目次
- 1 オンプレミスかクラウドか?データレイク構築のすすめ
- 2 データレイクの構造とアクセス方法
- 3 オブジェクトストレージの特性とデータレイクの役割
- 4 データレイクのデータストアとアクセス方式
- 5 オブジェクトストレージの性能とデータレイクでの適用
- 6 データレイク構築の可能性
- 7 データレイク構築における技術要件の定義
- 8 経営部門におけるデータ管理の課題と解決策
- 9 クラウドプロバイダーとデータレイクの活用戦略
- 10 データレイクの面密度イノベーションの戦略的役割
- 11 インテリジェントなデータレイクの青写真: データ主導のビジネス変革を支える基盤
- 12 インテリジェントなデータレイクの導入を促す理由
- 13 インテリジェントデータレイク設計における重要な検討事項
- 14 データレイクハウス戦略の概要
- 15 データレイクのアジリティにおける役割
- 16 データ保存の戦略と課題:構造化データからデータレイクへ
オンプレミスかクラウドか?データレイク構築のすすめ
データレイクの構築は、企業がデジタルトランスフォーメーション(DX)を実現するための重要なステップです。データレイクがもたらすメリットや最適なストレージの選定、そしてオンプレミスとクラウドのどちらで運用するべきかを理解することは、今後のビジネス戦略にとって欠かせません。本稿では、データレイクの基本知識と主要ベンダーの製品・サービスを紹介します。
データレイクの概要
データレイクは、企業が大量のデータを効率的に管理・分析するための基盤です。特に、DXを進める上で大量データの処理は前提条件となります。データレイクは、組織がデータから最大限の価値を引き出すためのコア要素であり、ストレージソリューションに依存しています。クラウドへの移行が進む中でも、オンプレミス環境での運用も選択肢として考慮する必要があります。
データレイクに必要なストレージ
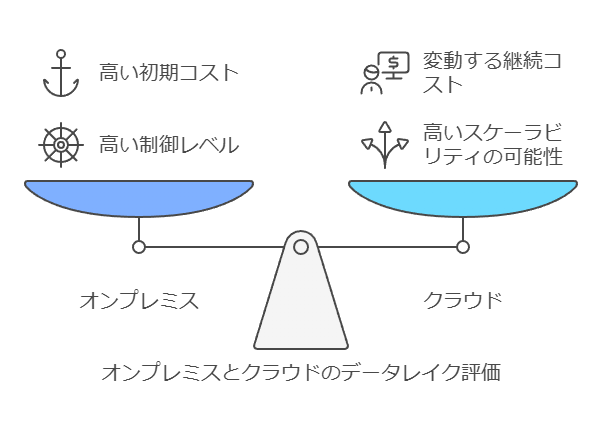
データレイクにおいては、主にオブジェクトストレージが利用されます。オブジェクトストレージは、大量のデータを柔軟かつスケーラブルに保存できるため、データレイクの特性に適しています。以下に、オンプレミスとクラウドそれぞれの長所と短所を見ていきます。
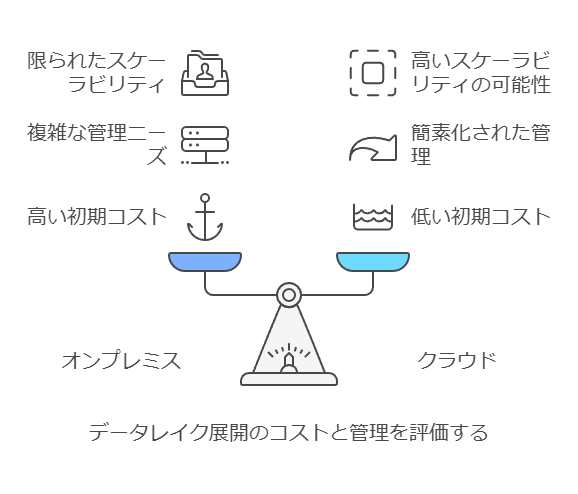
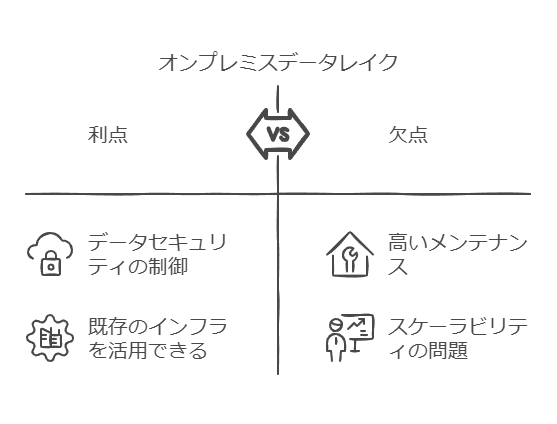
オンプレミスのメリット
データセキュリティの制御が容易。
既存のインフラを活用できる。
オンプレミスのデメリット
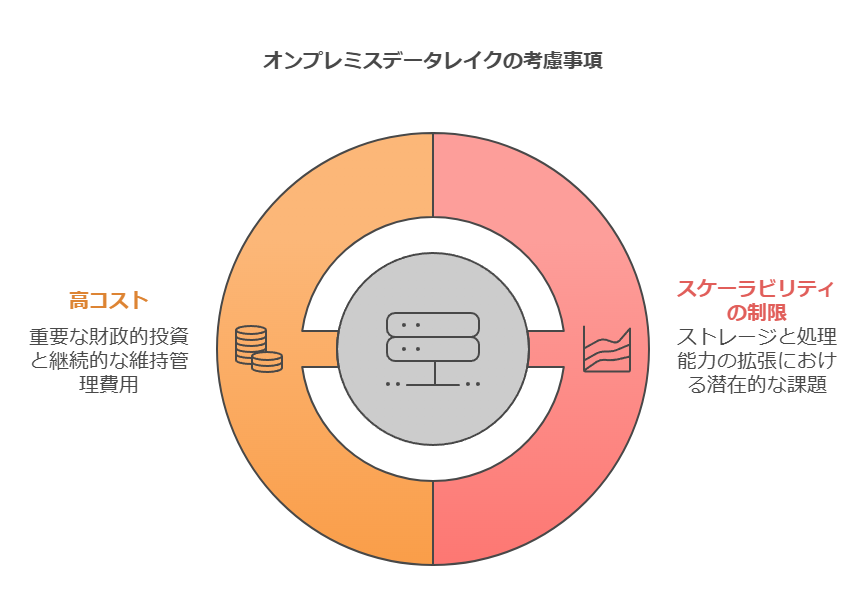
スケーラビリティが制限される可能性。
初期投資と維持管理コストが高くなる場合がある。
クラウドのメリット
柔軟なスケーラビリティ。
初期コストが低く、必要に応じたリソース追加が可能。
クラウドのデメリット
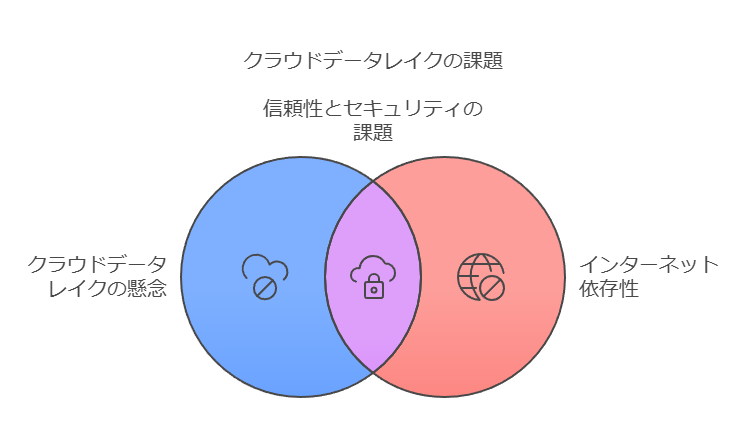
データセキュリティやプライバシーに対する懸念。
依存するインターネット接続の信頼性が必要。
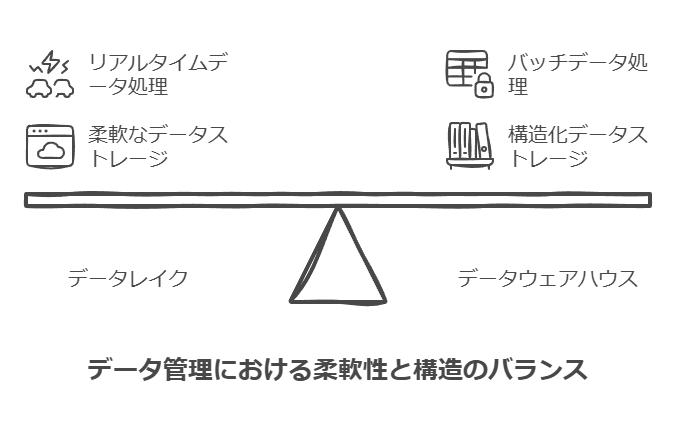
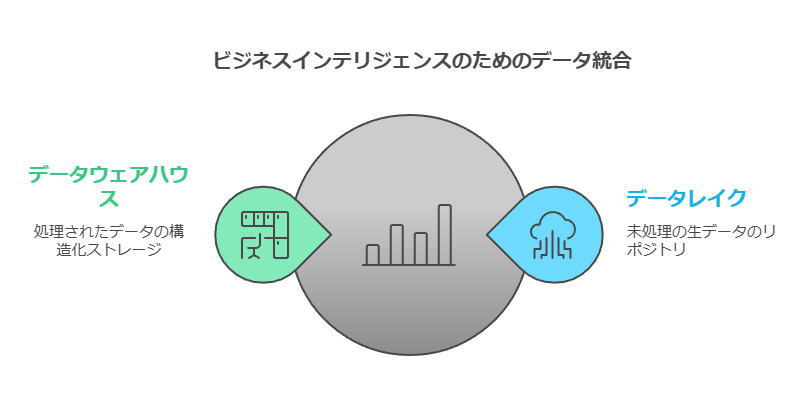
データレイクとデータウェアハウスの違い
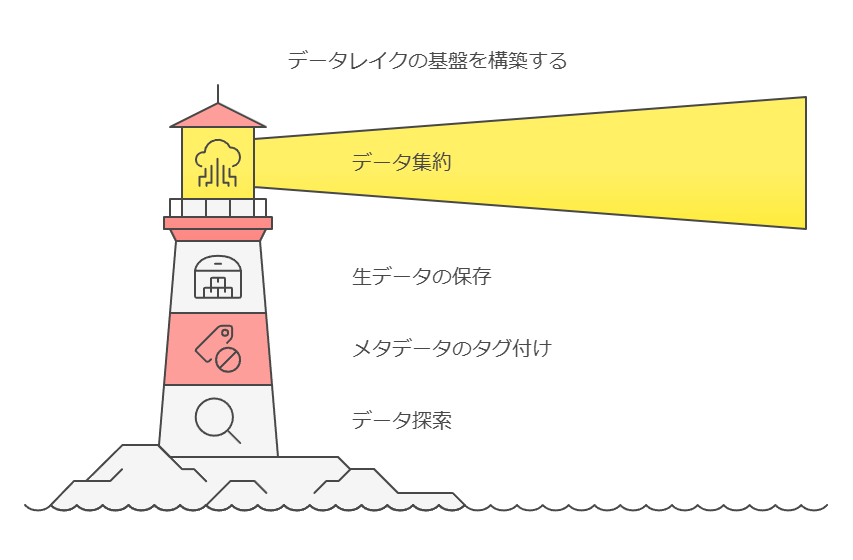
データレイクは、企業のデータが最初に集約される場所であり、あらゆるデータソースから情報が流入します。この段階では、データは主に未加工の状態で保管され、必要に応じてメタデータでタグ付けされることもあります。これはデータサイエンティストや専門家が効率よくデータを探索し、分析を行うための基盤を提供します。
一方で、データウェアハウスは、データレイクから流れ出るデータをさらに処理し、分析用にパッケージ化した状態で保存します。データウェアハウスは、整然としたデータを必要とするビジネスインテリジェンス(BI)や報告のために設計されているため、データレイクとは役割が異なります。
まとめ
データレイクの構築は、企業がデータを戦略的に活用するための基盤を築くための重要なステップです。オンプレミスかクラウドかの選択は、企業のニーズやデータセキュリティの要件に応じて慎重に行う必要があります。また、データレイクとデータウェアハウスの違いを理解することで、データ管理戦略をより効果的に進めることが可能となります。


データレイクの構造とアクセス方法
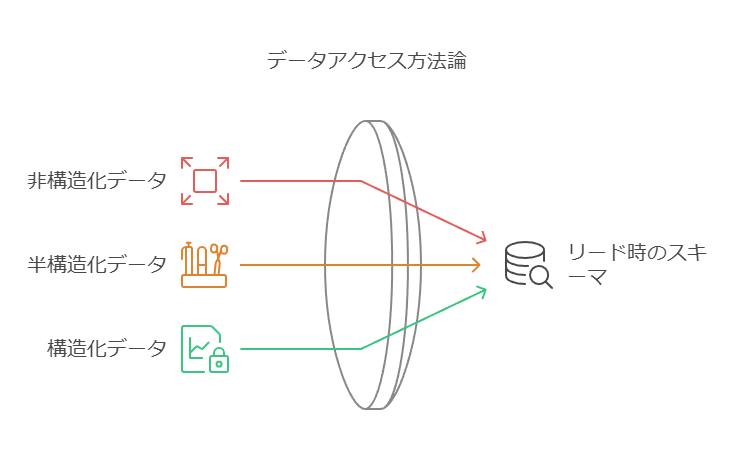
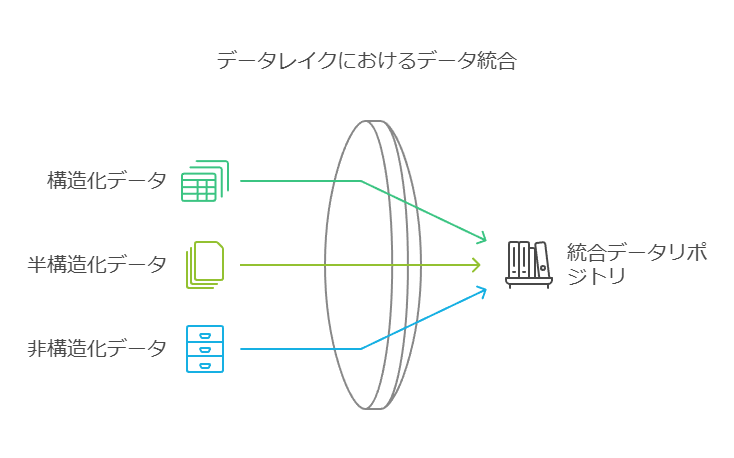
データレイクは、多様なデータストアを含む、企業におけるデータの中心的なリポジトリです。このリポジトリには、ほとんどの従業員が直接アクセスすることが難しい形式(非構造化、半構造化、構造化)のデータが蓄積されています。一方、データウェアハウスは、従業員やアプリケーションが容易にアクセスできるように、構造化データとして整理されたデータベースです。さらに、データマートやデータハブは、特定の部門向けにデータを加工し、利用しやすくする役割を果たします。
このように、データレイクは大量のデータをそのままの形式で保持し、データウェアハウスやデータマートへのクエリとは異なり、データレイクへのアクセスには「スキーマ・オン・リード(Schema on Read)」のアプローチが必要です。
データレイク内のデータ型とそのアクセス方式
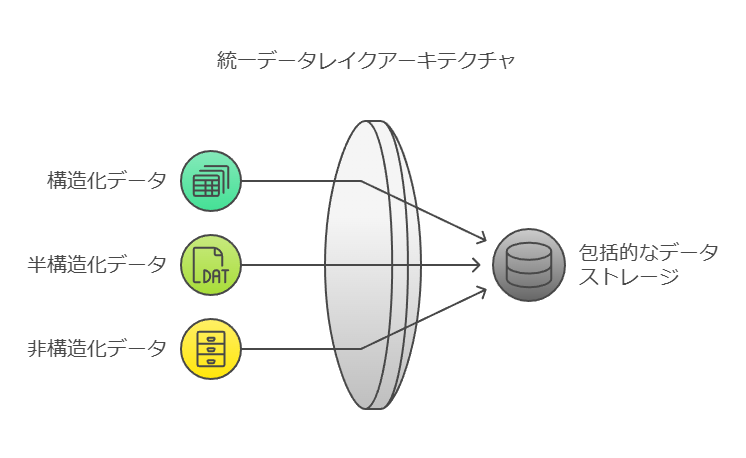
データレイク内には、組織全体のさまざまなデータソースが統合されています。具体的には、以下のようなデータが含まれます:
構造化データ: リレーショナルデータベースに格納されたデータ。
半構造化データ: CSVファイルやログファイル、XML形式、JSON形式など。
非構造化データ: メール、ドキュメント(PDFなど)、画像、音声、動画などのバイナリデータ。
ストレージプロトコルに関しては、ファイル、ブロック、オブジェクトといった異なるストレージ形式を収容する必要がありますが、データレイクでは一般的にオブジェクトストレージが選択されます。この際、注意すべきはアクセスされるのはデータそのものではなく、データを説明する「メタデータヘッダ」であるという点です。このメタデータヘッダは、データベースのエントリーや画像など、さまざまなデータに関連付けることができます。
オブジェクトストレージの利点
オブジェクトストレージは、大量の非構造化データを格納するのに非常に適しています。データベースのようにクエリを実行することはできませんが、さまざまな種類のオブジェクトをフラットな構造で格納し、そこに何が存在するかを容易に調べることが可能です。この特性は、特にデータが多様であるデータレイクにおいて、その価値を最大限に引き出すために重要です。
まとめ
データレイクは、企業がデータを戦略的に管理・活用するための重要な資産です。さまざまなデータ型をそのまま保持できる柔軟性を持ちながら、データへのアクセス方法やストレージの選択肢について理解を深めることで、効果的なデータ活用が実現できます。データの構造や形式に応じた最適なアプローチを選択することで、ビジネスインサイトの獲得や意思決定の質を向上させることができます。
オブジェクトストレージの特性とデータレイクの役割
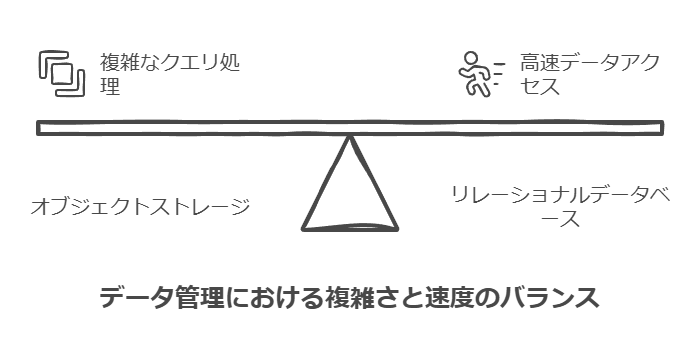
オブジェクトストレージは、通常、高速なデータアクセスを目的とした設計ではありません。そのため、オブジェクトストレージは、データウェアハウスのリレーショナルデータベースに比べて、クエリの構築や処理が複雑なデータレイクのユースケースに適しています。データレイクにおけるクエリ処理の多くは、最終的により扱いやすいデータストアを構築し、そこからデータウェアハウス用のデータを準備することに繋がります。
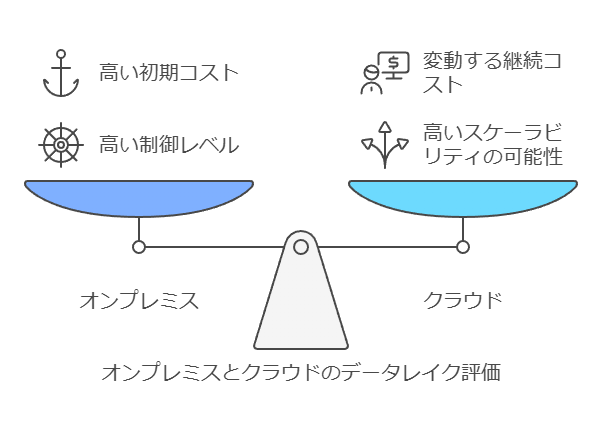
オンプレミスとクラウドのデータレイク
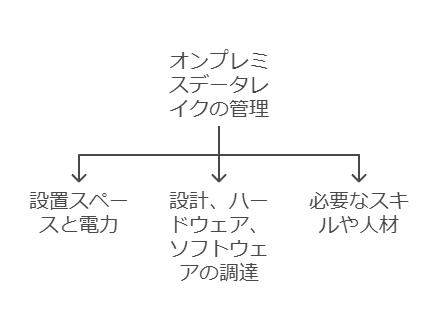
オンプレミスとクラウドの選択に関する議論は、データレイクの運用においても同様に重要です。オンプレミスのデータレイクでは、以下の要素に対するコストとリソースの管理が求められます:
設置スペースと電力
設計およびハードウェア、ソフトウェアの調達
運用に必要なスキルや人材
クラウドへのデータレイクの移行は、設備投資(CAPEX)を運用支出(OPEX)にオフロードするメリットがあります。しかし、データの増加やオンプレミスとクラウド間のデータ移動には料金が発生するため、予期しないコストが発生する可能性もあります。
また、ストレージやデータレイクのアーキテクチャだけでなく、コンプライアンスや接続性に関しても十分な検討が必要です。クラウドとオンプレミスの両方で運用し、必要に応じてクラウドにスケールアウトする柔軟性も考慮すべき要素です。
データレイクの選択肢:オンプレミス vs クラウド
オンプレミスのデータレイク製品と主要なクラウドプロバイダーのデータレイクサービスを紹介し、それぞれの特徴や利点を比較します。
オンプレミスのデータレイク製品
データレイクは大規模なストレージ容量を必要とすることが多く、大企業においては特に重要です。この10年間で、多くのストレージベンダーはデータレイク製品を市場に投入してきました。
このように、データレイクの構築と運用には、データの性質や企業のニーズに応じた柔軟なアプローチが求められます。データ管理の戦略を再評価し、最適な選択肢を見つけることで、ビジネスにおけるデータの価値を最大限に引き出すことが可能になります。
データレイクのデータストアとアクセス方式
データレイクには、構造化、半構造化、非構造化の様々なデータストアが含まれます。これらのデータは、通常の従業員にとって簡単にアクセスしたり、直接利用することは難しい形式で保存されています。一方、データウェアハウスは、アプリケーションや従業員が直接アクセスできる構造化データベースとして整備されています。さらに、データマートやデータハブを使用することで、部門ごとに利用しやすいデータに加工されることもあります。
データレイクの最大の特徴は、膨大なデータをそのままの形式で保存できることです。データウェアハウスやデータマートでは、事前にスキーマが定義された構造化データへのクエリが一般的ですが、データレイクに対しては「スキーマ オンリード(Schema on Read)」というアプローチが必要です。これは、データの読み込み時にスキーマを定義することで、柔軟に未加工データを扱える仕組みです。
データの種類とデータレイクでの格納方式
データレイクには、組織全体、あるいは部門ごとのあらゆる種類のデータが蓄積されます。例えば、リレーショナルデータベースの構造化データや、CSVファイル、ログファイル、XMLやJSON形式の半構造化データ、さらには、メール、PDF、画像、音声、動画のような非構造化データも含まれます。このように、データの多様性が高いため、ストレージには多くの種類が存在します。
ストレージプロトコルには、ファイルストレージ、ブロックストレージ、オブジェクトストレージの選択肢がありますが、データレイクでは主にオブジェクトストレージが選ばれます。オブジェクトストレージは、大規模な非構造化データを効率的に管理できるため、大量の異種データを格納するのに適しています。さらに、オブジェクトごとにメタデータヘッダが添付されており、データ自体ではなくメタデータを基にデータを管理するのが特徴です。
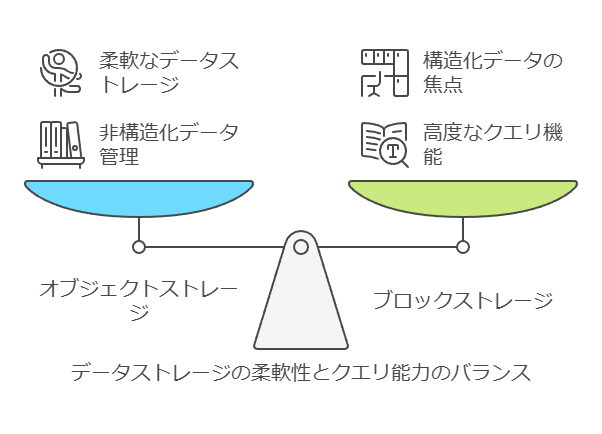
オブジェクトストレージの利点と制約
オブジェクトストレージは、膨大な量のデータを一元的に管理し、ファイルやブロックストレージに比べて非構造化データの格納に適しています。ただし、ブロックストレージのように高度なクエリ機能は備わっていないため、データ自体への詳細な操作や分析は他のシステムで行われることが多いです。オブジェクトストレージでは、データがフラットに格納され、クエリの実行は基本的にファイルシステム上で行われます。これにより、構造化データが主流の従来型システムとは異なる柔軟性が提供されます。
データレイクの設計には、こうしたストレージ技術の特性を考慮し、データ管理や運用における課題とニーズをバランスよく取り入れることが求められます。
このように、データレイクとデータウェアハウスは、それぞれ異なる役割とアーキテクチャを持ちますが、組織のデータ活用戦略において相互補完的な役割を果たします。データコンサルタントとしては、どの技術が組織のニーズに最も適しているかを慎重に評価することが重要です。
オブジェクトストレージの性能とデータレイクでの適用
オブジェクトストレージは、リレーショナルデータベースのような高速なクエリ処理を目的とした設計ではありません。そのため、オブジェクトストレージは、大量の非構造化データや複雑なデータ構造を管理するデータレイクのユースケースに適しています。データレイク内でのクエリはスキーマが事前に定義されていないため、クエリ処理が複雑になる傾向があります。結果として、データをより効率的にクエリ可能にするため、データレイクの下流にデータウェアハウスを設け、必要に応じてデータを構造化しクエリに最適化するアプローチが取られることが多いです。
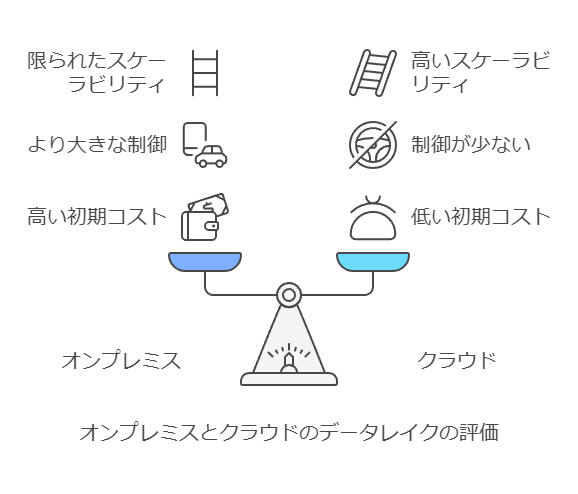
オンプレミス vs クラウド — データレイク運用の選択肢
オンプレミスとクラウドの比較は、データレイク運用の場面でも重要な議論となります。オンプレミスでのデータレイク構築は、設置スペースの確保、電力供給、ハードウェア・ソフトウェアの選定と調達、さらに運用に必要なスキルを持つチームの維持など、複数の領域に対応するコストが発生します。これに対して、クラウド環境を利用することで、これらの設備投資(CAPEX)を運用費用(OPEX)に置き換えることが可能です。クラウドサービスの利点は、必要なリソースを動的にスケールさせる柔軟性がある点です。
しかし、データの急激な増加やオンプレミスとクラウド間でのデータ転送が頻繁に発生する場合、クラウド利用コストが予想以上に高騰する可能性があります。これを避けるためにも、適切なコスト管理が必要です。また、データレイクのアーキテクチャだけでなく、データのセキュリティやコンプライアンス、ネットワーク接続性の問題も考慮しなければなりません。
ハイブリッド運用の可能性
クラウドとオンプレミスのハイブリッド運用も、データレイクにとって有効な選択肢の一つです。基本的にはオンプレミスでデータレイクを運用し、負荷が増大したときにクラウドにバーストさせるアプローチです。これにより、初期投資を抑えつつ、必要に応じて柔軟なリソースの拡張が可能になります。このハイブリッド戦略は、コストのバランスとパフォーマンスの最適化を同時に実現できるため、特に中規模から大規模な組織にとって効果的です。
データレイク運用 — オンプレかクラウドか?
最後に、データレイクの運用環境を選定する際には、組織の規模やニーズに応じてオンプレミス製品とクラウドサービスの両方を検討することが重要です。例えば、大企業においては膨大なストレージ容量が必要になることが多いため、オンプレミスのデータレイク製品が好まれることがあります。ストレージベンダー各社は、この需要に応じた製品を提供しています。
このように、データレイク運用の選択肢は、コスト、スケーラビリティ、運用負荷などの要素を慎重に評価し、最適なソリューションを見つけることが成功の鍵となります。データコンサルタントとして、これらの選択肢を組織の戦略に合わせて提案することで、長期的な価値創出を支援できます。
データレイク構築の可能性
一部のデータレイク方式は、従量課金制の製品ポートフォリオであり、直接的にデータレイク専用のソリューションを提供しているわけではありませんが、プラットフォームを活用してデータレイクを構築することは十分に可能です。柔軟なスケーラビリティと従量課金モデルは、組織が必要に応じてリソースを拡張しながら、コスト効率を保ちつつデータレイクを運用する上で有利な選択肢となります。
ハードウェアに依存しないデータレイク構築
データレイクの構築に関しては、特定のハードウェアに依存する必要はなく、様々なベンダーのハードウェア上で実装可能です。市販のホワイトボックスキットも、コストパフォーマンスに優れた選択肢として広く採用されています。過去には、大手ストレージベンダーがデータレイクアプライアンスを提供し、短期間で市場に投入されましたが、こうした製品の導入は大規模なプロジェクトになることが多く、専用のコンサルティングやソリューション提供が不可欠です。特に、データレイクを最適に運用するためには、技術面だけでなく、業務要件に合わせた設計と運用が重要なため、コンサルタントの支援が求められる場面が多くあります。
クラウドプロバイダーのデータレイク戦略
クラウド業界において、特にAmazon Web Services (AWS)、Microsoft Azure、Google Cloudの大手3社は、既に定義済みのデータレイクサービスを提供しています。これにより、企業はハードウェアに依存することなく、柔軟かつ迅速にデータレイクを構築・運用できる環境を整えています。
例えば、AWSのデータレイクサービスは、Amazon S3をベースに構築され、シンプルなコンソールからデータセットの検索、参照、管理が可能です。特に、データのタグ付け、検索、共有、変換、分析、管理機能が統合されており、企業全体や外部パートナーとデータを安全にやり取りする環境を提供しています。AWSのサービス群には、サーバーレスコンピューティングのAWS Lambda、Elasticsearchを使った検索機能、ユーザー認証のAmazon Cognito、ETLツールのAWS Glue、データクエリを行うAmazon Athenaなどが統合されており、これらのサービスを組み合わせることで強力なデータレイク環境を構築できます。
一方、Microsoft Azureのデータレイクサービスも同様に高度な機能を提供しており、特にペタバイト規模のデータに対して大規模な並列処理を行うことが可能です。Azureでは独自のU-SQLを用いたクエリ処理に加え、R、Python、.NETといった複数のプログラミング言語をサポートし、柔軟でスケーラブルなデータ処理環境を提供しています。
結論
データレイクの構築においては、ハードウェアに依存しない柔軟なアプローチが可能であり、クラウドプロバイダーの成熟したサービスを活用することで、初期導入のハードルを大幅に下げることができます。オンプレミス環境とクラウドのどちらを選択するかは、組織の規模、コスト、データセキュリティ、パフォーマンス要件に依存しますが、いずれの選択肢でもデータレイクの実装は重要なDX(デジタルトランスフォーメーション)の要素となるでしょう。
データコンサルタントとしては、企業の要件や既存の技術基盤に応じて、最適なデータレイクソリューションを提案し、コストや運用負荷を最小化しつつ、ビジネス価値を最大化することが目標となります。
データレイク構築における技術要件の定義
データレイクを成功させるためには、システム全体で必要となる技術要件を明確に定義することが不可欠です。技術要件とは、ビジネスの機能要件を具体的にシステムに落とし込み、どのようにして実現するかを記述したものです。以下は、その技術要件の例です:
単一データモデルまたはリンクデータモデルを使用し、データの一貫性と再利用性を確保する。
マッチング/サバイバルルールを活用し、データの重複排除と正確なデータ統合を実現する。
データスチュワード用のユーザーインターフェースの応答時間を5秒未満に抑え、スムーズな操作性を提供。
スケーラビリティに対応したMDM(マスターデータ管理)を構築し、将来的なデータ量やワークロードの増加に備える。
顧客の希望する連絡方法が変更された際には、リアルタイムでCRMに通知が送られるような仕組みを実装。
これらの要件を定義することで、データレイクがビジネス目標を達成し、スケーラブルで効率的なデータ基盤を提供できるようになります。
論理データモデルの構築
データレイク構築の初期段階では、論理データモデルの作成が重要なステップとなります。論理データモデルとは、データの構造やその関係を視覚的に表現したもので、実際の物理的なデータ保存方法に依存しません。このモデルは、データアーキテクチャを理解しやすくし、エンティティ間の関係性を明確にします。以下の要素を含める必要があります:
エンティティ:データレイク内の主要なデータ項目を表現。
エンティティの属性:それぞれのエンティティに付随する詳細なデータフィールド。
キーグループ:プライマリキーや外部キーなど、データの一貫性を確保するための識別子。
正規化:データの冗長性を最小化し、効率的なデータ管理を行うための設計手法。
論理データモデルを作成することで、物理的な実装方法にかかわらず、データの流れや構造を理解しやすくなります。また、データの実装をスムーズに進めるための基盤が形成されます。
プロジェクト計画の初期概要
データレイクプロジェクトを円滑に進めるためには、プロジェクト計画の初期概要を詳細に策定する必要があります。この計画には、以下の要素を含めることが重要です:
目標:プロジェクトの最終目標は何か?具体的な成功基準はどう設定するか?
リソース:人的リソースや技術的リソースを含め、最終製品の開発に必要なすべてのリソースを特定する。
範囲:各フェーズでの目標達成に必要なデータソースやドメイン、レコード数などを定義する。
プロセス:計画の実行手順を詳細に定義し、担当者、方法、時期、場所などを明確にする。
制約と依存関係:プロジェクト進行に影響を与える可能性のある制約要因を洗い出し、それらを回避する方法を検討する。
納期:各フェーズごとの納期を明記し、変更の余地があるかどうかも含めて記録する。
成果物:プロジェクトの各段階で得られる成果物を定義し、関係者が確認・承認できるようにする。
これらの要素を詳細に設定することで、プロジェクト全体の進行をスムーズにし、リスクを最小限に抑えながら、データレイクの導入を成功させることができます。
コンサルタントとしての視点
データレイクプロジェクトの成功には、技術面だけでなく、ビジネス目標やプロジェクト計画との整合性を取ることが不可欠です。データコンサルタントとしては、クライアントのニーズを正確に把握し、必要な技術要件やプロジェクトの計画策定を支援しつつ、プロジェクト全体のガバナンスと品質管理を維持することが求められます。
経営部門におけるデータ管理の課題と解決策
経営部門はデータの単なる蓄積(疑似データレイク化)を避け、データを活用するための戦略的な取り組みを進める必要があります。
多くの企業では、大量のデータが収集されているにもかかわらず、それを整理・活用せずに大規模なリポジトリにただ保管しているだけです。この状態では、データの価値を引き出すことは非常に難しいです。単にデータを蓄積するだけでは、そのデータの意味を理解することはできませんし、経営に有効なインサイトを得ることもできません。
データ戦略の第一歩:データの目的と価値を明確にする
経営部門がまず着手すべきは、収集するデータの目的と、それによって得ようとするインサイトを明確に定義することです。このステップを踏まずにデータを蓄積するのは、いわゆる「キッチンシンク・アプローチ」(あらゆるデータを無差別に集める手法)に陥りがちであり、これでは有効な分析や意思決定には繋がりません。
例えば、製造業を例に考えると、多くの企業がマシンラーニングやAI、IoTデバイス、センサーなどを導入して膨大なデータを収集しています。しかし、データの収集が目的化してしまい、そのデータから何を得たいのか、どう経営に活かすのかが明確でない場合、こうした技術投資も十分に成果を上げられません。
効果的なデータ管理のための具体的ステップ
ビジネス目標の明確化
まず、経営陣は何を達成したいのかをはっきりと定義する必要があります。これがない限り、データは膨大に蓄積されても、その中から得られる価値は不明確なままです。
データ選定の優先順位設定
すべてのデータを等しく重要視するのではなく、ビジネス目標を達成するために必要なデータを優先的に収集することが求められます。これには、収集するデータの種類、質、量を考慮する必要があります。
データ管理プロセスの標準化と統合
異なるプラットフォームやツールでデータを管理することが多いですが、こうした分散環境ではデータの統合やクリーン化が欠かせません。ツールやプラットフォームの重複を排除し、データガバナンスをしっかりと定めることで、データが一貫性を保ち、信頼できる状態で管理されます。
データの相関性とクリーンさの確保
データが複雑であるほど、その中から適切な相関性を見つけ出すのは難しくなります。そのため、データの重複やエラーを早期に排除し、正確なデータセットを維持することが必要です。
IoTデバイスの適切な管理とデータの価値化
製造業のケースを例に取ると、現場には数万台ものIoTデバイスが導入され、膨大なデータが生成されますが、データを活用して工場の処理スループットを高めるといった根本的な目標を達成するためには、データの有効な活用が必要です。これには、以下の点に注力することが重要です:
デバイス間のデータ統合:異なるプラットフォームやデバイスから得られたデータを統一的に管理・分析できるようにする。
リアルタイム分析の導入:センサーやIoTデバイスからのデータをリアルタイムで分析し、製造プロセスの効率化に直結する意思決定を迅速に行えるようにする。
予測分析の活用:過去のデータを基に、今後の生産能力や機器のメンテナンス時期を予測し、トラブルを未然に防ぐ施策を講じる。
コンサルタントとしての視点
データコンサルタントとして、企業がデータを単に収集するのではなく、ビジネス目標に即した形で活用できるようにするためには、データ戦略の明確化とデータ管理の標準化が不可欠です。特にIoTやAI、ビッグデータ環境では、データの整合性、クリーンさ、リアルタイム性が成功のカギを握ります。

クラウドプロバイダーとデータレイクの活用戦略
Azure HDInsightを活用したデータレイクの次のステップ
Azure HDInsightは、オープンソースのマネージド分析サービスとして、Hadoop、Spark、Apache Hive、Hive LLAP(Low Latency Analytical Processing)、Apache Kafka、Apache Storm、Rといったフレームワークをサポートしています。これにより、Azure上のデータレイクはビッグデータ分析やリアルタイム処理に対応できる柔軟なアーキテクチャを構築できます。
GCPのデータレイクアプローチ:一体感とコンサルティングの必要性
Google Cloud Platform (GCP)のデータレイク展開は、AWSやAzureと比較してやや一体感が少ないと感じられるかもしれません。これは、他のクラウドプロバイダーに比べ、GCPのデータレイクはサービスとしての統合度が低いためです。ただし、GCP上にデータレイクを構築することは十分可能であり、Twitterのデプロイメントがその一例です。
しかし、GCPの場合、データレイクの導入プロジェクトは、コンサルティングに重点を置く必要があると考えられます。これは、既存のクラウドサービスを直接活用するだけではなく、より高度なデザインやカスタマイズを求められる場合が多いためです。特に大規模なデータレイクの実装には、コンサルタントの支援が成功のカギとなります。
クラウドプロバイダーが提供するデータレイクソリューションの利便性
クラウドプロバイダーが提供するデータレイクの明確な定義と構築は、企業にとって非常に有益です。データレイクは、すべてのデータを1つのリポジトリに集約し、そこで選別やアクセスが容易に行えるというコンセプトです。このアプローチは、特にビジネスニーズが複雑で、多様なデータソースを持つ企業にとって非常に適しています。
オブジェクトストレージとデータレイクの適合性
データレイクに最適なストレージの選択においては、データの即時性やリアルタイム性がそれほど重要ではない場合、オブジェクトストレージが理想的な選択肢です。オブジェクトストレージは安価でスケーラブルなため、大量のデータを効率的に蓄積でき、データレイクの根幹を支えるストレージソリューションとして非常に優れています。
オンプレミスストレージベンダーの課題とコンサルティングの必要性
オンプレミスストレージベンダーは、ビッグデータやデータレイクの概念を積極的に取り入れ、場合によってはデータレイクアプライアンスを提案しています。しかし、データレイクの実装は非常に大規模であり、単独の製品で対応することは難しいです。これには複数のテクノロジーやインフラストラクチャの統合が必要となるため、ハードウェアベンダー単独ではなく、コンサルティングサービスやソリューション型のアプローチが不可欠です。
AWSとAzureの優れたデータレイクソリューション
一方、AWSやAzureのような大手クラウドプロバイダーは、比較的容易にデータレイクを構築するためのソリューションを提供しており、その構成要素や運用手法は明確に定義されています。これにより、企業はこれらのプラットフォーム上でデータレイクを構築し、迅速にビジネスの洞察を得ることが可能となっています。
特にAWSは、「Amazon S3」を中心に、Lambda、Glue、Athenaといったデータ分析や処理ツールを統合して、スムーズにデータレイクを展開できます。Azureも同様に、「Azure Data Lake Storage」と「HDInsight」を組み合わせることで、高スケーラビリティと高いパフォーマンスを両立したデータレイクソリューションを提供しています。
コンサルタントとしての提言
データレイクを成功させるには、企業ごとに異なる要件に応じた最適なクラウドプラットフォームの選定が重要です。AWSやAzureは、定義されたサービスが充実しており迅速な導入が可能ですが、GCPはコンサルティングを伴ったカスタマイズが有効です。また、データレイクの運用には、適切なストレージの選定と統合ソリューションの構築が必要不可欠です。
データレイクの面密度イノベーションの戦略的役割
データレイクにおける面密度の革新は、企業が直面する膨大なデータ量に対応するための重要な取り組みです。特に、大手クラウドプロバイダーが生成・蓄積する大量のデータは、効率的なストレージ戦略の要となります。多くの企業が採用している90対10の法則(データの90%をハードディスクドライブ(HDD)、10%をSSDに保存)は、コスト効率とパフォーマンスを最適化する手段として機能しています。
ストレージとコンピューティングのイノベーション:帯域幅の拡大
ストレージネットワーキングとコンピューティング機能を統合することで、データの移動を安定させ、ストレージのイノベーションを進める結果、帯域幅の拡大が達成されました。これは、大規模なデータ分析において極めて重要です。特に、グラフィックスプロセッシングユニット(GPU)を用いた処理では、高帯域でのデータ取り込みが求められます。
AIアプリケーションや大規模データ処理において、帯域幅の拡張と並列処理を可能にするためには、分離と構成が可能なアーキテクチャが採用されています。これにより、効率的なデータ処理と、リアルタイム分析が実現可能となります。
セキュリティイノベーション:デバイスとシステムの安全性向上
もう1つの重要なイノベーション領域は、セキュリティです。オープンエンクレーブ技術を通じて、デバイスのデジタル検証を行うプロトコルをファームウェアと計算機能に実装し、デバイスの起動時に整合性を確保する投資が進められています。これにより、システムレベルとデバイスレベルでセキュリティが強化され、全体的なネットワークの安全性が向上します。
セキュリティ強化は、ネットワークのセキュリティも向上させ、最終的にはコンピューティング全体の安全性を強化する結果につながります。
長期的視点でのデータ転送アーキテクチャとハードウェアの役割
データの転送と管理において、ストレージシステムを介したハードウェアの高速化やオフロードが求められるタイミングは、今後の技術進化における重要な課題です。現在、データの圧縮、暗号化、重複排除といったタスクは主にコンピューティングリソースによって実行されています。しかし、これらの処理をスケーラブルに拡張していくためには、大規模アーキテクチャではボトルネックとなり得ます。
イノベーションにより、これらの処理がハードウェアによって高速化され、ストレージやネットワーク層へオフロードされることで、従来のコンピューティング負荷を軽減し、より効率的なデータ管理が可能となるでしょう。
データコンサルタントとしての提言
データストレージ戦略では、HDDとSSDの適切な配分を見直し、パフォーマンス要件に応じた最適化を行うことが重要です。
帯域幅の拡張は、GPUベースの分析基盤におけるデータ処理の効率を大幅に向上させます。適切なアーキテクチャの選定が成功のカギです。
セキュリティ強化は、デバイスとネットワークの整合性確保を含む包括的なアプローチが必要であり、投資を続けることでリスクを最小限に抑えることができます。
データ圧縮や暗号化のオフロードは、ストレージやネットワーク層へのシフトによって、コンピューティングリソースの負荷軽減を実現するための次の重要なステップとなります。
インテリジェントなデータレイクの青写真: データ主導のビジネス変革を支える基盤
リファレンスアーキテクチャの青写真は、企業がオンプレミスまたはクラウド環境にデータレイクを導入するための包括的なフレームワークを提供します。このアプローチにより、企業は大量のデータを効率的に管理し、適切なユーザーが必要なデータにタイムリーにアクセスできるようにします。これにより、貴重なインサイトがビジネスプロセスの改善や意思決定の最適化に直結するデータ基盤を構築します。
1. インテリジェントなデータレイクの基盤: データ探索、ガバナンス、セキュリティの確立
データレイクを成功に導くための基本的な要素として、データの探索、ガバナンス、および保護の機能を統合する必要があります。これに加え、企業全体で活用できるメタデータ層をAIや機械学習(ML)で拡張することが求められます。具体的には、次の点を含めます:
データカタログを通じた全データ資産の探索・インデックス化
データガバナンスの適用により、拡張性が高く再現可能なポリシーやプロセスの実装
データプライバシーおよび保護に関する業務・技術ポリシーを適用し、コンプライアンスを維持しつつリスクを最小化
このような構造により、ビジネス上のインサイトを引き出すための信頼性の高いデータ基盤が構築されます。
2. データエンジニアリング: あらゆる速度に対応するデータ取り込みと処理
データレイクの成功には、データエンジニアがバッチ処理、準リアルタイム、およびリアルタイムデータに対応することが不可欠です。企業は、高パフォーマンスなストリーミングおよびデータ取り込み機能を通じて、以下のような柔軟性と拡張性を確保します:
任意のスピードでのデータ取り込みをサポートするスケーラブルなインフラ
リアルタイムでのデータ可視化を可能にするインフラ強化
これにより、企業は多様なデータソースからのデータを迅速かつ効率的に処理し、ビジネスインサイトの獲得を加速します。
3. セルフサービスデータ準備: データアナリストのためのアジリティ
セルフサービスによるデータ準備は、企業全体でのデータの探索、アクセス、コラボレーション、共有を促進し、データアナリストの迅速な分析プロジェクト立ち上げを支援します。これにより、アナリストはデータレイク内外のデータ資産に容易にアクセスでき、アナリティクスのプロセスが加速されます。
4. AI搭載ツールの活用: 高性能データ処理の実現
データエンジニアは、AI搭載ツールを活用して、オンプレミスまたはクラウドでスケーラブルかつ高性能なデータ処理を実行します。例えば、Apache Sparkのような分散処理エンジンにより、次のようなタスクを効率的に実行できます:
データのクレンジング、変換および分析
ビッグデータに対するリアルタイム処理の実現
このような拡張性の高いデータ処理能力により、企業は膨大なデータセットから価値を迅速に引き出し、ビジネスインパクトを高めます。
5. ストリーム処理とアナリティクストランスフォーメーション
データレイクは、ストリーム処理やアナリティクスのトランスフォーメーションによって、他の社内データ(データウェアハウス、マスターデータ、イベントデータなど)と統合し、インサイトを強化します。これにより、次のようなメリットが得られます:
リアルタイムのワークフローやアラートの呼び出しによる機械学習アルゴリズムの適用
ストリーミングデータをバッチ処理用にデータレイクへ保存し、履歴分析に活用
こうしたデータフローの統合により、ビジネス運営におけるタイムリーな意思決定が可能になります。
6. 複数のデータ配信モードをサポート
インテリジェントなデータレイクは、リアルタイム、バッチ、イベント主導、パブリッシュ/サブスクライブなど、多様なデータ配信モードをサポートし、柔軟なデータアクセスと分析を実現します。これにより、次のようなメリットをもたらします:
業務の効率化とデータ利活用の最大化
複数モードによる柔軟なデータ供給と分析精度の向上
企業はこれらの機能を活用して、データの価値を最大限に引き出し、持続的な競争優位性を確保できます。
まとめ:インテリジェントなデータレイクのビジネスインパクト
インテリジェントなデータレイクの構築は、データ主導の意思決定を加速し、企業のビジネス変革をサポートします。AIと機械学習を活用したメタデータの探索、セルフサービスのデータ準備、リアルタイム処理によって、企業はデータから直接価値を引き出し、ビジネスパフォーマンスの向上を実現します。
データコンサルタントの視点から、企業におけるデータレイクの導入根拠やその管理上の課題を明確に整理し、企業全体のデータ戦略とアナリティクス能力の向上に焦点を当てました。
インテリジェントなデータレイクの導入を促す理由
現代の企業は、膨大なデータ資産を最大限に活用するため、迅速にデータレイクを導入し、既存のデータアーキテクチャを拡張しつつ、アナリティクス能力を飛躍的に高める必要があります。データレイクの導入により、ほぼ全てのデータソースから多様なデータを一元管理し、多層的な分析を行うことで、業務成果や意思決定の質を大幅に向上させることが可能です。
データレイクの管理が重要な理由
データ量の増加と次世代アナリティクス 現在、多くの企業が保有するデータ量は爆発的に増加しており、このデータ量の増大が次世代アナリティクスを可能にしています。しかし、データ量の増加は同時にデータマネジメントの課題を引き起こします。データレイクを効果的に管理することで、アナリストは企業の業績に関連するパターンや傾向を迅速に特定し、投資対効果や収益率などの主要指標を精密に評価できるようになります。
データの断片化とその影響 多くの企業では、部門ごとに分散したデータを個別に管理するデータマートが存在し、部門間のデータ共有や相互参照が困難な状況に陥っています。データの分散化により、業務部門はビジネス目標に関連するデータを効果的に分析することが難しく、データドリブンの意思決定が阻害されるケースが多発しています。データレイクの導入によって、データの一元管理と効率的な分析が実現され、部門間のデータ利用効率が飛躍的に向上します。
データガバナンスとデータ品質の確保 ビッグデータの多くは外部から取得され、その信頼性や構造が明確でないケースも多いため、データ品質やリスク管理に課題があります。適切なデータガバナンスを適用し、データの質を維持することは、正確な分析結果を得るために必須です。データレイクは、企業全体で統一したデータガバナンスを実施するための重要な基盤となります。
業務部門の課題
業務部門は、迅速な意思決定のために必要なデータにアクセスする上で以下の課題を抱えています:
信頼できるデータの不足により、適切な意思決定が困難
データへのアクセスが制限されており、効率的な分析が実現できない
IT部門の対応遅延に対する不満が増加している
データ分析における手作業の制約や、異種ツールによる非効率が存在
キュレーション済みデータセットのコラボレーション、共有、更新ができず、知識の再利用が進んでいない
このような課題を解決するためには、業務部門がセルフサービスでデータにアクセスし、分析を行うためのインフラとプロセスの整備が不可欠です。データレイクは、業務部門に対して柔軟なデータアクセスを提供し、データドリブンな意思決定をサポートします。
IT部門の課題
一方、IT部門もデータ管理と運用の負担が増加しています。主な課題として次の点が挙げられます:
業務部門からのデータに対する要求の増加に対し、リソース不足や対応の遅れが発生している
業務部門がデータをどのように利用しているかを把握できず、価値提供に苦戦
データの統制と管理能力の低下により、企業全体でのデータ活用戦略に支障をきたしている
IT部門は、データレイクを導入することで、業務部門のニーズに迅速に対応できるインフラを提供し、データ管理の一元化を進め、データ運用効率を向上させることが可能です。
まとめ:データレイク導入による全社的な効果
データレイクの導入は、業務部門とIT部門の両方の課題を解決する手段として機能します。データレイクにより、企業は膨大なデータを効率的に管理し、部門間のデータ共有やアナリティクスのスピード向上を実現します。これにより、企業全体でデータドリブンな意思決定を加速し、ビジネスパフォーマンスを最大化することが可能となります。
インテリジェントデータレイク設計における重要な検討事項
メタデータ管理とデータガバナンスの確立
データレイクの設計段階では、まずメタデータ管理とデータガバナンスのフレームワークを明確に定義することが重要です。データ資産の分類法やビジネス用語のグロッサリを標準化していますか?適切な監査可能性と透明性を確保するために、各データの由来やアクセス権限を追跡可能な形で維持していますか?
データ統合パターンの特定
利用するユースケースに応じて、必要なデータ統合パターンの数とその複雑さを評価します。例えば、リアルタイム処理が必要な場合は、ストリーミングデータの統合が重要となります。具体的にどの統合パターンが業務ニーズを満たすかを明確にしていますか?
データタイプの分類と取り込み戦略
データレイクに取り込むデータの種類(リレーショナルデータ、マシンデータ、ソーシャルデータ、JSONなど)を正確に把握していますか?それぞれのデータタイプに応じた最適な取り込み・保管方法を採用していますか?データの取り込み頻度や更新タイミングについても検討し、データストリームの効率化を図っていますか?
データアクセスプロセスの標準化
各データソースからデータを取得する際のプロセスを明確にし、最適化していますか?次の点について検討します:
データ取得の際に関与する関係者(IT部門、データエンジニア、ビジネスアナリストなど)
データ転送の頻度(リアルタイム、バッチ処理など)
取得するデータが、変更箇所のみに限るのか、データセット全体を取得するのか
セルフサービスの実現
IT部門のサポートなしで、社内のビジネスユーザーがデータを簡単に利用できる環境を整えていますか?特に、煩雑な手作業を減らすためのデータ準備ツールや、自動化されたデータクレンジング、キュレーション機能を導入することが重要です。
ストリーミングデータのエンリッチメント
ストリーミングデータを履歴データや他のコンテキスト情報でエンリッチメントする必要がありますか?ビジネス上の意思決定を支えるために、リアルタイムのデータ処理と過去のデータを組み合わせることが有効です。
データ品質管理の強化
ビジネスルールの適用やスチュワードシッププロセスを通じて、データ品質の問題を特定し、解消していますか?データの整合性や正確性を確保するためのプロセスやツールを導入し、継続的な改善が行われる仕組みを構築しましょう。
このように、データレイクの設計においては、技術的な選択肢だけでなく、データガバナンスやデータ品質、ユーザーの利便性といった観点も考慮し、全体的なデータ管理戦略に組み込むことが重要です。
データレイクハウス戦略の概要
統合されたデータソースの確立
データレイクハウスは、AI(人工知能)、BI(ビジネスインテリジェンス)、機械学習(ML)、ストリーミング分析、データサイエンスなど、あらゆる分析ニーズに対応するための信頼できる単一のデータソースを提供します。これにより、異なる分析フレームワークにまたがるデータ活用を一元管理できます。
データエンジニアリングの自動化と統合
データエンジニアは、データレイクとデータウェアハウスの両方の自動化プロセスを単一のユーザーインターフェースに統合することで、データ管理の効率化を図ります。これにより、シームレスに計画・実行でき、どちらか一方の環境に依存することなく柔軟な運用が可能です。
イベント駆動型アーキテクチャの選定
イベント駆動型のデータ処理において、LambdaアーキテクチャまたはKappaアーキテクチャを適用することで、事象のリアルタイム処理とバッチ処理の両方を効果的に管理します。具体的なユースケースに応じて、最適なアーキテクチャを選択し、データ処理の効率性と正確性を最大化することが求められます。
3層のレイヤーによるデータ処理
データレイクは、以下の3つのレイヤーを使って、機械学習モデルの学習を効率化します:
バッチレイヤー: すべてのデータで最も正確な結果を得られますが、処理遅延が発生する可能性があります。
スピードレイヤー: リアルタイムで低遅延の結果を提供し、迅速なフィードバックを可能にします。
サービスレイヤー: バッチとスピードの結果を統合し、複数のクエリに対応します。
この3層構造を活用することで、リアルタイムのデータ分析と正確性を両立できます。
予測能力の強化
データエンジニアは、これらのレイヤーを組み合わせることで、将来の事象をより正確に予測し、ビジネスに価値をもたらすためのインサイトを提供します。
リアルタイムデータ処理と継続的データ再処理
単一のストリーム処理エンジンで、リアルタイムのデータ処理と継続的なデータ再処理を実行します。これにより、継続的なデータの変更にも対応し、リアルタイムでのデータ活用が可能になります。
コスト効率の向上
データエンジニアは、低コストのハードウェアに投資し、複数のコードベース(バッチレイヤーとスピードレイヤー)を維持する代わりに、データの再生機能を活用します。このアプローチにより、マルチレイヤーLambdaアーキテクチャの冗長性を解消し、標準的なサービス品質を提供しつつ、一意の事象をリアルタイムで処理します。
データメッシュの採用
ドメインデータ製品の所有者は、セルフサービス型の共通データインフラを利用し、制御されたオープンなデータ共有パイプラインを開発します。これにより、データの非中央集権化が進み、柔軟で拡張可能なデータアーキテクチャが実現します。
非中央集権型分散型データファブリックの基盤形成
データメッシュの基本原則に基づき、以下の戦略を採用します:
ドメイン指向の分散データ所有権: 各ドメインがデータの所有権を持ち、スケーラブルなアーキテクチャを形成。
データを「製品」として管理: データを製品と捉え、その構築、展開、維持管理を行う。
セルフサービス型インフラ: 各データ製品が自律的に作成・管理できるインフラを提供。
連携した統制と相互運用性: 独立したデータ製品が連携し、相互運用できる標準を確立。
変化に柔軟に対応する分析戦略
データ環境、ユースケース、要求が常に変化する中で、データエンジニアはデータメッシュを活用して、より大きな価値を分析データから引き出すことが可能です。
このアプローチにより、データの所有権、セルフサービスインフラ、効率的なデータ処理を組み合わせ、長期的にスケーラブルでコスト効率の高いデータ戦略を実現します。
データレイクのアジリティにおける役割
データレイクの強みは、分析目的が決まっていない段階でも、受け取ったデータをそのままの形式で保管できる柔軟性にあります。データレイクは、異種の情報を組み合わせることで、構造化データ・非構造化データ、さらには組織内の異なる部門やサイロからのデータを統合し、これらすべてを一元的に分析することが可能です。この柔軟なリポジトリは、機械学習アルゴリズム、統計分析、さらには自然言語処理(テキストや音声・動画の解析)をサポートするツールと組み合わせることで、より深いインサイトを引き出すことができます。
言い換えれば、データレイクは将来的な使用方法がまだ明確でないデータのための保管場所として、企業のニーズに応える機能を持っています。このアジリティにより、異なるサイロからデータを取り込み、一元的に分析を行う環境が整います。
買収や統合プロセスにおけるデータレイクの活用
例えば、EdTech企業の買収においては、吸収した企業のデータをデータレイクに取り込む仕組みを整えることで、そのデータ運用の透明性を確保しつつ、既存の自社データと統合できます。このプロセスは、組織の統合をスムーズに進め、データの一元管理を実現します。
データレイクの実現を支える要素
データレイクの運用を成功させるためには、次の3つの要素が重要です:
低コストのストレージ:大量のデータを保存できるだけでなく、長期的な保管にも適したコスト効率の高いストレージシステムが必要です。
異種データを処理できるツールの可用性:緩く構造化されたデータや非構造化データを処理するためのツールの活用が不可欠です。これにより、従来のデータウェアハウスでは対応が難しかったデータも統合・解析できます。
非同期データ取り込みの高速化:高い帯域幅でデータを非同期に取り込む仕組み(例:Eメールの受信のように、データが届いたら即座にデータレイクに取り込む)を構築することが、リアルタイムに近いデータ活用を可能にします。
この視点からは、データレイクが企業のデータ戦略におけるアジリティとスケーラビリティの両立を実現し、さまざまなデータを一元管理・分析するための柔軟で拡張性の高い基盤であることが強調されます。特に、買収後のデータ統合や異種データの管理においては、データレイクが重要な役割を果たします。
データ保存の戦略と課題:構造化データからデータレイクへ
ビジネスにおける意思決定を支えるため、取得したデータは効果的に保存し、後の分析に活用する必要があります。従来の方法では、データは運用面での利用を前提とした、明確に定義されたフィールドを持つ構造化形式で保存されることが一般的でした。例えば、データベースに「教科単位」や「クラスサイズ制限」といったフィールドを設け、それに対応するデータを格納する形です。これはトランザクションデータの処理には非常に適していましたが、より深い分析を行うために重要な情報が失われるリスクも伴います。従来のリレーショナルデータベース(RDB)は、そうした構造化データの管理に長けていました。
データ保存技術の進化:クラウド時代の新たな選択肢
ここ数十年の間に、リレーショナルデータベースがトランザクション処理における標準的なソリューションとして広く普及しましたが、近年のデータの多様化やインターネットの普及によるトランザクション数の急増により、従来の手法だけでは対応しきれない状況が生じています。特に、トランザクションデータ以外の非構造化データや、事前に定義された「フィールド」に収まらないデータに対しては、クラウド向けに特化された新しいデータ保存技術が登場しています。
例えば、Amazon Timestreamは、時系列データを効率的に管理するために特別設計されたデータベースで、センサーからのデータや市場動向の追跡に利用できます。また、Amazon Quantum Ledger Database(QLDB)は、ブロックチェーン技術を活用してデータの履歴を検証する必要がある場合に適しており、さらにAmazon Neptuneは、ソーシャルネットワークのように複雑な接続関係を表現するデータに対応しています。
これらの新しいツールの登場により、企業は従来のリレーショナルデータモデルに縛られることなく、より柔軟でスケーラブルなデータ管理を実現できるようになりました。
データレイクの利点とアジリティの向上
さらに、今日のデータ保存戦略では、用途が未定なデータや多様な形式のデータを、保存時に事前に構造化せずにそのままの形で保持できる「データレイク」の活用が増えています。データレイクの最大の強みは、構造化データと非構造化データの両方を一つのリポジトリに集約し、異なるビジネス機能やデータサイロからの情報を統合して分析できる点です。特に、機械学習アルゴリズムや自然言語処理、動画・音声データの分析に対応できる現代のツールは、データレイクの活用をさらに強力なものとしています。
データレイクの導入と実用性
データレイクは、データがどのように活用されるかが事前に決まっていない場合でも、データの保存を可能にし、後の分析に柔軟に対応します。企業は、買収や他の機能サイロからのデータを迅速に統合し、透明性を保ちながら運用を行うことができるようになっています。特にEdTechなどの業界では、吸収した組織からのデータを自社のデータレイクに取り込むことで、効率的なデータ統合と分析が可能です。
今後の課題と展望
これを可能にしている要因は、低コストのストレージ、非構造化データを含む多様なデータの処理ツール、そしてデータを高速かつ非同期で取り込む技術(Eメールのようなリアルタイムのデータ転送)です。データコンサルタントとして、これらの技術の適切な導入・管理を提案することで、企業のデータ活用をさらに推進することができます。