
目次
データの価値と競争優位性
データが企業の未来を支える基盤に
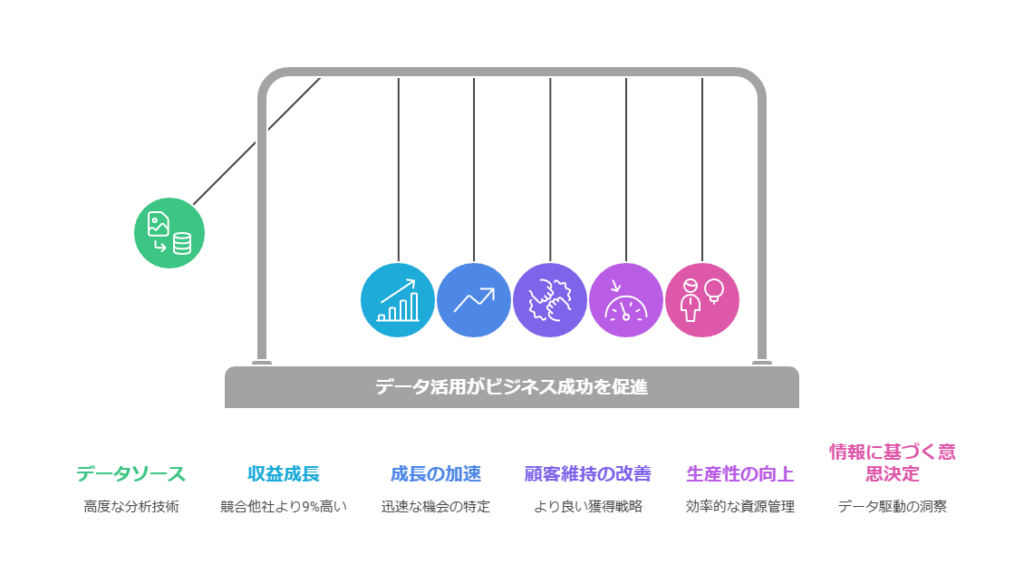
現代のビジネス環境において、データと分析は競争力を決定する重要な要素です。データを活用してビジネス価値を創出した企業は、他社よりも明確な優位性を築いています。たとえば、Aberdeenの調査によると、最新のデータレイク分析プラットフォームを導入した企業は、収益増加率で同業他社を9%上回る成果を上げています。
これらの成功事例では、以下のような多様なデータソース(例: ログファイル、クリックストリーム、ソーシャルメディア、IoTデバイスのデータ)を活用し、新しい分析手法(例: 機械学習)を採用することで、以下を実現しています:
迅速な機会の特定と対応
事業成長の加速
顧客獲得および維持の向上
生産性の向上
予測的な資産管理
十分な情報に基づく意思決定
データレイクがもたらす未来のイノベーション
クラウドベースのデータレイクが主流に
クラウド上に構築されたデータレイクは、企業のデータ戦略における中心的な存在となりつつあります。柔軟性の高いデータ処理環境を提供することで、意思決定者が必要なデータにすぐにアクセスできる仕組みを実現します。
データレイクの主な特徴:
形式を問わずデータを保存
Rawデータから処理済みデータまで、さまざまな形式で保存可能。
保存後もデータを転送・変換でき、将来の分析ニーズに対応。
イノベーションの土台としての役割
現時点で具体的な分析要件が未定でも、後から活用できるようデータを保持。
新しいビジネスモデルや技術革新のための基盤を構築。
エンタープライズデータ戦略における課題と解決策
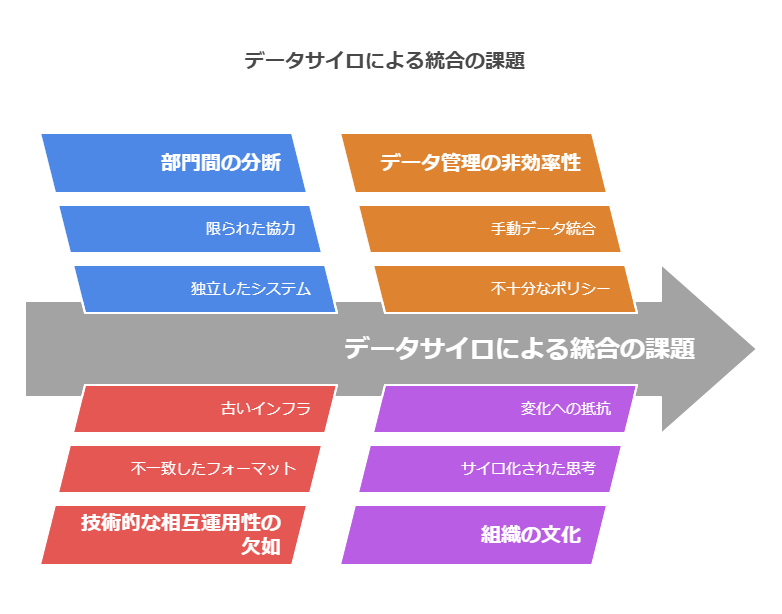
課題: データサイロの解消
従来、企業のデータ環境はさまざまな部門やシステムに分断され、データサイロ(孤立化)が課題となっていました。この状況では、以下のような制約が生じます:
データの統合やアクセスに時間とコストがかかる
全社的なデータ活用が困難
分断されたデータが意思決定を遅らせる
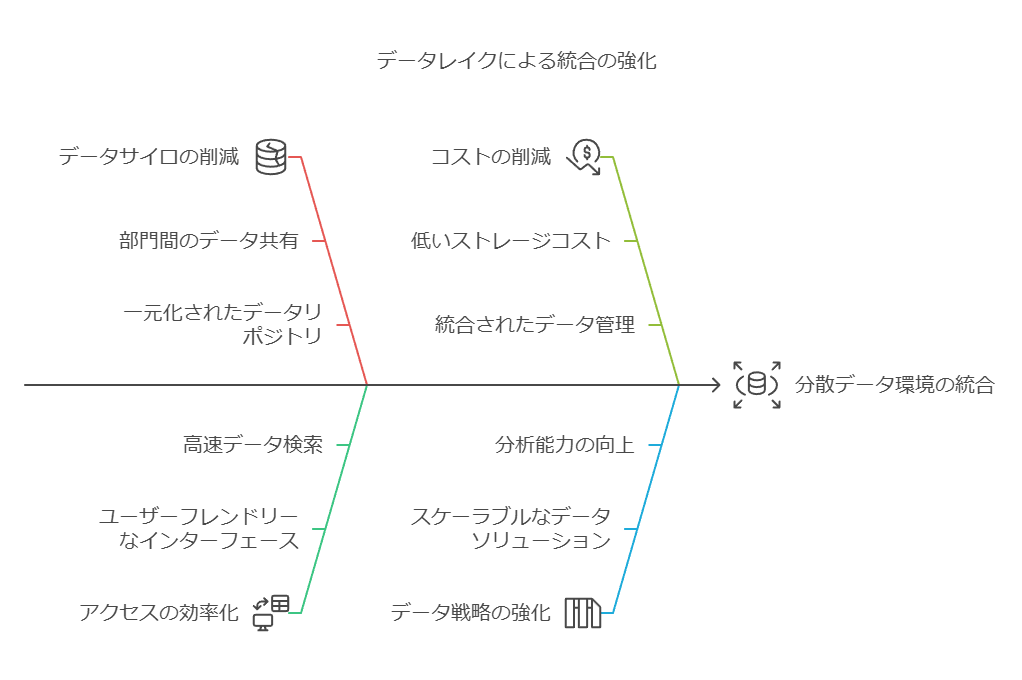
解決策: データレイクの統合力
データレイクは、分散したデータ環境を1か所に集約し、統合されたデータ基盤を提供します。これにより以下が実現します:
あらゆるデータ形式に対応:ビッグデータに含まれる構造化・非構造化データをそのまま保存し、即時活用が可能。
効率的なデータ統合:リアルタイムまたは必要に応じたデータ処理で、業務効率を向上。
セキュリティとガバナンスの強化:一元管理により、データセキュリティ基準やプライバシーポリシーを全社的に適用。
データレイクの戦略的価値
データレイクは、企業が新たな価値を創造するための重要な基盤です。分断された環境を統合し、データをフル活用することで、以下のような戦略的目標を支援します:
リアルタイムな洞察の提供:迅速な意思決定を可能に。
コスト効率の改善:従来のデータ処理基盤より柔軟かつ低コストで運用可能。
未来のイノベーションを見据えた準備:未知のニーズや新しいテクノロジーへの対応能力を高める。
データレイクは単なる技術的選択肢ではなく、企業の成長を支える戦略的な要素です。 今後、企業はデータレイクを活用してより競争力のある意思決定を行い、新しいビジネスチャンスを創出することが求められます。ビジネスの変革を実現するため、今すぐデータレイク戦略を検討することをお勧めします。
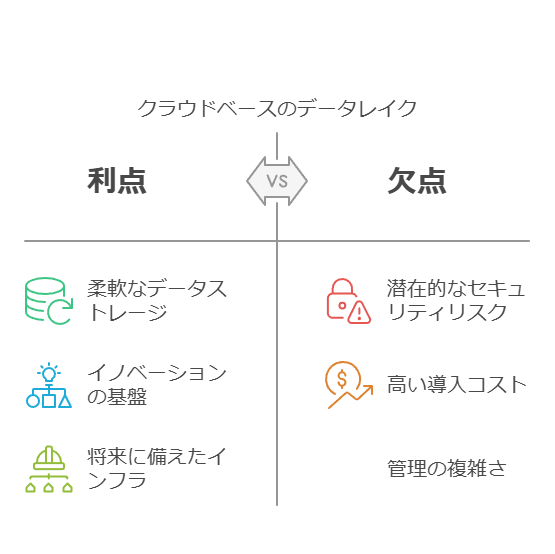
データレイクとは何か
データレイクは、構造化データから非構造化データまで、あらゆる形式・規模のデータを一元的に保存できるリポジトリです。その特長は、データを事前に変換したり構造化したりする必要がない点にあります。データをそのまま保存できるため、以下のような幅広い分析や処理が可能です:
ダッシュボードやデータ可視化
ビッグデータ処理
リアルタイム分析
機械学習やAIモデリング
これにより、ビジネスの意思決定が迅速かつ的確に行える環境を提供します。さらに、データレイクを活用することで、保存されたデータを整備・補正し、その後にデータウェアハウス(DWH)へロードするなど、エンドツーエンドのデータパイプラインの基盤としても利用可能です。
データウェアハウスとデータレイク:異なる役割と共存の必要性
異なる役割と特長
データウェアハウス(DWH)とデータレイクは、それぞれ異なる目的に応じた役割を果たします。
データウェアハウス:構造化データをもとに、高度に最適化されたクエリ処理や定型的なビジネス分析に適しています。
データレイク:多種多様なデータ形式をそのまま保存し、柔軟で実験的なデータサイエンスやリアルタイム分析に活用できます。
両方が必要となる理由
現代の組織は、データウェアハウスとデータレイクの両方を組み合わせることで、それぞれの長所を最大限に活かすことが求められています。以下はその具体例です:
データレイクを活用したデータウェアハウスの進化
データレイクをデータウェアハウスに統合することで、次のような高度な機能を実現できます:
より広範なクエリ処理能力の拡張
データサイエンスやAIユースケースの統合
新しい情報モデルや洞察の発見
このような進化を反映して、ガートナー社はこの統合型技術を「Data Management Solution for Analytics(DMSA)」と命名しています。DMSAは、データレイクの柔軟性とデータウェアハウスの高効率な処理能力を融合させ、組織が一貫性と即応性を持つデータ活用を実現するための基盤です。
データレイク活用の戦略的メリット
データレイクの導入は、次のような戦略的なメリットを企業にもたらします:
柔軟なデータ保存:現時点では活用が決まっていないデータもそのまま保存し、将来のニーズに対応可能。
分析の多様性を支援:リアルタイム分析やAI/機械学習を含む、従来のDWHでは対応が難しい分析が可能。
スケーラビリティとコスト効率:クラウドベースのデータレイクにより、必要なリソースを柔軟に調整可能。
データの一元化:複数のソースからのデータを統合し、サイロ化を解消。
データレイクとデータウェアハウスは競合する技術ではなく、互いを補完し合う存在です。 組織のデータ戦略において、この2つをどのように統合し運用するかが、データドリブンな意思決定やビジネスイノベーションの鍵となります。企業の競争優位性を強化するため、今後のデータ基盤の進化を視野に入れた統合的アプローチを検討することが重要です。
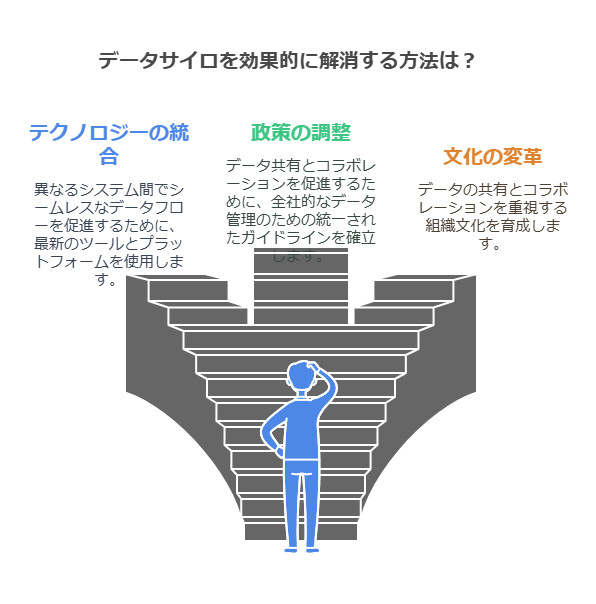
データ収集からデータ分析へ
データが収集された後、それが次に活用されるのはデータ分析のプロセスです。多くの場合、この分析はデータレイク内で実行され、業界基準や特定のニーズに応じた専用のデータ分析ソフトウェアによって評価されます。この段階で、データキュレーターやデータサイエンティストがツールを用いてデータを掘り下げ、そこから得られる洞察を意思決定者に提供する役割を果たします。
データレイクは、異なるデータソースを統合することで、データのサイロ化を解消し、従来は見落とされがちだった無関係に見えるデータ要素を結びつける能力を提供します。このようにして、データはより包括的な視点から分析され、これこそが企業にとって競争優位性を生む源泉となります。
ストレージの重要性とデータ戦略への影響
ストレージは、データの収集、分類、分析に密接に関与しており、これは企業のデータ戦略にとって欠かせない要素です。特に、リアルタイムでのデータ報告や高度な分析が求められる環境では、保存されたデータを正確かつ効率的に管理し、ワークフロー、セキュリティ、リソース管理を最適化することが必要です。そのため、企業は高度なデータ管理ソリューションと分析ソリューションの導入に対する需要を高めています。
ストレージのイノベーションとデータの価値
企業がデータから得る価値は、データの保存方法や保存場所によって大きく左右されます。ストレージのイノベーションは、データの価値に直接的な影響を与え、特に以下のような分野においてその効果が現れます。
マスキャパシティ(大規模データ保存):規模の経済は、データストレージの効率性と価値を高める重要な要因です。アクセス可能なデータセットが大きいほど、分析の精度が向上します。そのため、データ管理は最新のAIや機械学習(ML)技術を利用し、物理的にもすべてのデータにアクセス可能な環境を整える必要があります。
面密度の向上:データストレージ企業、特にSeagateなどは、面密度の向上に開発の焦点を当てています。面密度が高まることで、デバイスが一定面積あたりに保存できるデータ容量が増え、これによりデータの保管とアクセス効率が大幅に向上します。
データコンサルタントとしての提言
データの統合管理を進めることで、サイロを解消し、異なるデータセットから新たな関連性や洞察を引き出すことが可能となります。
ストレージ戦略は、データ収集から分析までのプロセス全体に影響を与えるため、企業の成長戦略における重要な要素です。
リアルタイム分析のニーズに応えるため、適切なストレージ技術を採用し、ワークフローの最適化とセキュリティ強化に向けた対応を進める必要があります。
面密度の向上は、データストレージの効率性を高め、将来的なデータ管理のコスト削減とパフォーマンス向上を実現するための鍵となります。
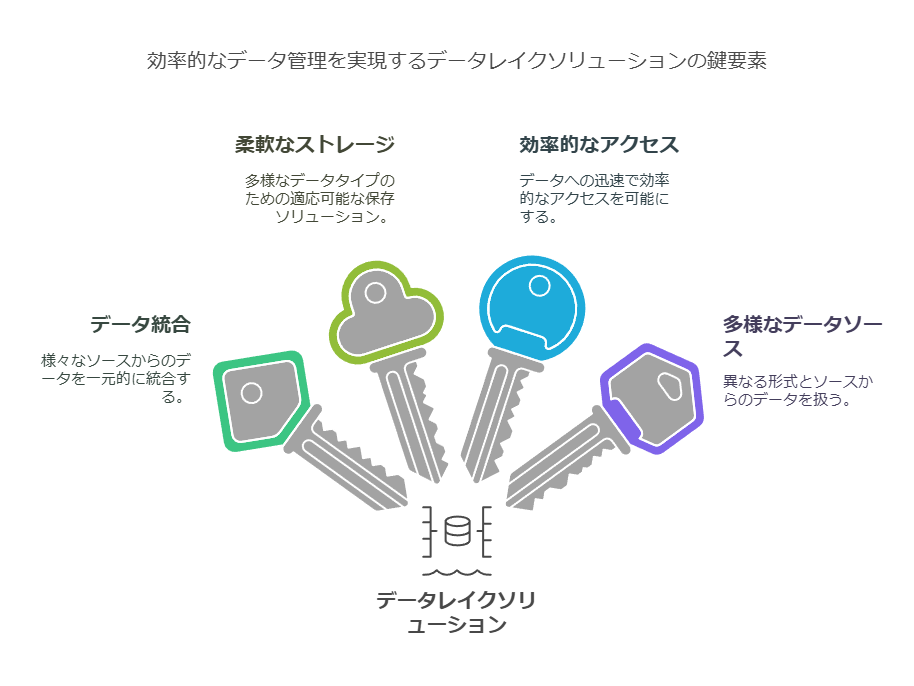
データレイクソリューションの概要
データレイクソリューションは、企業が保有する膨大なデータを効果的に管理し、多様な用途に活用するための戦略的なデータ管理アプローチです。これにより、非構造化データ、テキストファイル、RDBMSなど、様々なデータソースを一元管理し、データの保存やアクセスが柔軟かつ効率的になります。
センターデータ: 企業の主要なデータセットを集約・管理
非構造化ファイル: 自由なフォーマットのデータを保存
API連携: データアクセスを統一するためにAPIを活用
サイズ制限からの解放: データ保存容量の制約がなく、大量データの収集が可能
データロスの防止: 信頼性の高いデータ保管
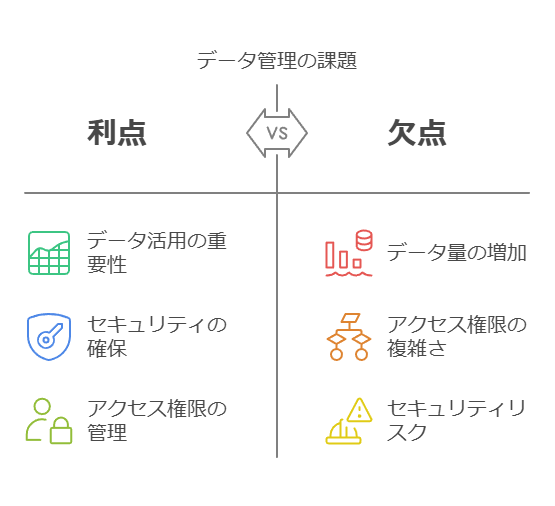
お客様が直面するデータ管理の課題
企業が直面するデータ管理の課題は多岐にわたります。特に、データ量の増加やアクセス権限の管理、セキュリティの確保などは、効果的なデータ活用における重要な要素です。
増え続けるデータの種類とボリュームへの対応: 多様化するデータソースに対応する柔軟な管理体制が必要です。
全社員がデータを活用できる仕組みの構築: データにアクセスできる権限や運用手順を明確にし、全ての社員がデータ活用の恩恵を受けられる環境を整備します。
セキュリティとコストの両立: 高いセキュリティ基準を維持しながら、コスト効率の良いデータインフラを構築することが求められます。
多様な分析ニーズの対応: 定期レポート、リアルタイム分析、予測分析、さらには音声・画像データやIoTデータを活用した分析など、異なるニーズに対応する柔軟なソリューションが必要です。
データの一元管理と迅速な意思決定
企業がデジタル成熟を続ける中で、全てのビジネス段階でデータの重要性は変わりません。迅速で正確な意思決定には、リアルタイムで信頼性の高いデータへのアクセスが不可欠です。
単一のデータ環境の構築: データを一元的に管理し、組織内の意思決定者が必要なデータに迅速にアクセスできる環境を整備することで、業務のスピードと精度が向上します。
適切なアクセス権限の設定: データアクセスに関する権限を明確にし、各役職に応じたデータ利用の範囲を適切に設定することが、データの安全性と効率的な活用に繋がります。
課題解決のアプローチ
企業がデータ管理の課題に直面した際、重要なのは早期に適切なソリューションを導入することです。たとえば、過去にデータアクセスを限定的に設定したため、データ活用が進まなかったケースでは、権限の再設計によってより多くの社員がデータにアクセスし、データ分析が進むことで、企業全体のパフォーマンスが向上しました。
結論 データレイクソリューションは、企業がデータの多様性や増加に柔軟に対応し、意思決定を強化するための鍵となります。正確なデータ管理とアクセス権限の整備により、セキュリティを担保しつつコストを抑え、全社的なデータ活用の促進を実現します。
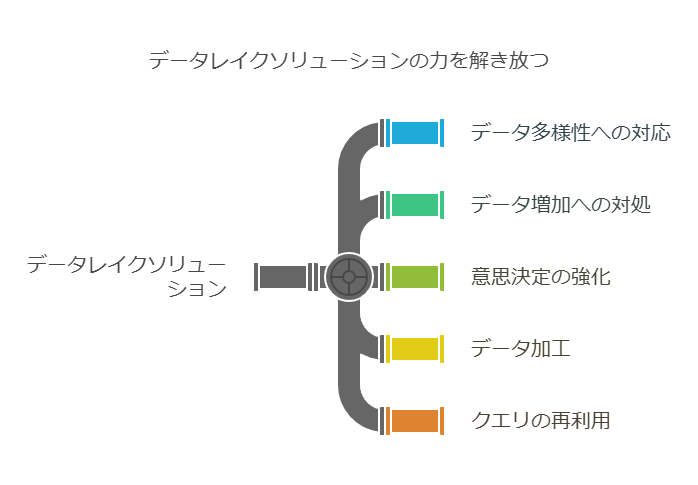
データの加工とクエリーの再利用が行える環境
データレイクの価値を最大限に引き出すためには、データの加工やクエリーを再利用できる環境が整備されていることが重要です。これにより、データアナリストやデータサイエンティストが効率的にデータを処理し、ビジネスインサイトを得ることが容易になります。
データレイクと他のデータ管理システムの違い
データレイクが提供する価値は、既存のデータウェアハウスやデータマート、またはオペレーショナル・データストア (ODS) とは異なります。これらは、構造化データの保存や高パフォーマンスな本番環境向けに設計されています。一方、データレイクは、大量の非構造化データを扱い、多様な分析用途に対応する柔軟な基盤を提供します。
特定用途のシステムとの連携
データレイク自体は、特定の問題解決のために設計されたシステムではありませんが、適切なデータマートへのフィードによって、特定のビジネスニーズに対応するシステムを構築することが可能です。これは、データレイクを最適化するためのベストプラクティスに基づいています。
データレイク最適化のためのステップ
データスワンプを避け、データレイクの運用を最適化するためには、以下のステップに従うことが重要です。
データリポジトリーの構築
企業は、構造化データと非構造化データの両方を扱えるリポジトリーを構築します。リポジトリーごとに異なるワークロード機能を提供し、特定のデータを効率的に処理できるようにします。また、データの種類やビジネスニーズに応じて、新規リポジトリーを追加し、不要になったリポジトリーは適時削除する柔軟な運用が求められます。
データレイク・サービスの実装
データレイクを運用するためには、データレイク・サービスの実装が必要です。このサービスは、アナリスト、データサイエンティスト、開発者、ビジネスユーザーがデータにアクセスし、利用できるようにするための機能を提供します。さらに、データの同期やデータカタログの維持管理を通じて、ユーザーが必要なデータを迅速に見つけ出し、そのデータが作業に適しているかどうかを確認できる環境を整備します。データリネージュ(データの来歴情報)も提供することで、データの信頼性が高まり、意思決定の精度が向上します。
包括的な情報管理とガバナンスの確立
データレイク運用において、包括的な情報管理と情報ガバナンスのフレームワークを構築することは不可欠です。このためには、データの移動、加工、保護を支えるミドルウェアの実装が求められます。具体的には、以下の機能が重要です。
プロビジョニングエンジン:データの移動や加工を行い、データ処理プロセスの効率化を図る。
コラボレーションを促進するワークフローエンジン:データを扱うチーム間での連携を強化し、より効率的なデータ処理が可能になる。
モニタリング、アクセス制御、監査機能:データの利用状況を把握し、アクセス権限を適切に管理することで、セキュリティとコンプライアンスを確保する。
このようなデータレイクの最適化とガバナンス強化により、企業はデータから最大限の価値を引き出し、ビジネスにおける意思決定を支援するデータ駆動型の環境を構築できます。
データレイクとデータファブリックの違いについて
データレイクとデータファブリックは、企業のデータ戦略において重要な役割を果たしますが、目的や機能が異なります。
データレイクは、企業が生成する大量のデータを蓄積するための保存場所です。構造化データ、非構造化データを含む様々な形式のデータをそのまま保存し、後で分析や活用のために利用可能な状態にします。しかし、データレイクだけでは、そのデータを直接有効活用するのは難しいことが多いです。
一方で、データファブリックは、こうしたデータレイクに保存されたデータや、その他の分散されたデータ資産を効率的に接続し、統合し、利用可能にするための仕組みです。データファブリックは、リアルタイムにデータを収集、分析し、企業全体のデータ資産を横断的に活用できる環境を提供します。多くの専門家は、データレイクの価値を最大化するためにはデータファブリックのようなアプローチが不可欠であると指摘しています。
データ活用の重要性と複雑化する環境
現代の企業は、多種多様で膨大なデータを日々生成しています。クラウド、ビッグデータ、IoTなどから生まれるデータは、それぞれ異なる形式や速度で生成され、データ活用の環境は一層複雑化しています。これに伴い、データをいかに迅速かつリアルタイムで意思決定に活用できるかが、企業競争力を左右する重要な要素となっています。
従来のデータ基盤の課題
従来、多くの企業は部門ごとに最適化されたデータ基盤(DWHやBIツール)を導入してきましたが、これによりデータがサイロ化し、部門間でのデータ統合が難しい状況が生まれています。サイロ化されたデータの統合には、従来のETL/ELT処理では多大な時間とコストがかかり、データの鮮度も低下し、リアルタイム分析が困難になるという問題がありました。
データ仮想化による課題解決
データのサイロ化や統合に関する課題を抱えている企業に対して、近年注目されているのがデータ仮想化です。データ仮想化を用いることで、従来のETL/ELTプロセスを回避し、データを物理的に移動させることなく、リアルタイムに複数のデータソースを統合し活用することが可能になります。これにより、コスト削減や迅速なデータ収益化が実現し、企業のデータ戦略を強化する効果があります。
フォレスター社の2021年のレポートによれば、データ仮想化は従来型のアプローチに比べ、コストや人的リソースを大幅に削減できることが実証されています。このため、国内外の大手企業は、データ仮想化を採用し、データ管理の効率化とリアルタイムなビジネスインサイトの獲得に成功しています。
データレイクとデータファブリックは、企業がデータを適切に蓄積・活用するための重要な要素ですが、それぞれの役割を理解し、正しく組み合わせて活用することが鍵です。また、データ仮想化の導入により、データのサイロ化や統合の課題を解決し、より効率的なデータドリブン経営を実現することが可能です。
より正確な洞察と効果的な意思決定の実現
データレイクを導入することで、企業はユーザーが多様なデータセットにアクセスできる環境を整え、データの準備と処理を迅速に進められるようになります。これにより、より精度の高い洞察が得られ、ビジネス上の重要な意思決定をより効果的に行うことが可能になります。
適切に設計されたデータレイクは、データの**リネージュ(来歴)**を追跡・管理することで、データの信頼性を確保します。このように、信頼性のあるデータを基にした意思決定は、企業の競争力を高める重要な要素となります。
データレイクがIT部門にもたらすメリット
データレイクは、ビジネス部門だけでなく、IT部門にも大きな利点を提供します。たとえば、データレイクを導入することで、IT部門は継続的に増大するデータに対処できる柔軟なスケーラビリティを手に入れます。さらに、Hadoopのようなビッグデータ技術を組み込むことで、大規模なデータ分析を低コストで実行可能な環境を構築できます。
データレイクは、リソースの効率的な割り当てを実現し、緊急のビジネス課題に対しても迅速に対応できる柔軟性を提供します。また、ハイブリッドクラウド環境を利用することで、コストを最小限に抑えながらリソースを追加できるため、企業のデジタルインフラを将来にわたって拡張する準備が整います。
データレイクとエンタープライズデータウェアハウス(EDW)の役割の最適化
データレイクを導入することで、エンタープライズデータウェアハウス(EDW)の役割をより効率的に再配分することが可能です。具体的には、EDWの高コストなリソースを節約し、パフォーマンス分析や履歴データのモニタリングなど、EDWが得意とするタスクに専念できるようになります。
データレイクは、セルフサービスによるアナリティクス環境を実現し、EDWのサービスレベルアグリーメント(SLA)に影響を与えることなく、ユーザーが直接データにアクセスして分析を行えるようになります。
迅速な分析と俊敏な意思決定を支えるデータレイクの実装
データレイクは、企業が大量のデータを活用して迅速かつ俊敏に分析を行い、意思決定を改善するための強力な基盤を提供します。適切なベストプラクティスを取り入れたデータレイクの構築により、データの信頼性とセキュリティを確保しながら、組織全体で多様なデータに柔軟にアクセスできる環境を提供することが可能です。
企業の特定のニーズに合わせて最適化されたデータレイクは、ビジネスの俊敏性を向上させ、変化する市場環境に迅速に対応できる弾力性のあるビジネスを構築するための鍵となります。
データレイクの活用で得られる多様なメリット
データレイクを効果的に活用することで、企業はデータ環境から実用的なビジネスバリューを迅速かつ効率的に導き出すことが可能です。適切なデータレイクの構築により、以下のメリットが期待できます。
広範なデータへの迅速なアクセス
データレイクは、企業内の構造化データおよび非構造化データを、オンプレミスやクラウド環境を問わず統合的に扱うことができます。これにより、ユーザーは従来のようにIT部門に依頼せずとも、必要なデータに必要なタイミングでアクセスできる環境が整います。ビジネス部門が自律的にデータ活用を進めることで、意思決定のスピードが向上します。
データ準備の高速化
データレイクは、データカタログやデータリネージュを活用してデータの特性や来歴を可視化し、迅速なデータ準備を可能にします。また、ハイブリッドクラウドインフラを利用することで、データを最適な場所に配置し、アクセスやクエリの高速化を実現します。これにより、データの探索や再利用が効率的に行え、ビジネスニーズに迅速に対応できるようになります。
ビジネスの俊敏性向上
データ準備が迅速に行われると、ユーザーはより多くのデータを探索し、分析モデルの構築やテストに時間を費やすことができます。サンドボックス環境を活用して試行錯誤を繰り返し、最適な分析方法に迅速に移行することが可能です。これにより、データドリブンな意思決定が強化され、ビジネスの俊敏性が大幅に向上します。
データレイクの導入による価値最大化の戦略
データレイクの設計と構築において、企業は拡張性の高いアーキテクチャを採用し、スケーラブルなデータストレージ基盤を構築することが重要です。これにより、データが増加しても柔軟に対応でき、データスワンプを回避しながらクリーンで信頼性の高いデータ環境を維持できます。
データカタログやリネージュ機能を活用することで、データの信頼性や透明性を高め、ユーザーは必要なデータを素早く見つけることができ、データのビジネス活用に対する信頼性を向上させることができます。
このようなデータレイクの戦略的な活用により、企業はデータから価値を引き出しやすくなり、ビジネスにおける競争力を強化することが可能になります。
データコンサルタントの視点で、データサイエンティストやデータエンジニア間のコラボレーション、データレイクの運用、データ品質の確保について記載しました。
データサイエンティストとデータエンジニア間のコラボレーション促進
ビジネス部門のデータ活用を最大化するためには、データサイエンティストとデータエンジニアが緊密に連携し、役割分担を明確化することが重要です。データサイエンティストは高度なデータ分析によりビジネスインサイトを引き出し、データエンジニアはスケーラブルなデータレイク基盤を構築し、データの提供と管理を効率化します。両者のコラボレーションにより、企業全体のデータ活用が大幅に向上します。
データ品質、セキュリティ、ガバナンスの強化
データレイク環境において、データの品質、セキュリティ、ガバナンスは不可欠な要素です。これにより、プライバシー保護や法令遵守を確保しながら、信頼性が高く、ビジネスユーザーにとってわかりやすいデータを提供できます。データガバナンスを徹底することで、企業全体で一貫したデータ活用が実現し、リスクを最小限に抑えることが可能です。
スケーラブルなデータ基盤によるコスト効率化
急速に増大するデータ量に対処するためには、スケーラブルなデータ蓄積基盤が重要です。適切なデータ基盤を設計・導入することで、既存リソースを最大限に活用しつつ、コスト効率の高いデータ処理が可能となります。これにより、企業は短期的なデータ増加に対応し、長期的なデータ戦略の実現に向けた柔軟な基盤を確立できます。
データスワンプの回避とデータレイクの最適化
データレイクの成功は、適切な計画とガバナンスがあってこそ実現されます。計画が不十分であると、整理されていないデータが蓄積され、結果としてデータスワンプ(未整備のデータの沼地)となり、データの信頼性や可視性が損なわれます。データスワンプに陥ると、ユーザーはデータの出所や正確性に疑念を抱き、適切なデータ活用が困難になります。データレイクを最適化し、適切に管理された環境を維持することで、こうしたリスクを回避し、効率的なデータ運用を可能にします。
データレイクが提供する価値と機能
データレイクは、次のような機能を提供し、企業のデータ活用を支えます。
大量の生データへのアクセス環境:ビジネスユーザーやデータサイエンティストが、必要なデータに素早くアクセスし、分析を行うための環境を提供します。
分析モデルの開発と本番環境への移行:データレイク上でモデル開発・検証を行い、迅速に本番環境へ移行できるワークフローを実現します。
分析用サンドボックス:ユーザーがデータ探索を行い、試行錯誤しながらビジネスインサイトを獲得できる柔軟な分析環境を提供します。
全社的なデータカタログ:データの発見や、ビジネス用語と技術的メタデータを結びつける全社的なデータカタログにより、データの可視性を向上させ、データ活用の促進を図ります。
データレイクは、単なるデータの保管場所ではなく、企業のデータ活用を加速させる戦略的な基盤です。適切な設計と運用を行うことで、企業はデータから価値を引き出し、ビジネス成長に貢献できる体制を構築できます。