
目次
- 1 データレイクの基本的なデータ構造と課題の整理
- 2 データコンサルタント視点での「データレイクハウスへの進化」
- 3 データコンサルタント視点での「データ管理の進化とデータレイクハウスの登場」
- 4 データコンサルタント視点での「データ整合性とデータレイクの役割」
- 5 データコンサルタント視点での「データ・ガバナンスとデータサイエンスソリューション」
- 6 インテリジェントデータレイク設計の重要な検討事項
- 7 インテリジェントなデータレイク導入の必要性
- 8 データレイクの概念とアプローチ
- 9 インテリジェントデータレイクの青写真
- 10 データレイクの登場と利点
- 11 データレイクハウスの台頭と未来のデータ管理
- 12 データレイクと分散クエリエンジンの最適化
データレイクの基本的なデータ構造と課題の整理
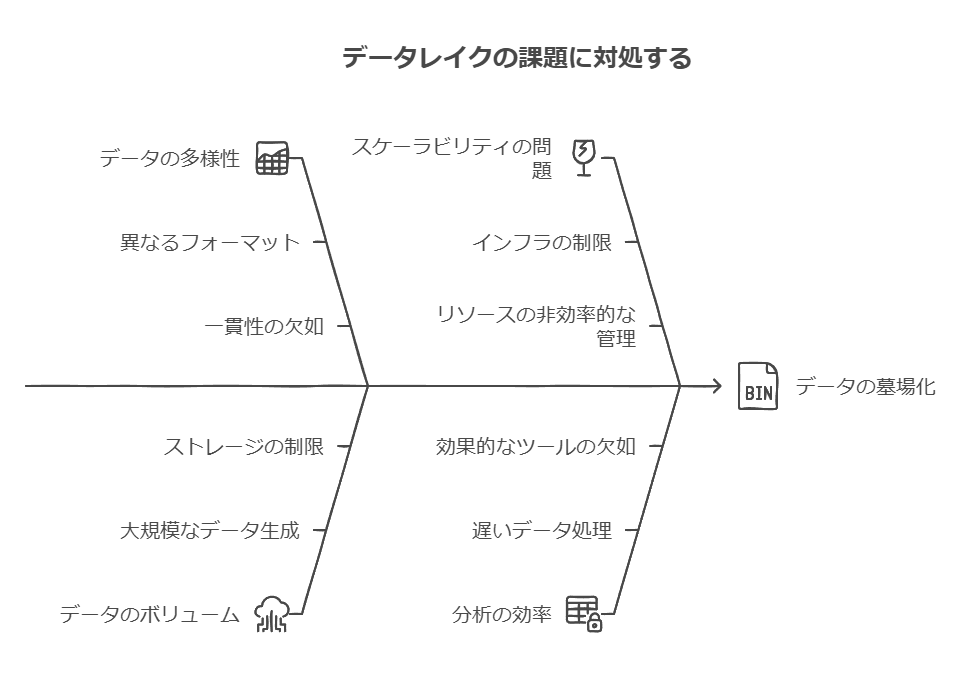
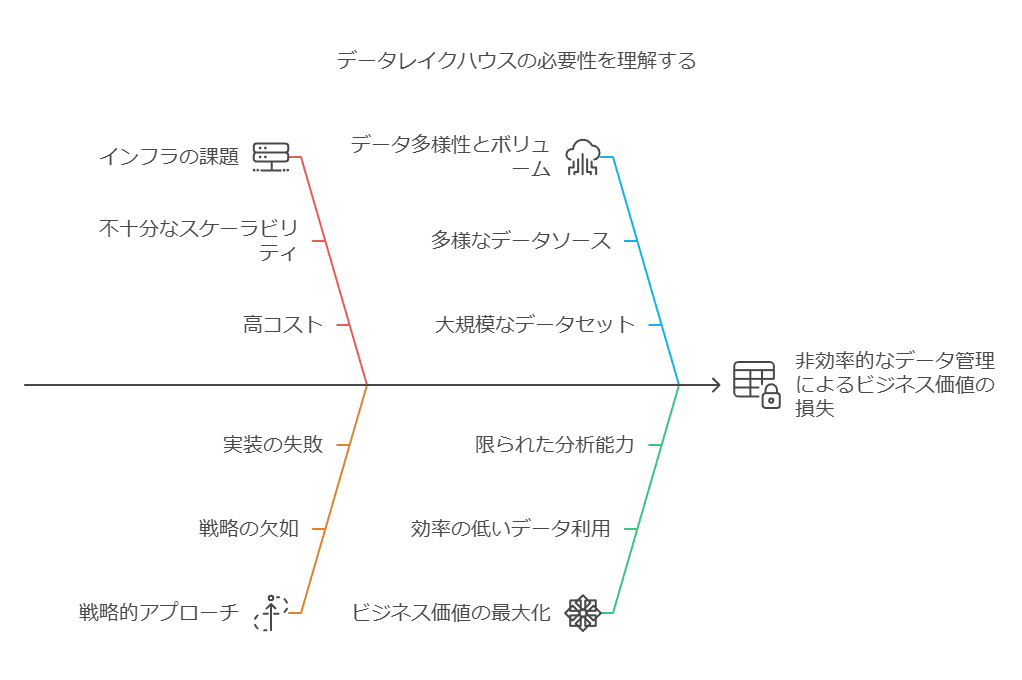
データレイクは、企業が様々な形式のデータを一元的に格納するためのリポジトリです。これには、従来の構造化データ(リレーショナルデータベースなど)、テキストデータ(ドキュメント、ログファイル)、およびIoTやアナログセンサーからの非構造化データが含まれます。この多様なデータの取り扱いにおける主な課題の一つは、従来のデータウェアハウスと比較して、特にIoTやアナログデータの形式や構造が大きく異なることです。
データレイクの課題の複雑化に関する説明
さらに、この課題を複雑にしているのは、データ量の違いです。特にIoTデバイスやアナログセンサーからのデータは、他の種類のデータと比べて桁違いに膨大です。これにより、データ管理のスケーラビリティや効率的な分析のためのインフラ整備が不可欠になります。データの多様性とボリュームの違いを考慮しないと、データレイクが”データの墓場”になりかねません。
データレイクハウスの概念導入
企業は、あらゆるデータをオフロードする場所としてデータレイクを利用している。 データレイクが、 Apache Parquet や ORC などの汎用的でオープンなファイル形式でデータを保持するファイルAPIを備え また、低コストのストレージシステムであることが主な理由である。
多くの企業は、データレイクをあらゆる種類のデータを効率的に保存するためのプラットフォームとして利用しています。その主な理由は、Apache ParquetやORCなどのオープンで汎用的なファイルフォーマットをサポートしていることと、低コストでスケーラブルなストレージシステムを提供できる点です。このオープンフォーマットにより、データレイクは機械学習や高度な分析を行う際に、データを直接アクセス可能な状態に保つことが可能となります。
データ利活用における現実的な問題
初期のデータレイクの利用モデルでは、企業はデータを単にデータレイクに保存すれば、それだけでエンドユーザーが容易に検索・分析できると考えていました。しかし、実際には、データを保存することと、そのデータを効率的に利活用できることは全く別の課題です。特にエンドユーザーとデータサイエンティストでは、求められるデータ処理のニーズや分析手法が大きく異なるため、単純なデータ保存モデルでは不十分であることがわかってきました。
全体を通して、データの種類や構造の違い、データ量の爆発的な増加、そしてエンドユーザーとデータサイエンティストの異なるニーズを考慮したインフラの整備が、現代のデータレイクの運用における主要な課題です。データレイクハウスは、これらの問題を克服するための一つのアプローチとして注目されています。

データコンサルタント視点での「データレイクハウスへの進化」
データレイクハウスへの進化のスピードと意義
進化には通常、長い時間がかかります。データ管理の分野でも、進化は一見ゆっくりであり、日々の変化は分かりにくいかもしれません。しかし、1960年代に始まったコンピュータ技術の進化は、他の分野とは異なり、非常に高速で急速な変革を遂げています。この急速な進化が、今日のデータレイクハウスという革新的な技術へとつながっています。
テクノロジーの進化とデータ管理の変遷
かつて、コンピュータ技術は非常にシンプルなものでした。データを取り込み、処理し、出力するという単純なプロセスが主流でした。最初の記録媒体である紙テープは、データの記録量が限られ、固定フォーマットに依存していたため、柔軟性に欠けていました。
次に登場したのがパンチカードですが、これも固定フォーマットの問題を抱えており、管理が煩雑で効率的とは言えませんでした。この段階では、データの管理と利用に関して多くの制約が存在していました。
その後、磁気テープが導入され、データの管理方法に大きな進展がありました。膨大な量のデータを保存できるようになり、フォーマットの柔軟性も向上しましたが、特定のデータを検索するには全体を順番に処理する必要があり、効率性の面では課題が残りました。また、磁気テープの脆弱性も、長期的なデータ保存には適していませんでした。
ディスクストレージの登場とデータアクセスの飛躍
このような課題を解決したのが、ディスクストレージの登場です。ディスクストレージはデータへの直接アクセスを可能にし、順次検索を必要としない効率的なデータ処理を実現しました。初期の段階ではコストや供給の制約がありましたが、時間とともにコストが低下し、ストレージ容量も増加したことで、企業における利用が広がりました。
オンライントランザクション処理 (OLTP) の革命
ディスクストレージの普及によって、データの直接アクセスが可能となり、オンラインでのトランザクション処理(OLTP)システムが現実のものとなりました。この技術進化により、企業はコンピュータがビジネスの中核を担う存在となることを実感し始めました。今日では、OLTPはオンライン予約システム、銀行システム、ATMシステムなど、顧客との直接的なインタラクションを支える重要な基盤として利用されています。
初期のコンピュータは、繰り返し処理に最適化されていましたが、OLTPシステムの導入によって、コンピュータがリアルタイムで顧客と対話できるようになり、ビジネス価値が大幅に向上しました。企業にとって、データと顧客とのダイナミックな接続を可能にするこの進化は、競争力を大きく強化する要素となりました。
データレイクハウスへの移行
こうした技術の進化の延長線上にあるのが、データレイクハウスです。これまでのデータストレージと処理技術の利点を組み合わせ、柔軟性と効率性を提供するデータ管理ソリューションとして、企業のデータ戦略に大きな変革をもたらしています。データレイクハウスは、単なる技術革新ではなく、ビジネスの成長とデジタルトランスフォーメーションを推進するための重要なステップです。
データコンサルタント視点での「データ管理の進化とデータレイクハウスの登場」
アプリケーションとデータの複雑化
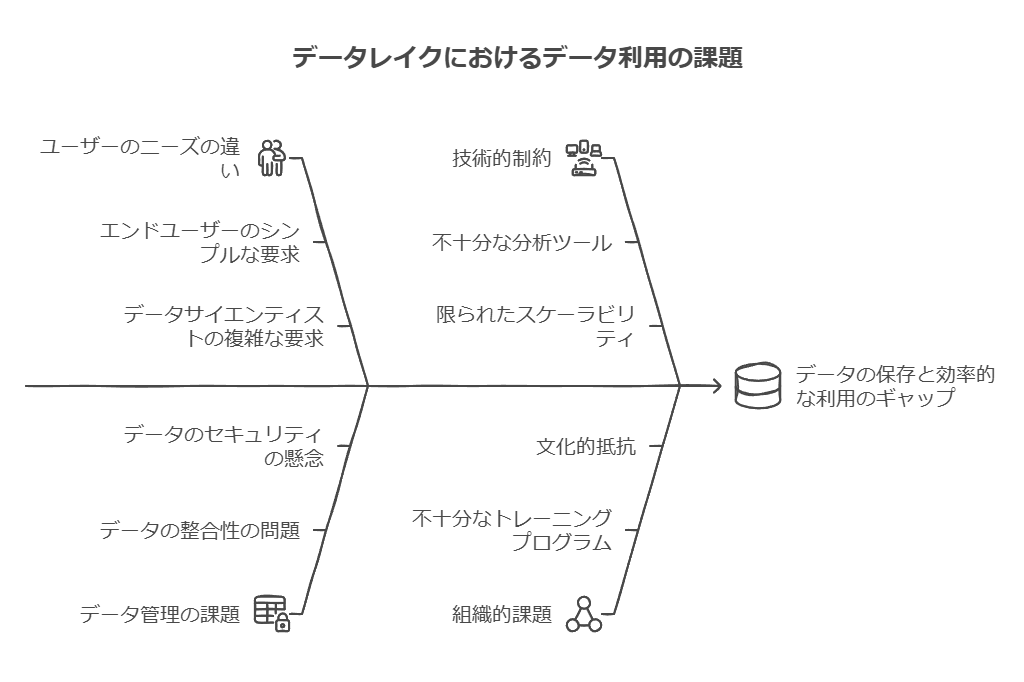
かつてのアプリケーションはシンプルで、扱うデータも比較的単純でした。しかし、現在ではデータの多様化が進み、膨大な量のデータが様々なソースやデバイスから生成されています。これには、テクノロジー、ハードウェア、IoTデバイスなどの多様なガジェットも含まれ、データ管理はかつてないほど複雑化しています。
データの種類と管理の課題
組織が分析に利用するデータは主に3種類に分類されます。
構造化データ: これは最も古くから存在するデータで、主にトランザクションを通じて生成されます。関係データベースなどで扱われる、整然としたフォーマットのデータです。
テキストデータ: 電子メール、コールセンターの会話、契約書、医療記録などから生成される非構造化データです。以前はこれらのデータは保存するだけで、分析には利用できない「ブラックボックス」として扱われていましたが、現在ではテキストETL技術の発展により、標準的な分析が可能になっています。
アナログ/IoTデータ: ドローンやセンサー、カメラ、スマートウォッチなどのデバイスから生成されるデータです。このデータは構造化データやテキストデータとは異なり、多様で不規則な形態を持つことが多く、その処理には特別な技術とインフラが必要です。
データレイクの限界と新たな課題
以前、これらの多種多様なデータはすべて「データレイク」と呼ばれる大規模なストレージシステムに蓄積されていました。しかし、組織は次第にデータをただ蓄積するだけでは有効な分析に繋がらないことに気づき始めます。データレイクを有効に活用するためには、以下の2つの条件を満たすことが必要です。
データの関連付け: 蓄積されたデータを相互に関連付け、分析に適した形に整理すること。
データのアクセス性の向上: エンドユーザーが必要なデータに容易にアクセスできるように、分析インフラを整備すること。
これらの要件を満たさない場合、データレイクは「データスワンプ」(データの沼地)と化し、膨大なデータが有効に活用されないまま放置される結果となります。結果として、データレイクは維持コストだけが増大し、無駄な負債となりかねません。
データレイクハウスの登場:有用性と生産性を実現
こうした問題を解決するために登場したのがデータレイクハウスです。データレイクハウスは、データレイクの弱点を補完し、データの活用と分析を容易にするための構造を提供します。これにより、単なるデータの蓄積に終わらず、データの有用性を最大限に引き出すことが可能となりました。データレイクハウスを活用しないデータレイクは、高コストなだけでなく、分析やビジネス価値の創出において大きな障害となります。
分析インフラの要素
データレイクハウスを効果的に活用するには、分析インフラの整備が必要不可欠です。分析インフラは、以下のような要素で構成されます。
メタデータ管理: データのカタログ化やリネージ管理(データの生成過程の追跡)を行い、データの利用効率を高める。
トランスフォーメーション履歴: データ変換の過程を記録し、分析に必要なデータ処理を透明化する。
さらに、データレイクハウスは共通コネクタを活用することで、異なる種類のデータ間の連携を実現します。共通コネクタが存在しないと、データを関連付けて分析することが難しくなりますが、これを活用することで、さまざまな形式のデータを効率的に統合し、より高度な分析が可能になります。
結論:データレイクハウスの価値と重要性
データレイクハウスは、これまでのアーキテクチャでは対応できなかったデータの多様性やボリュームに対応し、より高度な分析や機械学習を実現するための基盤です。ただし、その有効活用には、アーキテクチャの理解と計画的な導入が不可欠です。適切なインフラ整備がなされていないデータレイクは、コスト増大の原因となるだけでなく、企業のデータ活用戦略を妨げる要因にもなり得ます。
ここでは、データ管理の課題を技術的観点から明確にし、データレイクハウスの利点と導入の重要性を強調しました。データコンサルタントとして、ビジネス価値を最大化するために必要なインフラと戦略について言及しています。
データコンサルタント視点での「データ整合性とデータレイクの役割」
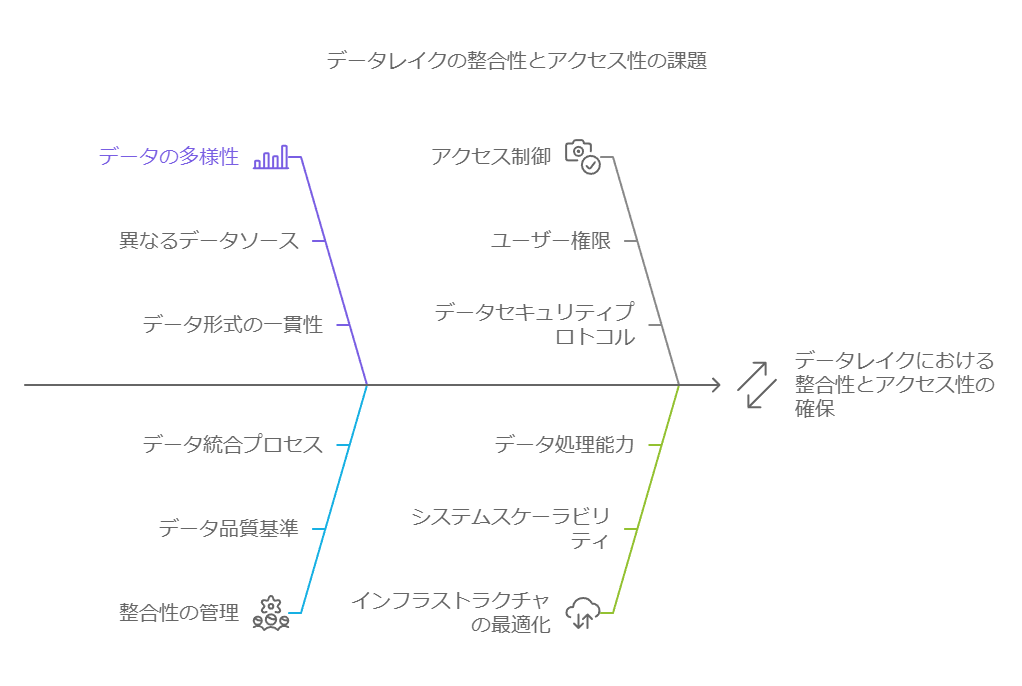
データの整合性とアクセス性の課題
初期の頃、適切なデータを見つけるという課題はあまり重要視されていませんでした。しかし、ビジネスが成長し、意思決定に基づく迅速な対応が求められるようになると、適切なデータを特定し活用することの複雑さが浮き彫りとなりました。アプリケーションの構築だけでなく、データを効率的に管理し、アクセス可能にするための新たなアーキテクチャが必要になったのです。
しかし、技術やツールの増加は、データの整合性に悪影響を及ぼすこともあります。データソースが増え、システム間の整合性が取れなくなることで、組織内で矛盾したデータが生成されるケースが頻繁に見られるようになりました。これにより、データの一貫性が保てず、意思決定の質に影響を及ぼすリスクが高まりました。
データレイクの役割
こうした背景から、効率的なデータ活用を支えるインフラとして、データレイクが登場しました。データレイクの概念は、あらかじめ必要になりそうなデータを蓄積しておき、いつでも迅速に活用できる基盤を提供するという考え方です。市場のスピードに追いつくためには、必要なデータをその都度収集するのではなく、データを蓄積し準備する体制が不可欠です。このため、多くの企業がデータレイクの構築に取り組み始めています。
データレイクの問題点と解決策
しかし、データを単に蓄積するだけでは十分ではありません。データの所在が不明確なままでは、必要なときにデータを効果的に活用することは難しく、いわゆる「データスワンプ」と化してしまいます。この課題に対し、データレイクソリューションは「データをためる」だけでなく、「データをつなぐ」仕組みを提供しています。これにより、多様なデータが常に利用可能な状態で維持され、組織全体でデータの一貫した活用が可能となります。
データを最適に保管するアプローチ
アプローチの特徴は、データを利用するワークロードに最適な場所に保管するという考え方です。つまり、データの保存場所を慎重に選び、それぞれの用途に最適化することで、パフォーマンスと効率を最大化します。これを実現するために、以下のような幅広いデータベースソリューションが検討出来ます。
RDBMS(関係データベース)
データウェアハウス
NoSQLデータベース
Hadoopソリューション
さらに、これらの異なるデータベースソリューションに対して、共通のSQLアクセスレイヤーを提供している点が強みです。これにより、エンドユーザーやアプリケーションは、データベースの種類に関係なく、アプリケーションを変更せずにデータにアクセスすることが可能です。この共通レイヤーは、Oracleなど他社製データベースにも対応しており、柔軟なデータ管理をサポートします。
データレイクを活用するメリット
データレイクソリューションにより、データの蓄積だけでなく、異なるシステム間のデータを統合・接続し、必要なデータに即座にアクセスできる環境が整備されます。これにより、企業はリアルタイムな意思決定をサポートし、市場の変化に迅速に対応できるようになります。
ここでは、データコンサルタントとして、データの整合性やアクセス性に関する課題を強調し、データレイクの有用性とデータレイクソリューションがもたらす具体的なメリットを説明しています。また、ビジネス価値を最大化するためのアーキテクチャ戦略の重要性も強調しています。
データコンサルタント視点での「データ・ガバナンスとデータサイエンスソリューション」
データ・ガバナンスの全体像と提供価値
データの有効活用には、単に蓄積やアクセスの確保だけでなく、適切なデータ・ガバナンスが不可欠です。データの取得からカタログ化、データの準備、クレンジング、そしてセキュリティ保護に至るまで、幅広い機能を提供しています。これにより、企業は信頼性の高いデータ基盤を構築し、規制対応や内部統制における要求を満たすことが可能となります。データ・ガバナンス製品は、各種調査機関のレポートでも高評価を受けており、その効果と信頼性が実証されています。
データリネージュの重要性
データの信頼性を保つためには、その来歴(データリネージュ)を把握することが非常に重要です。データレイクのソリューションは、データが「いつ・どこから来たのか」や「途中でどのような変更が加えられたか」を明確に追跡できる機能を提供します。これにより、データの透明性が向上し、監査対応やコンプライアンスの強化が可能となります。また、データの一貫性と信頼性を維持することで、ビジネス部門とIT部門の両方が必要なデータを迅速に見つけ、安心して活用できる環境が整います。
さらに、データのカタログ化機能により、データを体系的に整理し、ビジネス用語集を作成することが可能です。これにより、事業部門のユーザーやIT部門の開発者が必要とする信頼できるデータを簡単に見つけ出し、迅速に利用できるようになります。
データ活用における強み
データの「蓄積」と「接続」に加え、「分析/活用」においても強力な製品群を提供しています。データサイエンス製品群は、業界でも確固たる地位を築いており、3つの主要な分析タイプを包括的にカバーしています。
記述的分析 (Descriptive Analytics):過去に何が起きたのかを把握するための分析。
予測的分析 (Predictive Analytics):将来に何が起こる可能性があるかを予測するための分析。
処方的分析 (Prescriptive Analytics):望ましい結果を得るためにどのようなアクションを取るべきかを導き出す分析。
特に、処方的分析は高度なスキルを要するため、ここまでをサポートできるITベンダーは限られています。これら3つの分析ニーズを一つのポートフォリオでカバーし、データ活用を最大化するアプローチを提供しています。
ノーコード/ローコードのサポートと連携の柔軟性
データサイエンスや機械学習ソリューションは、オープンソースツールを使用する高度なプログラマーだけでなく、プログラミングの知識がないユーザーも対象としています。GUI(グラフィカルユーザーインターフェース)を使って直感的に操作できるため、幅広いユーザー層にとって使いやすいプラットフォームとなっています。また、データレイクのソリューションは、製品間の連携を強化しており、分析の成果物を共有・再利用できる点も大きな強みです。これにより、データサイエンスのプロジェクト全体の効率化とスケーラビリティが向上します。
オンプレミスとクラウドのシームレスな連携
データレイクの製品群は、オンプレミス環境とクラウド環境の両方でシームレスに動作し、機械学習やAI技術を活用することで、デジタル・トランスフォーメーションをサポートしています。さらに、オープンソース技術を最大限に活用し、柔軟で拡張性の高いデータ分析環境を提供しています。これにより、企業は急速に変化する市場環境に対応し、データを活用した競争優位性を確立することが可能です。
ここでは、データコンサルタントとしてデータガバナンスおよびデータサイエンス製品がもたらすビジネス価値を強調し、データの来歴管理、ガバナンス機能、分析の重要性、ノーコード/ローコード対応など、実務に役立つ具体的な利点を整理しています。
インテリジェントデータレイク設計の重要な検討事項
インテリジェントなデータレイクを構築する際、以下の要点を軸にデータの有効活用とガバナンスの確保を目指します。
1. メタデータおよびデータガバナンス戦略の策定
データレイクのメタデータ管理やデータガバナンス戦略を明確にし、データ資産の分類基準や用語集(グロッサリ)を標準化しましょう。
必要な監査可能性と透明性が確保されているかも確認が重要です。
2. ユースケースに応じたデータ統合パターン
データレイクで対応すべきデータ統合パターンの数と種類を把握しましょう。
これにより、必要なインテグレーション技術とプロセスが明確になります。
3. データの種類と取り込み範囲の明確化
データレイクに取り込むデータタイプ(リレーショナルデータ、マシンデータ、ソーシャルデータ、JSONなど)を定義することは、スキーマ設計や変換ロジックに影響を与えます。
4. データアクセスおよび転送プロセスの設計
各システムからのデータアクセス方法と転送頻度を設計し、関係者への相談窓口や実装におけるプロセスも明確化します。
増分取得と全データセット取得のどちらが最適かを決定することが、パフォーマンスに直結します。
5. セルフサービス対応のデータ準備環境
IT部門のサポートを必要とせず、社内ユーザーがデータレイクからデータを容易に準備できるようにすることが望ましいです。
煩雑な手作業によるデータキュレーションやクレンジングを減らすためのデータ準備ツール導入も検討する必要があります。
6. ストリーミングデータのエンリッチ
ストリーミングデータに履歴やコンテキストを追加するエンリッチメントが必要かどうかを検討します。特にリアルタイム分析を行う場合は効果的です。
7. データ品質と管理プロセスの確立
ビジネスルールやデータスチュワードシップのプロセスを導入し、データ品質の問題を効率的に発見・解消する仕組みが必要です。
これらの要素をバランス良く取り入れ、貴社にとって最適なインテリジェントデータレイクアーキテクチャを描き出しましょう。データレイクの成功には、技術要素とガバナンスの両立が不可欠です。
インテリジェントなデータレイク導入の必要性
企業がインテリジェントなデータレイクを迅速に導入する背景には、既存のデータアーキテクチャを活用しつつ、アナリティクス能力を強化して次世代のデータ分析に対応したいというニーズが存在します。データレイクを利用することで、多様なデータソースから情報を収集し、複数の詳細レベルで分析することで、業務成果を向上させることが可能です。
1. データレイク管理の重要性
データ量の増加
データ量が増加し続けることで、より高度なアナリティクスが可能になる一方で、データ管理の複雑さも増しています。効果的なデータレイク管理により、アナリストは業績のパターンや投資対効果の評価などを行いやすくなり、組織全体の意思決定を支援できます。
データの断片化
多くの企業では、部門単位で個別のデータマートを構築しているため、データが分散化され、横断的なデータ分析が難しくなっています。これにより、組織全体で一貫したビジネス目標に基づくデータ活用が困難になります。
データガバナンスとデータ品質
ビッグデータの活用においては、データの取得元が不明確であるケースも多く、信頼性の低いデータを取り扱うリスクが高まります。データガバナンスの適用により、データ品質を維持しつつリスクを最小限に抑える必要があります。
2. 部門別の課題とデータレイクの役割
業務部門の課題
信頼性の高いデータの提供が困難である
データアクセスが制限され、IT部門への依存度が高い
異なるツールの制約や手作業が多く、効率が低下している
キュレーション済みデータセットの更新・共有の仕組みがない
データレイクは、業務部門がセルフサービスで必要なデータにアクセスし、迅速な意思決定を行える環境を整える手段となります。
IT部門の課題
業務部門のニーズが増大し、データ管理が困難になっている
業務部門でデータがどのように利用されているか把握できない
データという資産の管理能力が低下し、ガバナンスが行き届いていない
インテリジェントデータレイクの導入により、IT部門はデータガバナンスの確立とデータ活用の統制を行い、業務部門のデータ利用に貢献することが可能です。
組織全体のアナリティクス強化に向けたデータレイクの役割
インテリジェントデータレイクの導入は、企業が次世代アナリティクスの可能性を広げ、業務とITの両部門が協働してデータの力を最大限に引き出すための鍵となります。
データレイクの概念とアプローチ
データレイクの基盤は、企業がデータを効率的に活用できるよう整備されたインフラです。データレイクは、必要なデータを即座に活用できるように、様々な形式のデータを一元的に蓄積・管理するための考え方です。データを有効活用するには、データが必要になってから保管を開始するのではなく、データが集まる基盤を事前に整備する必要があります。そのため、データレイク構築に踏み切る企業が増えています。
データレイクアプローチ:「データをためる」「データをつなぐ」
しかし、データを蓄積するだけでは、必要な時にデータがどこにあるか把握できず、十分に活用できないリスクが伴います。データレイクは、「データをためる」だけでなく、「データをつなぐ」仕組みを網羅しており、常に利活用可能な状態でデータを維持できるようサポートします。
データをためる最適化
データは使用するワークロードにとって最適な場所に保管されるべきだと考えています。そのため、クラウド、オンプレミスなど異なる環境間でのデータ配置を最適化する多様なサービスを提供しています。
データレイクとデータレイクハウスの融合
市場が進化するにつれ、データレイクとデータウェアハウスの柔軟な統合が求められています。Databricksが推進するデータレイクハウスのように、データレイクの柔軟性とデータウェアハウスの構造化処理を組み合わせることで、ビジネスインテリジェンス(BI)や機械学習を包括的に活用できる環境が生まれています。これにより、企業はデータウェアハウスとデータレイクの両方を並行して運用する必要がなくなる可能性が示されています。
一方で、従来のデータウェアハウスが不要になるかについては、今後の市場動向によるところが大きいです。
インテリジェントデータレイクの青写真
このリファレンスアーキテクチャは、オンプレミスまたはクラウド上にインテリジェントなデータレイクを構築するためのフレームワークを提供し、企業がデータ管理プラットフォームを通じて適切なユーザーに適切なデータを適時に提供することを目指しています。これにより、得られた洞察を迅速に業務改善に活用できる環境を実現します。
データの探索・ガバナンス・保護の基盤構築
データレイクの基盤には、データ探索、ガバナンス、保護機能を備えることが重要です。また、AIとMLを活用して全社レベルのメタデータレイヤーを最適化し、データカタログによって企業データのインデックス作成、キュレーションを行います。さらに、再現性とスケーラビリティを持つデータガバナンスポリシーを導入し、データのプライバシーと保護に関するリスクを軽減するため、業務レベルと技術レベルのポリシーを適用します。
高パフォーマンスのデータ取り込み機能
データエンジニアは、バッチ、準リアルタイム、リアルタイムデータに対応した拡張性の高いストリーミングおよび大量取り込み機能を使用し、ほぼ全てのデータを任意の速度で取り込むことが可能です。これにより、各種アナリティクス用途に必要なデータを効率的に収集できます。
セルフサービスデータ準備
データアナリストはセルフサービスでデータを準備することにより、データレイク内外のデータ資産の探索、アクセス、コラボレーション、準備、共有を迅速に行い、アナリティクスプロジェクトの推進に活用できます。
スケーラブルなデータ処理エンジンの活用
データエンジニアは、Apache Sparkなどの高性能なデータ処理エンジンとAI搭載ツールを利用し、クラウドまたはオンプレミス環境でデータの解析、変換、クレンジングを効率的に実行できます。これにより、大規模なデータ処理が可能となり、ビジネスインサイトの獲得に役立ちます。
データエンリッチメントとストリーム処理
ストリーム処理やアナリティクストランスフォーメーションは、他の社内データと組み合わせてエンリッチ化できます。これには、データウェアハウスやマスターデータ、機械学習アルゴリズムやワークフローを用いたリアルタイムアラートイベントなどが含まれます。また、ストリーミングデータはバッチ履歴分析のためにデータレイクへ保存することも可能です。
多様なデータ配信モードのサポート
インテリジェントなデータレイクは、リアルタイム、バッチ、イベント主導型、パブリッシュ/サブスクライブといった多様なデータ配信モードをサポートし、ビジネス要件に応じた柔軟なデータアクセスとインサイトの取得を可能にします。
このアーキテクチャは、企業が迅速かつ確実にデータを活用し、競争力を強化するための重要な基盤となります。
データレイクの登場と利点
データレイクは、一時期データウェアハウスの後継として注目を集め、クラウド環境でのオブジェクトストレージに未加工データを保管するための仕組みとして広がりました。データレイクの特徴は、データの前処理やクレンジングを要せず、構造化・非構造化の両方のデータを迅速に保存できる点にあります。ETL処理もアナリストがクエリ実行の際に行うため、データ取り込みがスピーディで、特にAIや機械学習の分野での利用が進んでいます。
従来のBIアプローチとは異なり、データレイクは固定された構造を持たないため、「データの民主化」を促すものとして位置づけられることもあります。
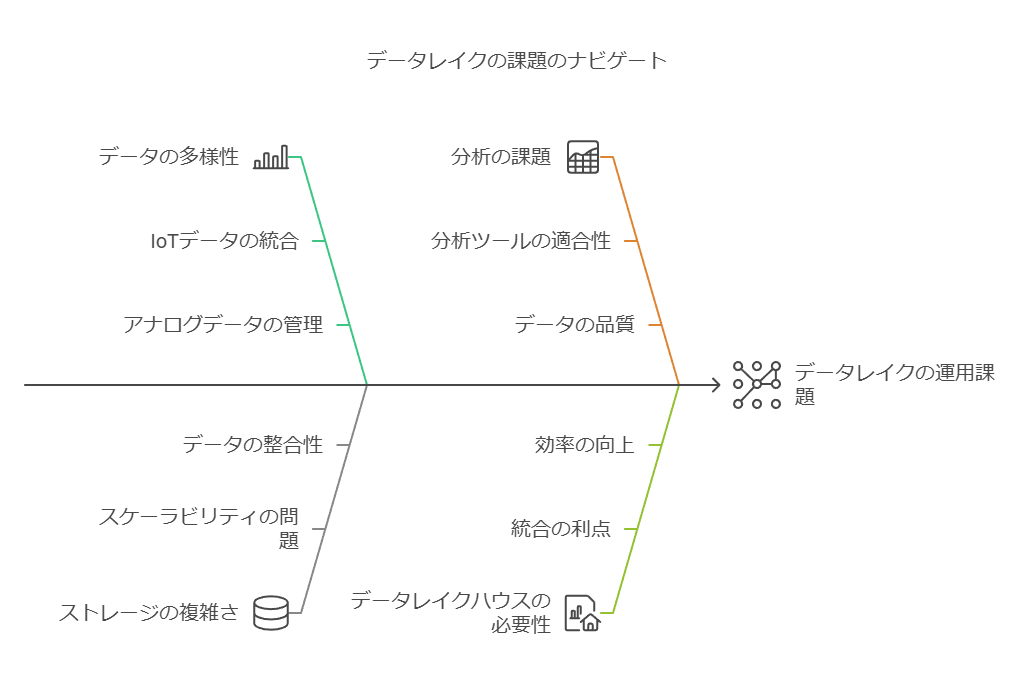
データレイクの課題と対応策
ただし、データレイクにはいくつかの重要な課題が伴います。データウェアハウスが構造に基づいて高いパフォーマンスを発揮できるのに対し、データレイクはデータの構造が定まっていないため、データの管理が散漫になり、不要なデータが蓄積しがちです。dbInsightのトニー・ベア氏も指摘するように、「ルールが存在しないため、過剰なデータが収集され、活用されないままになる」リスクがあります。パフォーマンスを向上させるには、膨大なリソースと時間を費やすことでデータウェアハウスに近い処理速度を実現する必要が生じます。
このような制約から、データレイクの運用には追加のガバナンスやデータの品質管理、ETLパイプラインの最適化といった施策が必要です。
リアルタイム分析の重要性
現代のデータ活用は、かつてのようにバッチレポートを印刷し、CEOに翌朝見せるという形式的なプロセスを超えています。今やリアルタイム分析が求められ、アプリケーションは金融取引からセキュリティ監視まで即応可能な「ブラックボックス」として動作する必要があります。データレイクは、構造に縛られずデータを一元管理するという点で有用ですが、リアルタイム性を高めるには、強固なデータガバナンスと効率的なETL管理を備えたシステムアーキテクチャが重要です。
データコンサルタント視点からの推奨アクション
データのガバナンス強化
データレイク運用には明確なガバナンスルールが欠かせません。データ品質の向上、メタデータ管理、アクセス制御といったガバナンス対策を実装し、データの可視性と信頼性を確保する必要があります。
リアルタイム分析基盤の最適化
リアルタイムでの分析が可能なアーキテクチャを構築し、データ処理パフォーマンスを確保するために、スケーラブルなクラウド環境の活用やストリーム処理技術の採用を検討しましょう。
ETLの最適化とリソース調整
膨大なデータが蓄積するデータレイクの特性に合わせ、ETLプロセスの最適化と動的なリソース割り当ての工夫が必要です。データの整理を定期的に行い、分析に必要なデータを迅速に抽出する仕組みを構築することが効果的です。
これらの対策を通じて、データレイクの運用効率と分析力を強化し、データウェアハウスとデータレイク双方の利点を活かした次世代のデータ基盤を目指すことが求められます。
データレイクハウスの台頭と未来のデータ管理
「データレイクハウスの登場により、従来のデータ管理が抱える分断が統合される」と言われています。従来のデータウェアハウスは、主に過去のデータを分析し、「前四半期の収益はどうだったか?」といった事後分析に優れています。一方、AIを活用する新しいアプローチは、未来を予測し、「どの顧客が離脱する可能性があるのか?」「エンジンはいつ故障するのか?」といったプロアクティブな問いに答えるために使われます。
このような背景から、今後10年以内にデータレイクハウスがデータウェアハウスの役割を吸収し、過去の技術を置き換える可能性が高いと予測されています。従来型のデータウェアハウスは、メインフレームのように一部の企業に残るでしょうが、データレイクハウスが標準的なデータ基盤として進化していくと考えられます。
データウェアハウスの将来と課題
ただし、すべての専門家がデータウェアハウスが役割を終えたと見ているわけではありません。新しいインフラモデルに全面的に移行することにはリスクが伴います。特にPA Consultingのバークレー氏が指摘するように、データ管理や統合の複雑さに対する課題は依然として残っており、データレイクだけではその全てを解決できません。
また、多くの企業は現状、データウェアハウスからの有用な洞察を得ています。DataStaxのジョナサン・エリス氏は、「データウェアハウスとデータレイクは密接に補完し合う関係にある」と述べており、BIダッシュボードの生成はデータウェアハウスで、ライブアプリケーションはNoSQLデータベースのApache Cassandraで実行するといったケースが増えています。
分散型アーキテクチャとデータ管理の課題
エリス氏はまた、「データウェアハウスが依存するSQLはデータベースのサプライヤーごとにパフォーマンスの最適化手法が異なる」と指摘しています。異なるサプライヤー間でのスキーマ設計には複雑な最適化が必要であり、統合には特定の知識が求められるため、データベースアーキテクチャの設計と運用は容易ではありません。
データコンサルタント視点からの推奨アクション
データウェアハウスとレイクハウスの戦略的併用
現在のニーズを満たすために、データウェアハウスとデータレイクハウスを組み合わせた運用が有効です。データウェアハウスを事後分析に、データレイクハウスをリアルタイム予測やAI分析に活用することで、それぞれの強みを活かす運用を推奨します。
データ管理および統合ガバナンスの強化
新しいデータアーキテクチャへの移行には、データの一貫性や品質を維持するためのガバナンスが不可欠です。データ統合のプロセスを最適化し、データの正確性とアクセス制御の標準を策定することで、分散型アーキテクチャの運用リスクを軽減します。
分散型アーキテクチャに対応したスキルの育成
異なるSQLやNoSQL技術の最適化を行うためには、特定の専門知識が求められます。運用エキスパートの育成や、各技術のパフォーマンス最適化に対応した知見を活かすことで、データ統合の一貫性を確保し、より効果的なデータ活用を実現しましょう。
データレイクと分散クエリエンジンの最適化
データレイク、データウェアハウス、データベース全体でのデータ統合・分析には、分散クエリや仮想クエリの実行が不可欠です。Watson Queryは、データの迅速な統合を可能にするデータ仮想化機能を提供し、小規模なアドホッククエリへの対応力を強化することで、従来のETLジョブを25〜65%削減する効果があります。さらに、Watson Knowledge Catalogを活用してデータガバナンスやポリシー管理も一元化され、セキュリティと効率性の向上が図れます。インテリジェントなデータ管理とセルフサービスの効率化
データカタログツールのWatson Knowledge Catalogは、クラウドベースのメタデータリポジトリとして、AI・機械学習・ディープラーニングを活用したインテリジェントなデータディスカバリーを提供します。これにより、データ品質やガバナンスのプロセスが大幅に自動化され、対応時間が最大90%削減されます。どこからでもデータや知識資産へのアクセスが可能になり、データのキュレーション、分類、共有もシームレスに実施可能です。
高パフォーマンスなデータ複製で迅速かつ連続的なデータ可用性を実現
データ複製ソリューションは、オンプレミスからクラウドまで対応可能で、複数サイトでのワークロード分散やデータの連続可用性を低レイテンシーで提供します。この仕組みは、データレイクやデータウェアハウスに保存された情報をスムーズに活用し、重要な業務データへのアクセスを安定供給。ソースとターゲット間の堅牢なサポートによって、リソースの効率的な活用と高ROIを実現します。
まとめ
データ仮想化と分散クエリエンジンによる統合分析、セルフサービスデータ管理、そして迅速なデータ複製の導入により、複雑なデータ環境でも高効率で高価値なデータ管理が可能になります。これにより、コスト効率やビジネスのアジリティも向上し、持続的な成長を支える基盤が構築されます。