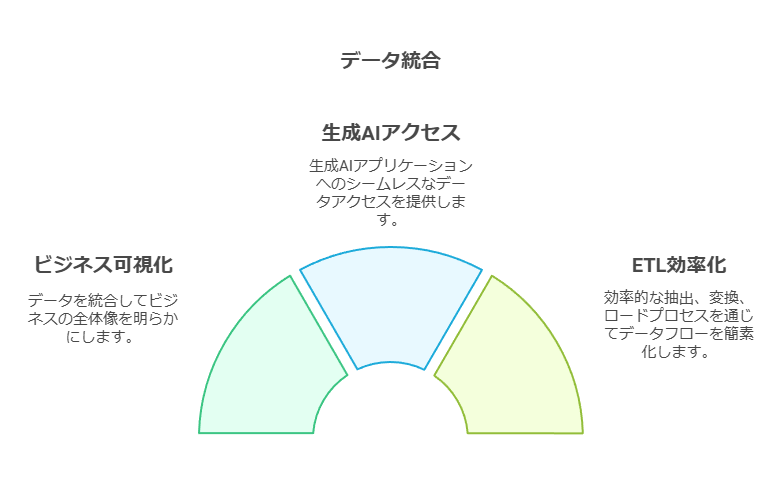
統合の価値: ビジネス全体像の把握
データ統合により、ビジネスの全体像を可視化し、生成AIアプリケーションがデータに容易にアクセスできる環境を構築します。AWSが提供するサービス間の直接統合は、抽出・変換・ロード (ETL) プロセスを効率化し、チームの迅速な意思決定を支援します。
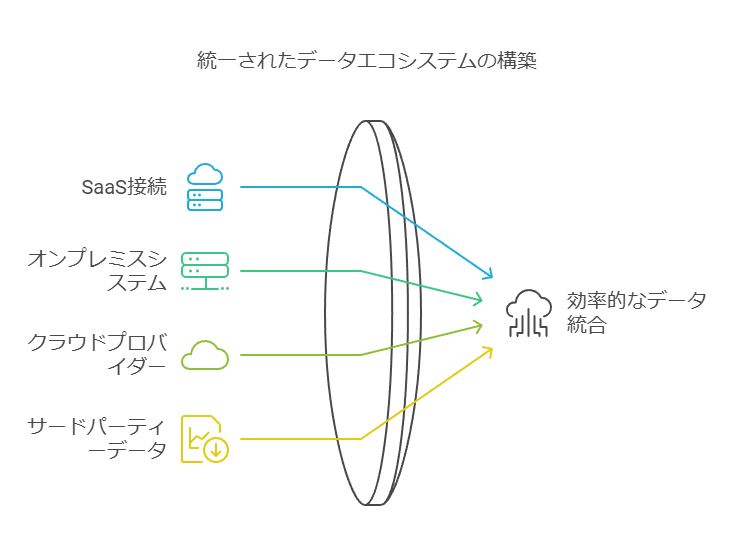
推奨ソリューション: AWS Glue
AWS Glueは、分析や機械学習に必要な複数データソースの検出、準備、統合を容易にするスケーラブルなサーバーレスETL/データ統合サービスです。SaaS、オンプレミス、他のクラウドを含む数百のデータソース、および300以上のサードパーティーデータプロバイダーと接続可能で、幅広いデータ統合を支援します。
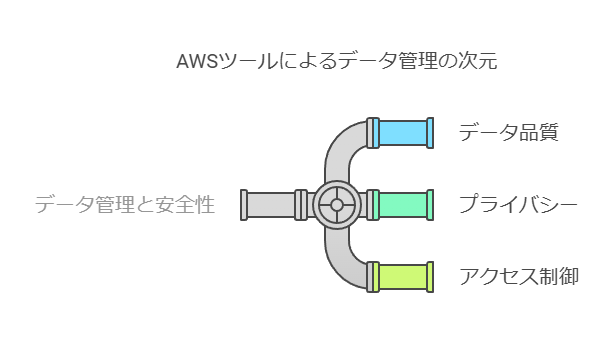
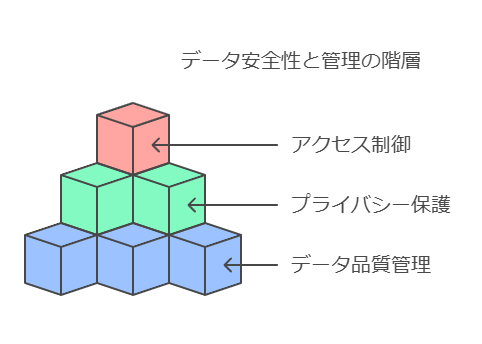
データの安全性と管理: 生成AIライフサイクルの基盤
生成AIアプリケーションの構築では、データの安全性と管理が重要な課題です。AWSは以下のツール群を提供し、データの品質、プライバシー、アクセス制御を包括的に管理する環境を提供します。
データ品質管理: データの一貫性と正確性を確保し、高品質なアウトプットを実現。
プライバシー保護: 機密データの保護により、法規制への準拠を徹底。
アクセス制御: データへのアクセス権限を厳格に管理し、誤用や漏洩を防止。
これにより、生成AIアプリケーションが依拠するデータの高い信頼性とコンプライアンスを確立します。
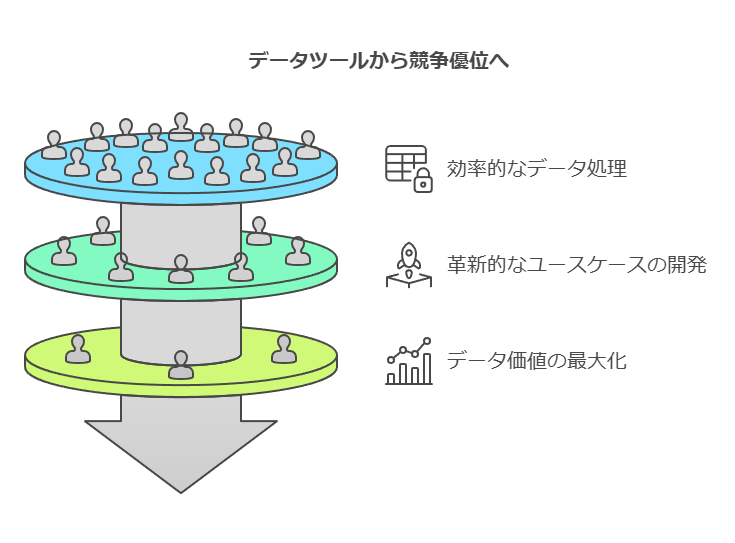
結論: データ基盤の整備による競争優位の確立
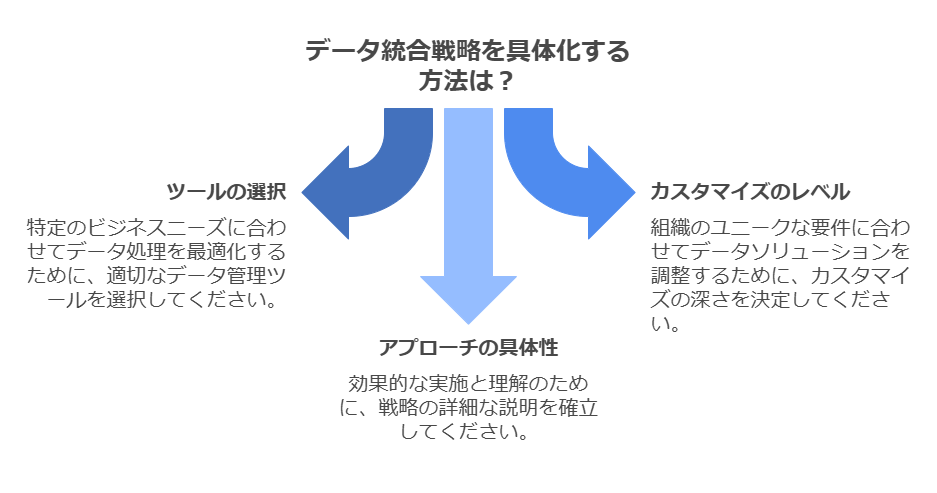
統合されたデータ基盤は、企業が生成AIを活用して競争力を強化するための不可欠な要素です。Amazon RedshiftやAWS Glueを活用することで、企業は高速かつ安全なデータ処理環境を構築し、革新的なユースケースの開発を迅速に実現できます。これらのツールを適切に選定・運用することで、ビジネス全体のデータ価値を最大限に引き出せます。
さらに具体的なアプローチやカスタマイズ例が必要な場合はお尋ねください。
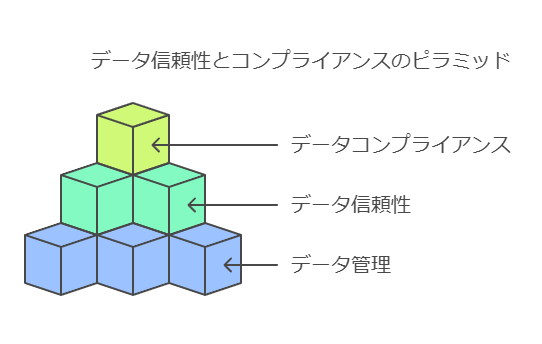
データ保護に関する取り組み状況
現代の企業活動では、データ保護はビジネス戦略の中核を担います。以下の取り組み項目は、各企業が効果的なデータ保護を実現するための重要な基盤です。
現在の取り組み状況
個人情報保護の強化: 法規制(例: GDPR, CCPA)に基づく適切な対策を実施。
IoT・AIデータ保護の検討: 次世代技術に関連するデータ保護も議題に挙げ、将来のリスクに備える。
専任部署の設置: データ保護に関する専任部署を配置し、リスク管理とポリシー策定を担当。
既存部門による管理: データ保護をシステム部門や業務部門が一元管理し、既存インフラを活用。
コンサルタント視点からの提言
企業がデータ保護を強化する際は、専任部署の配置だけでなく、以下のポイントを重視するべきです:
プロセス自動化: AI/ETLツールの導入で、データのモニタリングや異常検知を自動化。
リスク評価: 業務部門と連携し、IoTやAIデータの潜在的なリスクを定期的にレビュー。
教育プログラム: 社内研修を通じて、全従業員のデータ保護意識を向上。
過去実績と現在パイプラインの結びつき
正確なセールスフォーキャスティングの基盤を構築するには、過去実績データと現在のパイプラインをリンクさせるアプローチが不可欠です。
「最終状況分析」アプローチ
過去の商談データを活用し、フォーキャスティングの精度を以下のように向上させます:
後ろ倒し率の把握: 商談受注予定日の変更傾向を分析し、スケジュールの現実性を評価。
成約率の計測: 各商談の実績に基づき、見込み案件の成約可能性を予測。
サイクルタイムの追跡: 案件の進行期間を標準化し、改善点を特定。
営業担当者の指導とサポート
過去データを用いることで、以下のような指導戦略を展開可能です:
パフォーマンスレビュー: 営業担当者ごとに成約率やサイクルタイムをフィードバック。
キャリアサポート: 過去データを基にした具体的な改善提案を提供し、担当者の成長を支援。
プロセス最適化: 問題点が多いステージを特定し、チーム全体で改善策を共有。
案件のベロシティと営業効率の把握
案件ベロシティ(進行速度)と営業効率の可視化は、データドリブンな営業戦略における重要な要素です。
データ可視化の目的
停滞している商談ステージを特定し、迅速な対応を可能にする。
営業パイプライン全体を俯瞰し、優先順位付けやプロセス合理化に役立てる。
RevOps(Revenue Operations)の視点
RevOpsの観点では、以下のデータが営業プロセス改善の基盤となります:
ベロシティ分析: 案件が各ステージを通過する平均時間を特定。
効率性評価: 営業担当者ごとの効率を測定し、最適化可能な領域を特定。
プロセス改善: 営業プロセス全体をスムーズに進行させるための具体的な変更案を提案。
結論: データ活用の進化で競争優位を確立する
データ保護や営業フォーキャスティングの精度向上には、過去実績と現行プロセスを緻密にリンクさせることが鍵となります。加えて、案件ベロシティや営業効率の可視化により、営業戦略の最適化が可能です。
コンサルタントとして提言する次のアクションは以下の通りです:
データ統合ツールの導入: AWS GlueやSnowflakeを活用し、データパイプラインの効率化を推進。
リアルタイム分析基盤の構築: BIツール(例: Tableau, Power BI)で営業データをダッシュボード化。
トレーニングプログラムの実施: 営業担当者がデータを活用できるスキルを習得する場を提供。
これらの取り組みを通じて、データ駆動型の意思決定を可能にし、企業全体の競争力を高めることが期待されます。
1. 戦略のすり合わせ
まず、ビジネス部門、IT部門、データチームを集めて、データ活用の目的とビジネスのニーズを統合し、共通認識を形成することが重要です。ここでは、分析ニーズやデータの活用機会を洗い出し、最新のデータプラットフォームの導入計画を練ります。特に、ベストプラクティスの確認とロードマップの策定を行い、全体の戦略をデータファーストの方向に導きます。
2. 能力評価
次に、現行データプラットフォームの評価を実施し、組織の準備状況とモダナイゼーションに必要な作業を評価します。この段階で、既存の機能をどのようにモダナイズするか、あるいは廃止・導入するかの方針を策定します。また、誰がどのデータにアクセスすべきか、プラットフォームがオンデマンドでのアクセスプロビジョニングに対応できるかを検討し、スキルギャップや組織の準備状況を評価します。
3. アジリティを考慮した計画と設計
次に、サービス指向の統合データアプローチに基づいた詳細な計画と設計を策定します。これには、セキュリティ、インフラ、運用の統合、およびデータストアの保護とコンプライアンスが含まれます。また、ユースケースに基づく機能的および非機能的要件を洗い出し、統合ニーズや消費ニーズに応じたソリューション設計を行います。データアジリティの確保は、今後の変化への対応力を高める重要な要素です。
4. データ移行
データ移行のフェーズでは、移行プロジェクトで発生しうる課題を洗い出し、企業のワークロードとデータの依存関係を踏まえた移行計画を立てます。アプローチを活用し、ベストプラクティス、ツール、手法を用いたスムーズな移行プロセスを設計し、レガシーデータ環境のモダナイゼーションを円滑に進める準備を整えます。
このような段階的なアプローチにより、企業はデータファーストのモダナイゼーションを成功に導き、組織全体でデータの力を最大限に活用できる体制を構築することができます。
データコンサルタントの視点から、組織のアジリティを強化しながらデータ活用を進めるための現実的なアプローチ
データを柔軟に活用するための方法
データを新しい視点で活用し、組織のアジリティを実現するにはどうすれば良いでしょうか。つまり、私たちが予期していない方法で、柔軟かつ迅速にデータを活用し、ミッションの意思決定において精度と創造性の両方を引き出すためのアプローチが求められています。特に高等教育機関においては、既存の文化とプロセスをどのように変革し、新たな柔軟性と適応力を最大限に活用するかが鍵となります。
さらに、データのプライバシー保護とデータの迅速な利用を両立させるためには、どのように制御ガードレールを設置し、データの安全性を確保するべきでしょうか。これを踏まえ、データ活用におけるアジリティを高めるための6つのステップを提案します。
データアジリティを実現する6つのステップ
教育機関が予期しない社会的・教育的変化に対応し、全く新しいイノベーションを生み出すためには、既存のデータの収集方法にとらわれず、より柔軟な方法でデータをプロセスに取り込む必要があります。
目標:
プライバシーと機密性を確保しつつ、データの可用性を最大化する。
情報サイロを解消し、組織全体の透明性を高める。
先進的な分析ツールを活用し、従来の計画にはなかった新たな方法でデータを探索する環境を学部や教職員に提供する。
課題:
教育機関のデータは、学生情報システムや学習管理システムなど、リレーショナルデータベースに閉じ込められ、部署間でのアクセスが制限される形でサイロ化されています。この情報サイロは、全体的なデータ活用を阻害しています。
適切な分析ツールが提供されていない、もしくは、必要なユーザーがタイミングよくツールにアクセスできないという状況があります。このことが、迅速な意思決定を妨げています。
データ探索のニーズが想定されていなかったため、セキュリティやプライバシー保護のモデルはその場しのぎの対応になっています。多くの場合、プライバシーはデータへのアクセスを制限することで保護されていますが、この方法は柔軟なデータ活用を阻害する要因ともなっています。
提案:データガバナンスとアジリティの両立
データコンサルタントとして提案するのは、まず情報サイロを解消し、データの透明性と可用性を高めることです。同時に、プライバシーやセキュリティ要件に応じたデータアクセスガバナンスを強化し、特定の権限を持つユーザーが迅速に必要なデータにアクセスできる環境を整備することが重要です。これにより、組織はデータの価値を最大化し、新たなイノベーションを推進できるようになります。
また、先進的な分析ツールの導入や適切なトレーニングを通じて、教育機関の全スタッフがデータを活用し、新たな発見や洞察を得る機会を提供することが求められます。これにより、教育現場の意思決定において、データ主導のアプローチを可能にし、アジリティを高めることが可能です。
データのプライバシーとセキュリティを維持しつつ、迅速で柔軟なデータ活用を実現するために、適切なデータガバナンスとセキュリティモデルを統合することが、最終的な成功の鍵となります。
このアプローチは、組織のアジリティを高め、変化に柔軟に対応できるデータ主導のカルチャーを醸成するための基盤を提供します。
データコンサルタントとして、データの俊敏性、透明性、スピードを重視し、DataOpsの導入に関する具体的なメリットをクライアント向けに強調し、調査の重要性を説明しています。
迅速なインサイトの必要性とデータエコシステムの最適化
現代の企業や組織は、迅速なインサイトが求められる中で、オペレーションの効率化とチーム間のコラボレーションの改善を急務としています。データ主導の取り組みに対する投資を短期間で価値に変えるためには、データエコシステム全体の俊敏性、透明性、スピードを追求することが最優先課題となっています。データのシームレスなオーケストレーション、適切な管理、タイムリーな出力を実現するためには、強固なサポート体制が必要です。
しかし、データ品質の問題、分散化されたデータ環境、急速に増加するツール、過重なチーム負荷やスキルギャップ、コスト増大、リスクの拡大など、多くの課題がデータエコシステムの複雑化を引き起こしています。このような背景により、データとアナリティクスの民主化が進まず、多くの企業はそのポテンシャルを十分に活用できていません。
DataOpsの必要性とそのメリット
こうした課題を解決するアプローチとして、DataOpsの重要性が増しています。DataOpsは俊敏かつ自動化されたプロセス中心のアプローチであり、データに関わるステークホルダーがデータとアナリティクスの品質、出力、管理を改善する手段を提供します。DataOpsを導入することで、データ駆動型のビジネス意思決定が迅速に行われ、競争力を高めることが可能です。
多くの企業がこのDataOpsの導入に成功すれば、データの評価・分析プロセスが改善され、データ主導の未来を手に入れることができると考えています。プロセス中心の俊敏なアプローチにより、データを統合的かつ効率的に活用することで、より高いビジネス価値を生み出すことが期待されています。
DataOps導入に関する調査
ESGは、このDataOpsトレンドをさらに深く分析するため、北米(アメリカおよびカナダ)の企業や組織でデータ戦略やアナリティクスに携わる技術データ担当者およびビジネスデータ担当者、計403人を対象に調査を行いました。この調査は、市場の成熟度、直面している課題、購買や計画の意思決定に影響を与える要因、そしてDataOpsのビジネスへのメリットを評価することを目的としています。
調査の目的と把握したい事項
この調査を通じて、以下の点に焦点を当てています:
DataOpsの市場成熟度の評価
企業がDataOpsをどの程度導入し、活用しているのかを把握し、その成熟度を評価します。これにより、どの段階でDataOpsが企業の成長に貢献しているかが明確になります。
DataOps導入に伴う課題の特定
企業がDataOpsを導入する際に直面する技術的・人的課題を理解し、それを克服するための戦略を提示します。
DataOpsの購買や意思決定に影響を与える要因
企業がDataOpsに投資を行う際に重視する要因や、その意思決定プロセスに影響を与える外部・内部の要素を明らかにします。
DataOpsのビジネスインパクト
DataOpsを導入した企業が、どのようなビジネス上のメリットを享受しているかを評価します。これには、オペレーションの効率化、コスト削減、迅速な意思決定のサポートが含まれます。
DataOpsは、データを迅速かつ効率的に活用するための鍵となり、データ駆動型の未来に向けた重要なステップです。この調査結果は、企業がどのようにDataOpsを活用してビジネスの俊敏性を高め、競争力を向上させるかの一助となるでしょう。
これらにより、DataOpsの導入に対する具体的な利点と実行の必要性をクライアントに理解してもらうための内容を提示しました。
データ戦略の推進で達成すべきビジネス目標
提供する製品・サービスの品質向上
データ駆動型の品質管理と改善プロセスを導入することで、顧客満足度と製品の競争力を強化。
業務効率の改善
業務フローの最適化と自動化を進め、データに基づく判断でリソースの無駄を削減し、運営コストを抑制。
意思決定と戦略策定の精度向上
高品質なデータを基にした分析により、経営層と現場が迅速かつ正確な意思決定を行い、競争優位を確保。
予測精度の向上
AI/MLを活用したデータ分析により、将来の市場動向や顧客行動をより精度高く予測し、柔軟な対応を実現。
アップセル、クロスセールスによる顧客支出の増加
顧客データの深い分析により、新たな販売機会を捉え、顧客単価の向上を実現。
新製品/新サービスおよび市場参入の判断強化
市場データと顧客インサイトを活用し、最適な製品開発や市場参入の判断をサポート。
新たなデータセットの迅速な統合
ビジネスの成長に伴う新しいデータソースをスムーズに統合し、リアルタイムでの分析を可能に。
事業運営コストの削減または最適化
データを活用したコスト分析により、無駄な支出を削減し、リソースの最適配分を実現。
規制遵守のコスト最小化
データガバナンスと自動化を組み合わせ、コンプライアンス維持にかかる費用とリスクを低減。
変化する顧客ニーズへの迅速対応
顧客データをリアルタイムで活用し、素早く戦略を転換することで、競争市場での優位性を保つ。
履歴データからのインサイト拡充
過去データの分析を深めることで、今後のビジネス戦略に活かせる新たな発見を増やす。
製品/サービスの市場投入スピードの加速
データに基づいた開発とテストプロセスの最適化により、製品/サービスをより迅速に市場へ投入。
新しいビジネスチャンスの開拓
データ分析を通じて、隠れたビジネス機会を発掘し、成長の道筋を明確化。
データの信頼性を最優先に
ビジネスの意思決定において、データ品質が基盤となり、信頼性がなければ効果的なインサイトや結果を得ることはできない。可用性、アクセス性、可視性が伴って初めて高品質なデータの保証が可能。
優先的に取り組むべきデータ活用の課題
データ品質の向上
信頼性の高いデータ環境を整備し、意思決定の精度を高める。
データの可用性とアクセス性の向上
必要なデータをタイムリーに取得し、迅速な分析・判断が可能な体制を構築。
データの可視性の向上
組織全体でデータの透明性を確保し、部門横断でのデータ利用を促進。
意思決定に活用可能なデータの拡充
データ範囲を広げ、意思決定プロセスに役立つ追加情報を提供。
インサイト精度の向上
AI/MLを導入し、より正確で価値のあるインサイトを得るためのデータ分析を強化。
AI/MLの活用拡大
ビジネス全体でのAI/MLの適用を広げ、データ分析の自動化と予測精度を向上。
エンドユーザーによるデータ利用の迅速化
ユーザーフレンドリーなデータプラットフォームを提供し、迅速かつ簡単にデータを活用できる環境を整備。
データ分析の強化とエンドユーザーの能力向上
データリテラシーの向上とツールの提供により、エンドユーザーがデータを深く分析し活用できるよう支援。
データパイプラインの自動化
データ処理の一部、または全体の自動化を進め、効率性を向上。
開発者によるデータの効果的な活用促進
ビジネスアプリケーションにデータを組み込むプロセスを最適化し、製品開発サイクルを加速。
データカルチャーの醸成
エンドユーザー間でのデータ共有とコラボレーションを促進し、データ駆動型の文化を育成。
データアーキテクチャの簡素化
既存の複雑なアーキテクチャを見直し、シンプルでスケーラブルな構造へと改善。
テクノロジースタックの監査と最適化
現行のテクノロジー環境を継続的に評価し、ビジネスニーズに適したアップデートや改善を実施。
このように、データコンサルタントとしては、データの信頼性、可用性、アクセス性、そして最終的に得られるビジネスインサイトを強化することが企業の成長と成功に不可欠であると考えています。
DataOps エコシステムに求められるコンポーネント
DataOpsのエコシステムは多様であり、構成要素も非常に広範囲にわたります。中でも、データ分析ツールチェーンはプロセス全体のオーケストレーションに不可欠であり、エコシステムの中核として位置付けられています。しかし、DataOpsが効果的に機能するためには、データ統合、アクセス管理、データガバナンス、データ変革、モデル化、データ視覚化など、ツールチェーンの役割を超えた幅広い機能が必要です。
特に、データの可観測性や変更管理、チーム間のコラボレーションをサポートするツールが重要な要素となっており、CI/CD(継続的インテグレーション/継続的デリバリー)などのコンポーネントが統合されたエコシステムを構築することが求められます。これにより、DataOpsの自動化と効率性が強化され、安定したデータ運用基盤を確立できます。
DataOps エコシステムに必要な主なコンポーネント
データアナリティクスツールチェーン
データガバナンスとセキュリティ
プロセス分析機能
データの可観測性とイベントトラッキング、アラート
変更管理ツール
チーム間コラボレーションツール
設定管理・コンテナ管理
継続的テストとバージョン管理
モデル開発と配備
継続的インテグレーション(CI)と継続的デリバリー(CD)
アジャイルプロジェクト管理
コードリポジトリとサンドボックス
オーケストレーション
DataOps における自動化の重要性
DataOpsの自動化は、多くの組織で重要視されています。調査によると、97%の組織が「少なくとも一部のプロセスを自動化する予定」と答え、38%が「ほぼ全てを自動化したい」としています。自動化は、スキルギャップや人的リソースの不足を補うための解決策として、ますます浸透しています。
特に、自動化の導入においては、まず低リスクで高ボリュームのタスクから取り組むことが推奨されており、成果を短期間で測定できるプロジェクトが最適です。また、プロセスが自動化された後に、人的な手直しが必要かどうかを慎重に評価し、必要に応じて最適化を行うことが重要です。適切な自動化は、組織全体の効率向上に貢献し、データ活用を円滑に進めるための基盤を提供します。
スキルギャップと過重負荷
DataOpsに関与する各ステークホルダーの間では、深刻なスキルギャップが報告されています。データアナリストやITオペレーション、データサイエンティスト、データエンジニア、データベース管理者など、多くの部門で専門的なスキルが不足しており、これは組織全体に負荷をかける要因となっています。
このスキルギャップを埋めるため、組織は自動化やセルフサービスツールの導入に注力しており、これによりエキスパートとゼネラリストの両方が負担を軽減できるような環境を整えています。特に、データエンジニアの負担軽減や、業務の効率化に繋がる仕組み作りが急務となっています。
負荷が最も集中しているDataOpsステークホルダー
ITオペレーション
データアナリスト
データエンジニア
データベース管理者
データウェアハウス/BI/分析マネージャー
経営幹部
エンタープライズアーキテクト/データアーキテクト
データサイエンティスト
ビジネスアナリスト
アプリケーション開発者
業務担当者
データスチュワード
ここでは、DataOpsの自動化の重要性や、スキルギャップと負荷分散の問題をデータコンサルタントの視点で整理し、技術的な解決策や組織への影響を具体的に強調しています。
DataOps の投資拡大の傾向
DataOps の導入状況にかかわらず、企業や組織がデータ管理に対する投資を加速させていることは明らかです。調査によると、回答者の91%が、今後1年間で中規模から大規模なDataOpsソリューションへの投資を計画していると答えています。これは、企業がデータとアナリティクスの品質向上、出力の最適化、そして管理プロセスの効率化を目指していることを示しています。DataOps の自動化とプロセス主導のアプローチが、データステークホルダー全体の業務を俊敏にサポートする基盤として重視されているのです。
データ管理における課題の顕在化
企業がDataOpsへの投資を増やす主な理由は、社内で抱えている多くのデータ関連課題を解決するためです。調査によれば、すべての組織が何らかのデータ課題に直面しており、それを克服するためにDataOps戦略を推進しています。特に、エコシステムの複雑化がデータとアナリティクスの民主化を阻んでおり、DataOpsを導入することで、これらの問題を迅速に解決しようとしています。
主要な課題と解決策
DataOps戦略で解決を目指すデータ関連の課題は多岐にわたります。以下は、企業が特に重要視している課題です:
スキルギャップ:特にデータエンジニアやアナリティクス人材の不足が顕著であり、これが効率的なデータ管理の障害となっています。
データの増大:日々増加するデータ量が、管理コストや運用リソースに負担をかけています。
法規制コンプライアンス:データプライバシー法や業界規制への対応が厳しくなり、これに適応するデータガバナンス体制の強化が求められています。
データの分散と複雑化:複数のシステムやクラウド環境に分散されたデータの統合が難航し、効率的なデータ活用を阻害しています。
サイバーセキュリティの変化:セキュリティ脅威の進化に対応するため、データ保護対策が急務となっています。
データ品質と精度の問題:信頼性の高いデータが不足しており、これが意思決定の妨げとなるケースが多発しています。
データリテラシーの欠如:全社的にデータを活用できる人材の育成が遅れているため、データの価値を最大限に引き出すことができていません。
自動化の欠如:データパイプラインや統合プロセスの自動化が進んでいないことで、業務効率が低下しています。
DataOpsの価値
これらの課題を解決するため、DataOpsはプロセスの自動化と可視化を促進し、データフローの効率を高めます。特に、データガバナンスの強化、データ品質の向上、サイロ化の解消により、組織全体でのデータ活用が大幅に向上します。さらに、データリテラシーを向上させ、俊敏なデータ戦略を実現することで、競争力のある企業環境を構築できるのです。
ここでは、DataOpsの投資増加やそれが解決しようとしている具体的な課題を詳細に説明し、企業が直面しているデータ管理上の課題とその解決策について強調しました。
DataOps における非データエンジニアの影響力拡大
従来、DataOpsの領域ではデータエンジニアが中心的な役割を担っていました。導入から日常業務に至るまで依然として重要な役割を果たしていますが、近年では戦略策定や購買意思決定において、IT部門以外のビジネス部門も大きな影響力を持つようになってきました。DataOps戦略の策定には、IT担当者、エンドユーザー、開発者、業務リーダーなど、さまざまな部署が深く関与しており、組織全体での協力体制が鍵となっています。
実際、調査では回答者の76%が「DataOpsの戦略に複数のチームが協力して取り組んでいる」と答え、チーム横断的な協力とコラボレーションがDataOpsの成功に向けた重要な要素として浮かび上がっています。
DataOps戦略と購買に関与する主要なステークホルダー
ITオペレーション
データアナリスト
データベース管理者
データエンジニア
経営幹部
ビジネスアナリスト
データサイエンティスト
データウェアハウス/BI/分析マネージャー
アプリケーション開発者
エンタープライズアーキテクト/データアーキテクト
業務担当者
データスチュワード
スキルギャップの問題と自動化による対応
DataOpsに関与するステークホルダーの間で、深刻なスキルギャップが広がっていることも明らかになりました。調査によると、91%の組織が1つ以上の部署にスキル不足を抱えており、特にデータアナリスト、ITオペレーション、データサイエンティスト、データエンジニア、データベース管理者、ビジネスアナリストの分野でスキルギャップが顕著です。このギャップは、自動化やセルフサービス型のデータツールの導入によって解消される可能性があり、技術の進化に伴ってデータエコシステム全体での効率化が期待されています。
自動化とセルフサービスの促進
スキルギャップが深刻化する中で、自動化やセルフサービス型ツールの導入が、効率的なデータ管理と活用を促進する鍵となっています。これにより、スキル不足が直接業務に与える影響を軽減し、各チームがデータに基づく意思決定を迅速に行えるようになるため、データの民主化が加速します。組織はこれらの技術を導入し、チーム間での協力を強化することで、データ主導の意思決定をさらに推進することが求められています。
ここでは、データコンサルタントとして、DataOpsにおける影響力の広がりやスキルギャップの問題を整理し、技術的な解決策として自動化やセルフサービスツールの導入を提案する形にしました。