目次
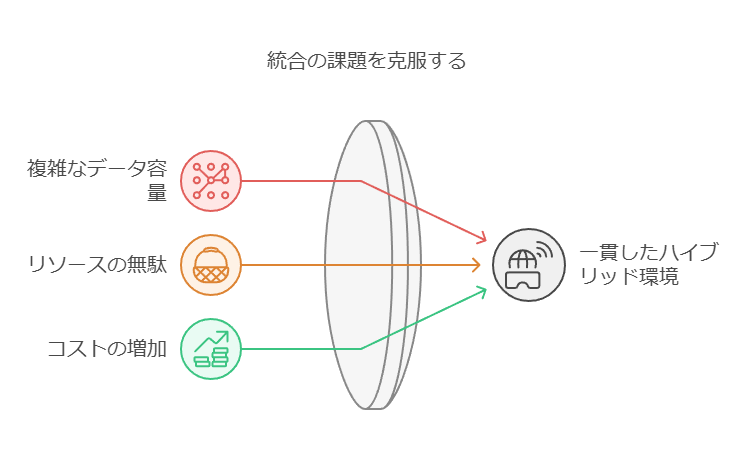
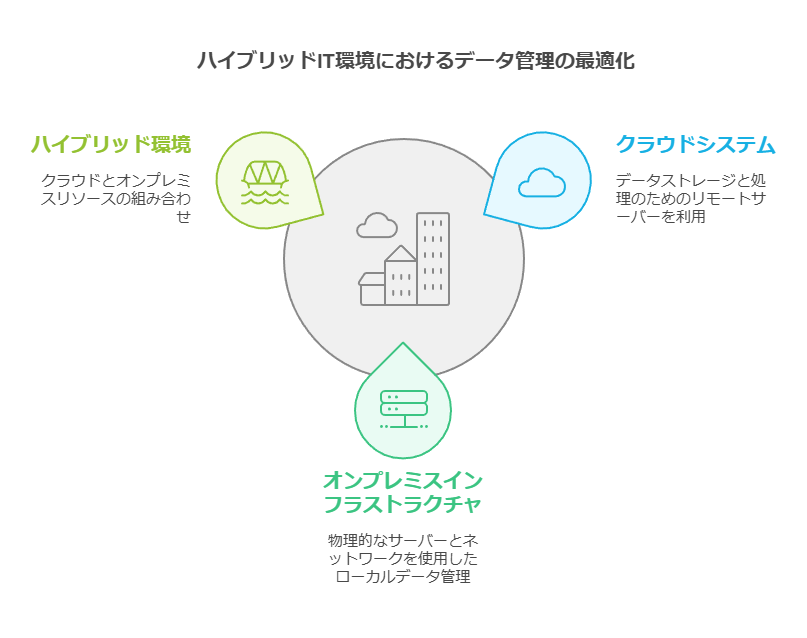
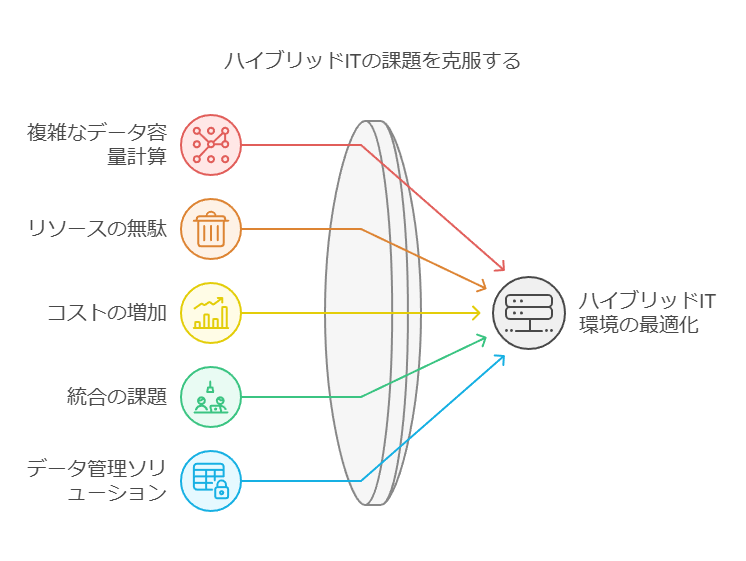
複数のインフラストラクチャを使用する際には、データ容量の計算が複雑化し、その結果、リソースの無駄やコストの増加が発生するリスクがあります。オンプレミス、ホステッド、物理、仮想、コンテナ化、クラウドベースなどの異なる環境を統合することは、多くの企業にとって大きな課題です。そのため、一貫したハイブリッド環境を確立することが難しくなっています。
「損失」 → 「コストの増加」 に置き換え、より具体的なリスクを表現。各インフラの名称を列挙し、課題が複数環境の「統合」にあることを明確化。データマネジメントソリューションは、ハイブリッドIT環境における課題を解消し、ハイブリッド運用を円滑にするために、次のような機能を提供します。
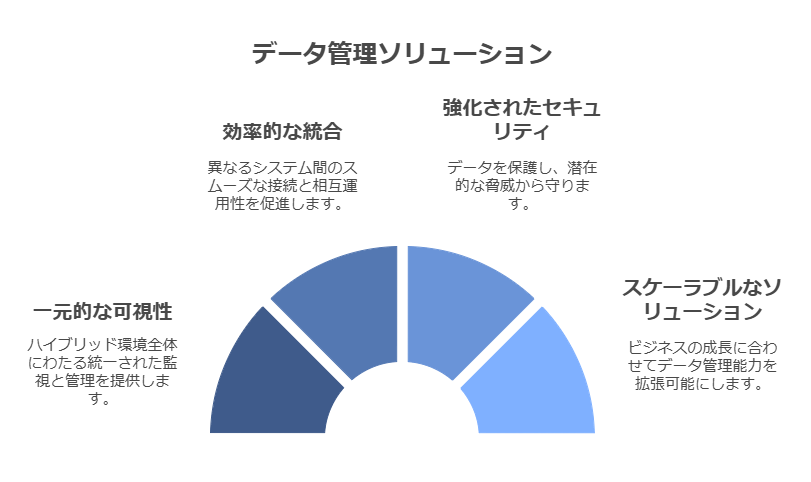
一元的な可視性と管理機能を、ハイブリッド環境全体に提供します。
「データの管理」から「管理機能」に変更し、技術的な表現に。視覚的に捉えられる「可視性」を強調。
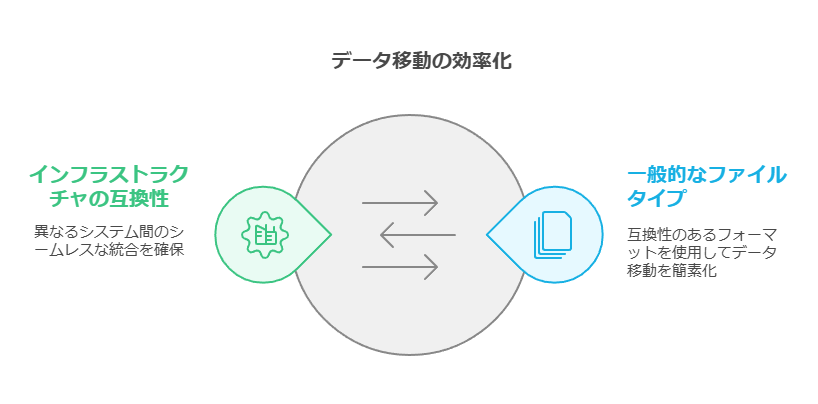
一般的なファイルタイプを使用して、データ移動・移行の自動化を実現します。これにより、異なるインフラストラクチャやファイルフォーマットの種類に関わらず、データの保存、バックアップ、移行を効率的に行うことが可能です。
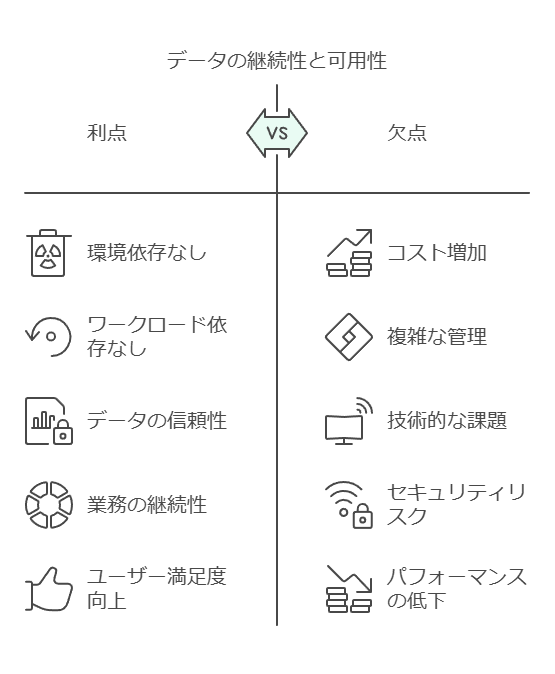
環境やワークロードに依存せず、データの継続性と可用性を確保します。
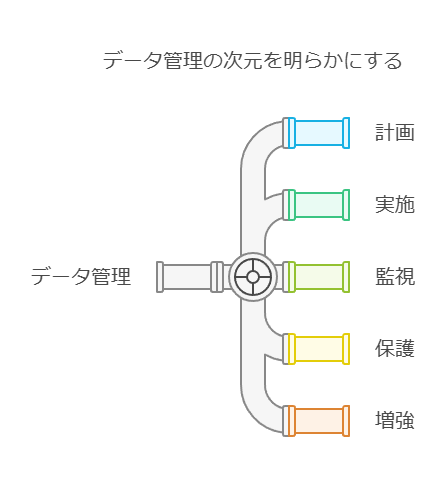
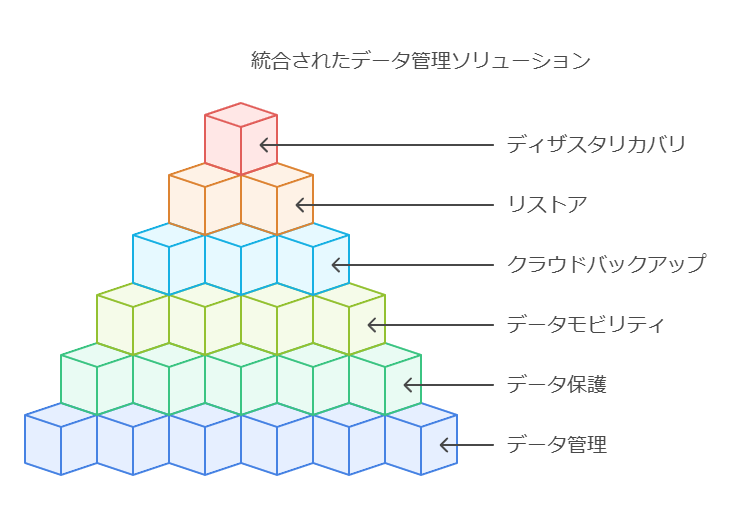
データの管理、保護、モビリティを実現する単一のソリューションに、クラウドバックアップ、リストア、ディザスタリカバリ、データ移行を統合します。
複数のインフラストラクチャを使用する際には、データ容量の計算が複雑化し、その結果、リソースの無駄やコストの増加が発生するリスクがあります。オンプレミス、ホステッド、物理、仮想、コンテナ化、クラウドベースなどの異なる環境を統合することは、多くの企業にとって大きな課題です。そのため、一貫したハイブリッド環境を確立することが難しくなっています。
データマネジメントソリューションは、ハイブリッドIT環境における課題を解消し、ハイブリッド運用を円滑にするために、次のような機能を提供します。
一元的な可視性と管理機能を、ハイブリッド環境全体に提供します。
一般的なファイルタイプを使用して、データ移動・移行の自動化を実現します。これにより、異なるインフラストラクチャやファイルフォーマットの種類に関わらず、データの保存、バックアップ、移行を効率的に行うことが可能です。
環境やワークロードに依存せず、データの継続性と可用性を確保します。
データの管理、保護、モビリティを実現する単一のソリューションに、クラウドバックアップ、リストア、ディザスタリカバリ、データ移行を統合します。
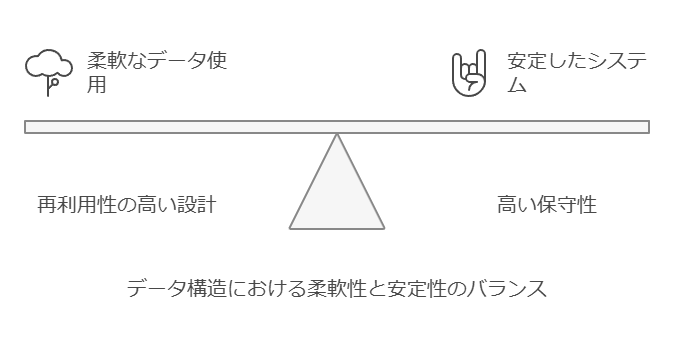
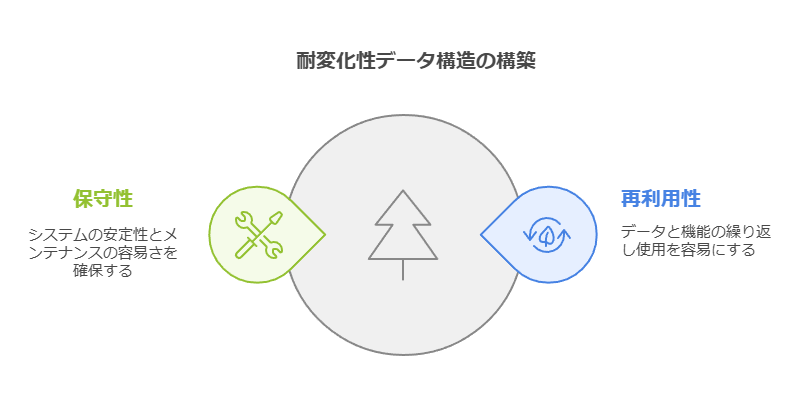
変化に強いデータ構造を構築するための第一歩は、「変化に強い」状態を明確に定義することです。
これには、以下の2つの要素が不可欠です。
再利用性の高い設計: 同じデータや機能を何度でも容易に利用できること。
高い保守性: システムが安定し、メンテナンスやアップグレードが容易であること。
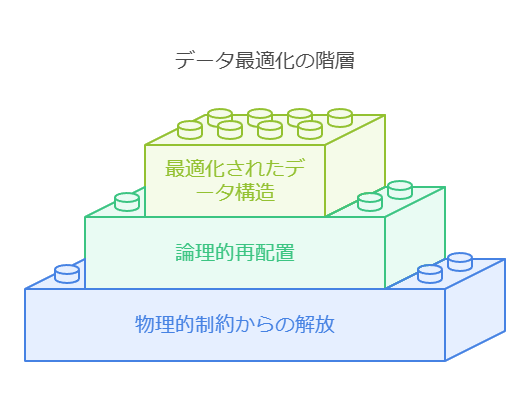
これらを実現するためには、データを物理的な制約から解放し、論理的に再配置することが重要です。これにより、データの柔軟な運用が可能になります。
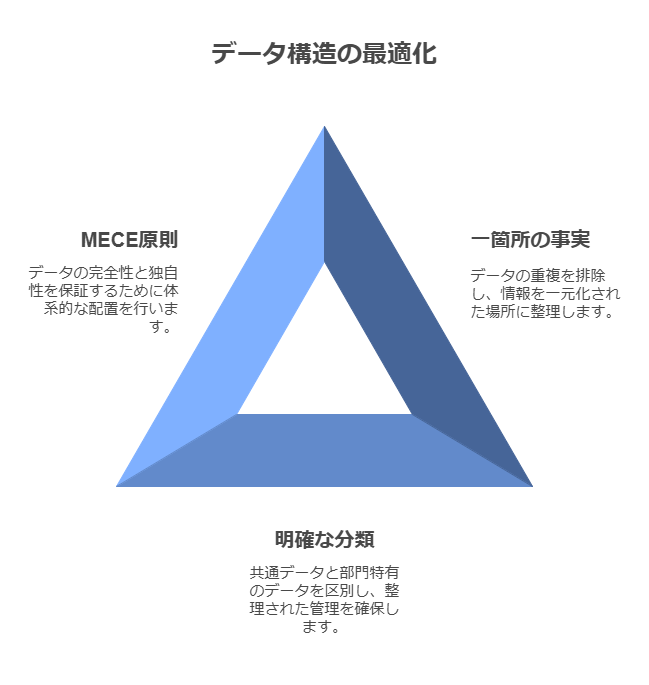
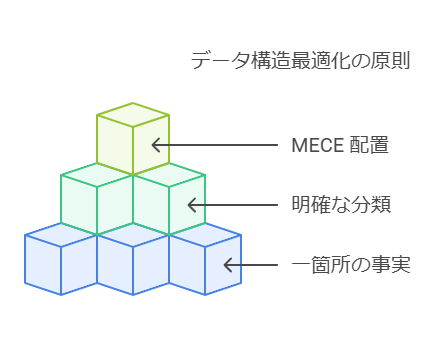
現在の個別最適化された環境において、変化に対応できるデータ構造を構築するには、次の3つの原則が基盤となります。
One Fact in One Place: 同じ意味を持つデータは一箇所で管理し、重複を排除します。
共通と個別の明確な分類: 事業横断で共通するデータと、各部門・チーム固有のデータを明確に区別します。
MECE (Mutually Exclusive, Collectively Exhaustive): データに漏れや重複がないように、体系的かつ網羅的な配置を行います。
これらの原則は、データ管理の効率性と可用性を高め、組織全体でのデータ活用を最適化します。
この原則に基づいて、データ構造の最適化を進めるための具体的なステップは以下の通りです。
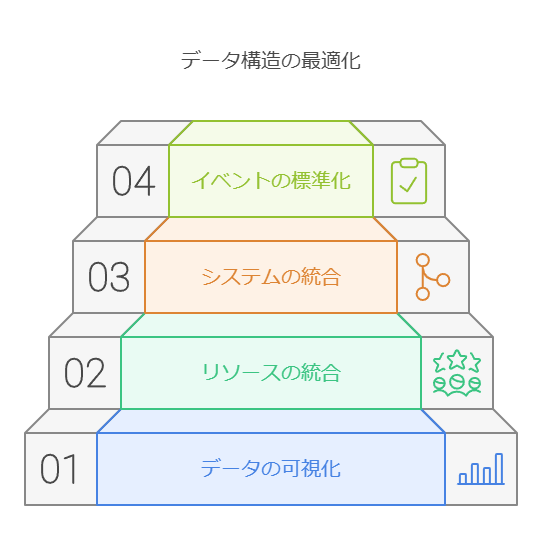
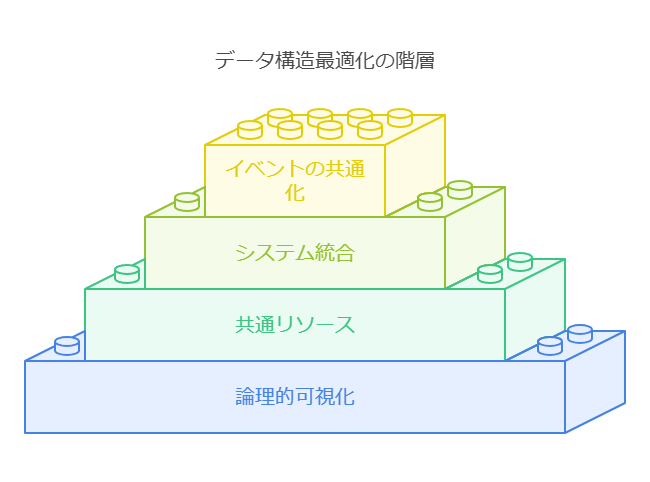
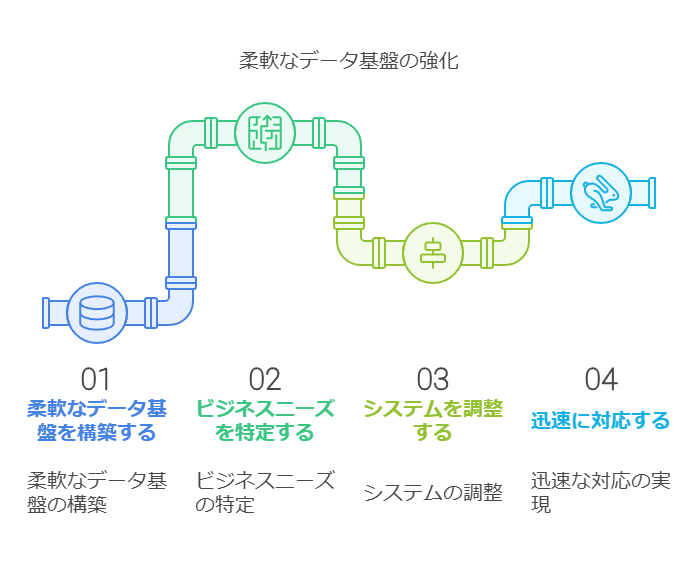
データの論理的可視化 (Step 1): 現場の個別最適化されたデータを、論理的に可視化することで、全体像を把握します。これにより、どのデータが再利用可能で、どのデータが冗長であるかが明確になります。
共通リソース化 (Step 2): 各事業部門で保持しているマスターデータのうち、共通の意味を持つものを一元化し、全社で活用可能な共通リソースとして統合します。
情報系統の統廃合 (Step 3): 乱立した情報システムを整理し、データウェアハウス(DWH)に統合します。必要に応じてデータマートを作成し、効率的なデータ分析環境を構築します。
イベントの共通化 (Step 4): 各システム間で共通の機能やデータ処理イベントを統合し、全社的に利用可能な標準化されたプロセスを確立します。
これらのステップにより、データ構造を最適化し、変化に対応できる柔軟で効率的なシステムが構築されます。
変化に強いデータ構造を構築するための第一歩は、「変化に強い」状態を明確に定義することです。これには、以下の2つの要素が不可欠です。
再利用性の高い設計: 同じデータや機能を何度でも容易に利用できること。
高い保守性: システムが安定し、メンテナンスやアップグレードが容易であること。
これらを実現するためには、データを物理的な制約から解放し、論理的に再配置することが重要です。これにより、データの柔軟な運用が可能になります。
現在の個別最適化された環境において、変化に対応できるデータ構造を構築するには、次の3つの原則が基盤となります。
One Fact in One Place: 同じ意味を持つデータは一箇所で管理し、重複を排除します。
共通と個別の明確な分類: 事業横断で共通するデータと、各部門・チーム固有のデータを明確に区別します。
MECE (Mutually Exclusive, Collectively Exhaustive): データに漏れや重複がないように、体系的かつ網羅的な配置を行います。
これらの原則を踏まえて、データ構造の最適化を進めるためのステップは以下の通りです。
データの論理的可視化 (Step 1): 現場の個別最適化されたデータを、論理的に可視化することで、全体像を把握します。
共通リソース化 (Step 2): 各事業部門で保持しているマスターデータのうち、共通の意味を持つものを一元化し、全社で活用可能な共通リソースとして統合します。
情報系統の統廃合 (Step 3): 乱立した情報システムを整理し、DWHに統合します。必要に応じてデータマートを作成し、効率的なデータ分析環境を構築します。
イベントの共通化 (Step 4): 各システム間で共通の機能やデータ処理イベントを統合し、全社的に利用可能な標準化されたプロセスを確立します。
これにより、変化に強い柔軟なデータ基盤が整備され、ビジネスの要求に迅速に対応できるシステムが実現されます。
データの価値を最大化するために、「データマネジメント」を実践することが重要です。
理論としては理解していても、実際の運用方法に迷うことがあるかもしれません。そのために、データマネジメントのフレームワークを用いることで、データの管理・最適化を計画的に進めることができます。DMBOK2(データマネジメントの知識体系)によれば、データマネジメントとは「データおよびインフォメーションという資産の価値を最大限に引き出し、そのライフサイクル全体を通じて管理、保護、向上させるための計画や方針、スケジュール、手順を策定・実施・監督する活動」と定義されています。これにより、データ資産の効率的な管理が可能となり、ビジネス価値を引き出す基盤を築くことができます。
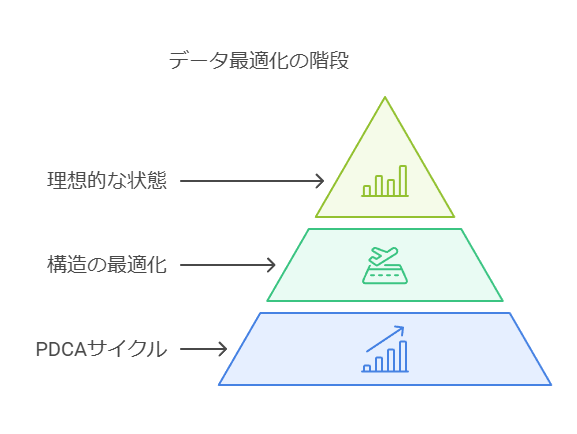
PDCAサイクルを活用することで、データマネジメントはデータの価値を持続的に向上させるプロセスとなります。特に、データ構造の最適化においても、現状(As-Is)から理想的な状態(To-Be)への段階的なアプローチが必要です。例えば、いきなり「Step4: イベントの共通化」へ進むのではなく、まずは「Can Be」として可能な部分から計画を立て、徐々にTo-Beへと進化させることが、効果的な進め方です。
DMBOK2は、データマネジメントにおける11の知識領域を「DMBOKホイール」として視覚的に整理しています。これらの知識領域の優先度は、企業のニーズや状況によって異なります。例えば、ある企業では「今回はデータモデリングを重点的に実施する」といったように、特定の領域にフォーカスし、PDCAサイクルを回すことで継続的な改善を図ることが可能です。
DMBOKホイールの中心に位置する「データガバナンス」は、組織全体でのデータに対する方針やルールを策定し、データ文化の醸成に不可欠な要素です。データガバナンスは、全てのデータ管理活動の基盤となるため、早い段階での導入を強くお勧めします。
PDCAサイクルは、継続的な改善を実現するために繰り返し実施されるプロセスです。そのため、厳密なステップの順序は固定されていません。企業によっては、まず現状を評価して改善点を洗い出すアセスメントから始める場合もあれば、データモデルの計画策定からスタートする場合もあります。状況に応じた柔軟なアプローチが可能です。
データの価値を最大化するために、「データマネジメント」を実践することが重要です。理論としては理解していても、実際の運用方法に迷うことがあるかもしれません。そのために、データマネジメントのフレームワークを用いることで、データの管理・最適化を計画的に進めることができます。
DMBOK2(データマネジメントの知識体系)によれば、データマネジメントとは「データおよびインフォメーションという資産の価値を最大限に引き出し、そのライフサイクル全体を通じて管理、保護、向上させるための計画や方針、スケジュール、手順を策定・実施・監督する活動」と定義されています。これにより、データ資産の効率的な管理が可能となり、ビジネス価値を引き出す基盤を築くことができます。
PDCAサイクルを活用することで、データマネジメントはデータの価値を持続的に向上させるプロセスとなります。特に、データ構造の最適化においても、現状(As-Is)から理想的な状態(To-Be)への段階的なアプローチが必要です。例えば、いきなり「Step4: イベントの共通化」へ進むのではなく、まずは「Can Be」として可能な部分から計画を立て、徐々にTo-Beへと進化させることが、効果的な進め方です。
DMBOK2は、データマネジメントにおける11の知識領域を「DMBOKホイール」として視覚的に整理しています。これらの知識領域の優先度は、企業のニーズや状況によって異なります。例えば、ある企業では「今回はデータモデリングを重点的に実施する」といったように、特定の領域にフォーカスし、PDCAサイクルを回すことで継続的な改善を図ることが可能です。
DMBOKホイールの中心に位置する「データガバナンス」は、組織全体でのデータに対する方針やルールを策定し、データ文化の醸成に不可欠な要素です。データガバナンスは、全てのデータ管理活動の基盤となるため、早い段階での導入を強くお勧めします。
PDCAサイクルは、継続的な改善を実現するために繰り返し実施されるプロセスです。そのため、厳密なステップの順序は固定されていません。企業によっては、まず現状を評価して改善点を洗い出すアセスメントから始める場合もあれば、データモデルの計画策定からスタートする場合もあります。状況に応じた柔軟なアプローチが可能です。
- データ管理の重要性を強調:
キャパシティプランニングと管理は、現代のビジネスにおいて極めて重要です。データ駆動型の意思決定を行うためには、適切なデータ管理戦略が不可欠です。インテリジェントなソリューションを活用することで、現在のニーズに最適化されたストレージ領域を提案し、将来的なデータ成長に備えたプランニングが可能になります。
- データの可用性と品質の重要性:
多様なインフラストラクチャ間でのデータバックアップと移動を可能にするサービスを選択することで、データの可用性が大幅に向上します。これにより、ユーザーやアプリケーションに対して、必要な時に高品質でコンプライアンスに準拠したデータを提供できます。結果として、ハイブリッド環境の効率が向上し、重要なデータを活用してビジネス価値を創出する機会が増加します。
- データセキュリティとコンプライアンスの課題:
データセキュリティは、常に進化する脅威に対応するため、継続的な取り組みが必要です。特に、複数のインフラストラクチャにまたがる環境では、一貫したガバナンスの実現と維持が複雑になります。しかし、データ保護の失敗がもたらすビジネスへの影響は甚大です。2021年までにサイバー犯罪による被害額が6兆ドルに達すると予測されていることからも、その重要性が伺えます。
- クラウドセキュリティの重要性:
クラウドベースのデータの整合性確保は、現代のデータ戦略において極めて重要です。フロスト&サリバンの調査によると、ビジネスリーダーの74%がセキュリティインシデントによってクラウドワークロードをオンプレミスに戻さざるを得なかった経験があると回答しています。このデータは、クラウドセキュリティの重要性と、適切なセキュリティ対策の必要性を明確に示しています。
- 総合的なデータ戦略の提案:
効果的なデータ管理戦略には、以下の要素が不可欠です:
- インテリジェントなキャパシティプランニング
- 柔軟なデータ移動とバックアップソリューション
- 強固なセキュリティ対策
- コンプライアンス準拠の保証
- ハイブリッド環境に対応したデータガバナンス
これらの要素を適切に組み合わせることで、組織はデータを最大限に活用し、ビジネス価値を創出するとともに、潜在的なリスクを最小限に抑えることができます。
データコンサルタントとして、クライアントにはこれらの要素を考慮した包括的なデータ戦略の策定を提案し、ビジネス目標の達成を支援します。
効率的なクラウドによるデータ管理: ビジネス価値を最大化するためのプラットフォーム選定
データ管理の効率化は、単なるデータ保護にとどまらず、クラウドリソースの効果的な活用にも直結しています。IT組織は、データ管理プラットフォームを選定する際に、クラウド上での最適なリソース活用ができるかを評価することが重要です。特に、クラウドオーケストレーションやプロビジョニング機能を備えたソリューションは、IT部門のクラウド投資効果を最大化し、長期的な競争力を確保する要素となります。
ここでは、データ管理プラットフォームを選定する際に検討すべき5つの重要な特性を説明します。
クラウドネイティブな設計
データ管理ソリューションの中には、単にクラウドに追随しているものもありますが、クラウドを前提として設計されているプラットフォームはより高い柔軟性と信頼性を提供します。複数のクラウドストレージを統合し、異なる環境でシームレスに動作するプロバイダーを選ぶことが推奨されます。
クラウドオーケストレーションとプロビジョニング機能
クラウド環境でのディザスタリカバリやテスト/開発のユースケースに対応するため、クラウドインフラの管理を自動化・合理化できるオーケストレーション機能が必要です。これにより、クラウドリソースを効率的に管理し、コスト削減やビジネスの継続性を確保できます。
セルフサービス管理ツールの提供
エンドユーザーが簡単にリソースを管理できるカスタマイズ可能なセルフサービス管理ツールがあると、IT部門の負荷を減らしつつ、ユーザー自身がリソースの割り当てや変更を行えます。管理者はポリシーに基づいてリソース利用を制御できるため、ガバナンスも維持しやすくなります。
ネイティブなクラウド機能のサポート
選定するプラットフォームは、主要なクラウドコンピューティングプラットフォーム(Azure、AWS、OpenStack、VMwareなど)にネイティブ対応している必要があります。これにより、将来的なクラウド戦略にも柔軟に対応でき、クラウドプロバイダーのロードマップに対しても安心感が得られます。
複数クラウド環境を一元管理するコンソール
複数のクラウド環境を使用する企業にとって、異なるクラウドプラットフォームを一元的に管理できるコンソールは非常に重要です。この機能により、管理プロセスや技術を標準化し、クラウド環境全体を効率的に運用することが可能です。
クラウド戦略の価値を最大化するために
IT組織がメインストリームアプリケーションをクラウドへ移行する際、クラウド戦略の価値を最大限に引き出すことが求められます。具体的には、クラウドのコスト効率を最大限に活用しつつ、開発者の生産性向上やアプリケーション配信の高速化を実現することです。
データ管理プラットフォームは、単なるデータ保護機能を提供するだけではなく、クラウドリソースを最適化し、企業がビジネス上の目的を達成するための基盤となる必要があります。このため、IT部門はクラウド対応能力の高さを持つプラットフォームを導入し、長期的な成長と変革を支えるデータインフラを構築することが重要です。
データコンサルタントの提言:
クラウドネイティブなプラットフォームを選定し、クラウドリソースの管理を効率化する。
セルフサービス型の管理ツールでユーザーと管理者の双方の負担を軽減し、運用の効率を向上させる。
複数のクラウド環境に対応できる統合管理コンソールにより、異なるクラウドの管理を標準化し、コストとリソースの無駄を最小化する。
[データ管理] 拡張性と統合性を備えた意思決定プラットフォームの選定
現代のビジネス環境では、強力で多目的かつ拡張性に優れた意思決定機能を提供するために、適切なデータプラットフォームの選定が不可欠です。このようなプラットフォームは、現在のデータニーズに対応するだけでなく、将来の新しいワークロードにも適応する柔軟性を持つ必要があります。さらに、テクノロジースタックの簡素化と、データ管理やアナリティクスの取り組みの統合を実現するための基盤となるべきです。
1. データとアプリケーションの配置の重要性
意思決定のパフォーマンスに大きな影響を与える要素の一つは、データの物理的な配置です。ビジネスにとって、応答速度の速いアプリケーションは非常に重要であり、データとアプリケーション間の距離がパフォーマンスを左右します。
データがアプリケーションから離れれば離れるほど、通信の遅延が発生し、結果的にアプリケーションの処理速度が低下するため、データは近接環境に配置される必要があります。ただし、データ自体は物理的に動かせないため、アプリケーションがデータのあるプラットフォームに移動するのが一般的です。
2. 現状のITセットアップの課題
多くの企業では、ITインフラが段階的かつ場当たり的に拡大しており、その結果、プラットフォームが複雑で管理しにくくなっています。このような環境下で、企業の選択が将来の成長や効率性に長期的な影響を与えるため、リソースとプラットフォームの適切な組み合わせを実現することは、組織の成功に直結します。
最適な組み合わせの実現に向けた3つの要因
適切な質問を行う データとアプリケーションの要件を正確に把握し、将来のワークロードや拡張性を考慮した質問を行うことが重要です。
アプリケーションとデータの配置を分析する アプリケーションのパフォーマンスを最大化するためには、データとアプリケーションの配置を分析し、最適なインフラ構成を検討する必要があります。
プロセスの一貫性を維持する 選定プロセスや運用方針において、一貫した戦略を維持することで、長期的に柔軟かつ効率的なIT環境を構築できます。
実行に必要な要素
これらの要因を実行に移すためには、2つの要素が必要です。
組織全体の賛同
Cloud Business Officeなどの部門が中心となり、全社的なサポートを得ることで、意思決定プロセスをスムーズに進めることが可能です。
優れたテクノロジーツールの活用
拡張性と柔軟性を兼ね備えたデータ管理ツールを採用することで、データとアプリケーションの最適な配置やプロセスの自動化が可能になります。
データコンサルタントの提言
データとアプリケーションの配置戦略を明確化し、パフォーマンスを最大化するための環境を整備する。
長期的な視点でのITインフラの計画を策定し、拡張性と統合性を備えたデータプラットフォームを選定する。
全社的な賛同と適切なツールの導入を促進し、効率的なデータ管理と意思決定の基盤を確立する。
データ管理の重要性と業務への影響
効果的なデータ管理は、顧客体験の向上、リスク管理、コンプライアンス対応において非常に重要です。組織が断片化したデータを放置することは、顧客や業務に対して深刻な影響を与え、経営リスクを増大させる可能性があります。ここでは、データ管理の重要性とその影響について整理し、具体的な改善点を提案します。
1. 顧客データの断片化によるリスク
顧客体験の低下: 顧客データが断片化されていると、異なるタッチポイントでの顧客体験が一貫しなくなります。これにより、企業が提供するサービスや提案に誤りが生じ、顧客が自分が新規顧客のように扱われていると感じることがあります。これは、顧客の信頼を損ない、リピート率や顧客満足度に直接的な影響を与えます。
リスク管理の欠如: 組織が顧客データの全体像を把握できない場合、リスクエクスポージャを正確に特定、測定、管理することが困難です。この結果、コンプライアンス要件を満たすのに苦労するケースも増加します。
2. 業務部門とIT部門の課題
業務部門の課題
顧客透明性の欠如: 顧客に関する全体的な情報が欠如しているため、顧客のニーズや行動を理解するのが難しくなります。これにより、プロアクティブなサービス提供が困難になります。
顧客コストとサービス効率の低下: 顧客獲得コストやサービス提供コストが高くなる一方で、営業のコンバージョン率が低いことが問題です。顧客データが断片化されているため、適切なターゲティングができず、ワレットシェアの向上も困難です。
IT部門の課題
データソースの重複: 同じデータが異なるシステムで複数存在し、データの一貫性と整合性が保てない状況が多発しています。このため、エンティティ間の関係を把握するのが難しく、法定レポートの作成が遅れることもあります。
手作業によるコスト増加: データ照合に手作業が必要な状況は、効率を低下させ、コストを増大させます。ITリソースが限られる中、これらの手作業は他の重要な業務の遅延を引き起こすこともあります。
3. 顧客データ管理の改善策
MDM(マスターデータ管理)の導入: データ管理の改善には、まず顧客データを一元化し、各システム間での整合性を保つ**マスターデータ管理(MDM)**の導入が有効です。これにより、顧客データの重複や断片化を防ぎ、正確なデータ分析が可能になります。
顧客オンボーディングの効率化: 顧客のオンボーディングプロセスを迅速化するため、データの統一と住所情報などの整合性の確保が必要です。これにより、顧客対応がスムーズになり、顧客満足度が向上します。
4. リスク評価とデータの信頼性確保
MDMデータの信頼性を確保するには、関連するリスクを適切に評価し、管理することが重要です。次の要点に基づいて、データのリスクを評価し、セキュリティとプライバシーのガイドラインを強化する必要があります。
機密データの把握: どのデータが機密であり、保護が必要かを明確にします。
データの移動経路: データがエコシステム内でどのように移動するかを追跡し、データの安全な管理を確立します。
ユーザー認証と権限管理: ユーザーの認証プロセスと権限の管理を強化し、データアクセスの透明性を高めます。
データマスキングと暗号化: 必要に応じて、データのマスキングや暗号化を行い、データの漏洩リスクを低減します。
データコンサルタントの提言
データサイロの解消と顧客データの一元化を進め、業務の効率化と顧客体験の向上を図る。
リスク管理とコンプライアンス対応を強化するために、MDMの導入を検討し、データの透明性と一貫性を高める。
IT部門と業務部門の協働によるプロセスの標準化を進め、データの信頼性を高めるための仕組みを構築する。
データ管理と収集の重要性
データモデルやアルゴリズムは、使用されるデータの質によってその性能が大きく左右されます。もしデータが不完全であったり、偏りがあれば、アルゴリズムの精度が低下し、分析結果に誤差が生じる可能性が高まります。そのため、さまざまなデータソースを統合する際には、精度を保つための適切な方法が求められます。
また、データサイエンティストやアナリスト、開発者がプロジェクトに最適なデータにセルフサービスでアクセスできる体制が不可欠です。複数の権限設定やプライバシー管理、リアルタイムでの適切なデータユーザーへのアクセス提供、そしてデータ来歴の追跡を可能にするツールがあれば、これらの課題に対応することができます。
モデルの構築と導入における課題
データサイエンティストにとって、データのクリーニングや準備は手作業で行うことが多く、時間と労力がかかる非効率な作業です。一方で、データのマイニングやモデリングに注力することを好む傾向が強いため、これらの準備作業を自動化するためのツールやソリューションが重要になってきています。
また、モデルの構築からスケール化、トレーニング、そして導入までを一貫してサポートする統合ツールの不足が、データサイエンティストたちの共通の悩みです。複数のスタンドアロンツールを使うことは、システムの複雑化や、ガバナンスやコンプライアンスのリスク増加に繋がりやすくなります。さらに、モデル構築後にはソフトウェアエンジニアやAI運用、ビジネスアナリストとの連携が必須です。これを迅速に行うためには、各プロセスの自動化が成功の鍵となります。
モデルの監視と管理
モデルが導入された後も、そのパフォーマンスを定期的に監視・評価し続けることが重要です。時間と共にモデルの性能は劣化し、ドリフトやバイアスが生じる場合があるため、手動での検出はコストが高く、精度の欠如やガバナンス上のリスクを引き起こします。これにより規制対応の不備や顧客の信頼を損ねる可能性もあります。
そのため、モデルの監視と再トレーニングプロセスを自動化し、モデルライフサイクル全体におけるファクトの収集と可視化を行うことで、透明性を確保し、公平性と規制要件への準拠を強化できます。
データ管理と信頼性の確立
データ、モデル、プロセスに対する信頼性を確保するためには、AIライフサイクルの各段階での適切な自動化が不可欠です。もし自動化が不十分であれば、組織は次のような課題に直面するリスクがあります:
データの品質低下によりモデルの精度が損なわれる
プロセスの不透明さがコンプライアンスのリスクを増加させる
継続的な運用やスケーリングが困難になり、コストが増大する
このような課題に対応するために、AI導入に向けた計画、実行、制御が正確かつ効率的に行われるよう、各段階で特定の技術的な構成要素を組み込む必要があります。
必須機能と自動化の要素
各AIプロセスで信頼性を確立するためには、次のような機能が必要です:
データ統合の柔軟性:さまざまな導入環境で複数のタイプやソースのデータを統合する機能
セルフサービスアクセスと追跡可能性:プライバシー保護と来歴追跡機能を備えたユーザーセルフサービスアクセス
モデルの自動化:モデルの構築・導入・スケール化、トレーニング、監視と再訓練の自動化
ガバナンスの自動化:データ品質とコンプライアンスの維持を目的としたガバナンスの自動化
これらの要素を組織全体で統合することで、データの複雑性に起因する課題の解決が可能となります。そして、そのための基盤として「データファブリック」が重要な役割を果たします。
データファブリックの役割と利点
データファブリックとは、組織内のデータアクセスを簡素化し、セルフサービスでデータを有効活用できるようにするアーキテクチャです。この統合アーキテクチャには、各プロセスで必要な機能があらかじめ組み込まれており、複数のポイントソリューションを統合する際のコストや複雑性を軽減します。
データファブリックは、分散されたハイブリッドクラウド環境でも、分断されたデータを効率的に接続・統合・保護し、組織のデータ戦略を支援します。Gartnerによれば、データファブリックを導入することで、2023年までにデータ管理プロセスの最適化が進み、統合データの提供にかかる時間を30%短縮できると予測されています。
次のステップ
次のセクションでは、MLOpsおよび信頼性の高いAIを実現するために、データファブリックアプローチを導入した組織の成功事例について詳しく見ていきます。
製造業におけるデータ管理とAI技術導入の効果 – A社の事例から学ぶ
現代の製造業は、予測不能な顧客需要、サプライチェーンの非効率性、そして労働力不足といった数々の課題に直面しています。これらの課題に対処し、業務運用の効率を向上させるために、多くの企業がAIやデジタルテクノロジーを導入し、生産性の向上と供給網の管理強化に取り組んでいます。ここでは、スイスに本社を構え、ロボット、電力、電気機器、オートメーション技術を展開する多国籍企業であるABB社の例を基に、データ管理とAIの有効活用方法について具体的に解説します。
課題: データと知識の一元化と有効活用の必要性
A社では退職するセールスエンジニアの専門知識を含め、パイプ仕様の履歴データを効率的に活用・共有するための仕組みを構築する必要がありました。これにより、組織全体で蓄積された知識を損なうことなく高度な分析を活用し、業務運営へのインパクトを最大化することを目指しました。
ソリューション: エンドツーエンドのデータパイプライン構築
ABB社は、以下のエンドツーエンドのプロセスを構築することで、データから得られるインサイトを業務に活かしています。
データの標準化とクレンジング: 各部門で異なるデータ形式で保存されていた情報を一元化し、データ品質を確保。これにより、データの取り扱いが容易になり、AIによる分析が可能となりました。
機械学習による分析の導入: 例えば、アソシエーション・マイニングや教師なし学習などの技術を活用し、データに基づいた予測分析を実施。これにより、従来の手法では見逃していた隠れたパターンを明らかにすることができました。
インサイトを業務に反映するプロセスの整備: AIモデルから得たアウトプットをもとに、業務運営の効率化を実現するプロトタイプのWebアプリケーションを開発。これは特にセールスエンジニアがセルフサービスでデータを活用できるように設計されており、現場での即時利用を可能にしています。
成果: 効率化とコスト削減の実現
データ駆動型の新しいアプローチを導入したことで、ABB社は以下の成果を達成しました。
データインフラの透明性と複雑性の低減: 統合されたデータインフラにより、異なる部門間でのデータ利用が可能になり、データの透明性とアクセスのしやすさが向上しました。
新規セールスエンジニアのトレーニングコストとリソースの削減: データ駆動型の手法によって、知識の共有とデータの活用が容易になり、追加のトレーニングリソースを削減しました。
業務プロセスの高速化: パイプ仕様の作成プロセスにおいて、従来の月単位の作業が日単位で完了するようになり、大幅な効率化を実現しました。
履歴データに対する高度な分析の初実施: 過去の仕様データに対し高度な分析を行うことで、より精度の高い意思決定が可能となり、業務全体に革新的なインサイトをもたらしました。
コンサルタントからの推奨事項
企業が同様の成果を上げるためには、以下の3点に重点を置くべきです:
データ標準化の徹底: 異なる形式のデータを統一することで、AIや分析技術の適用が容易になり、精度の高い分析が実現します。
AI活用とプロトタイプ開発の併用: AIモデルの結果を即業務に反映できる環境を整備し、現場のニーズに応じたプロトタイプアプリケーションの導入を推進することで、迅速な意思決定が可能です。
データ駆動の教育体制強化: データ駆動型のアプローチを新しい人材育成にも活用し、トレーニングのコスト削減と迅速なオンボーディングを実現します。
これらの施策により、製造業におけるデータ管理とAI活用の可能性が一層拡がり、変動する市場や供給網に対しても高い柔軟性を発揮できる企業体制が築かれるでしょう。