
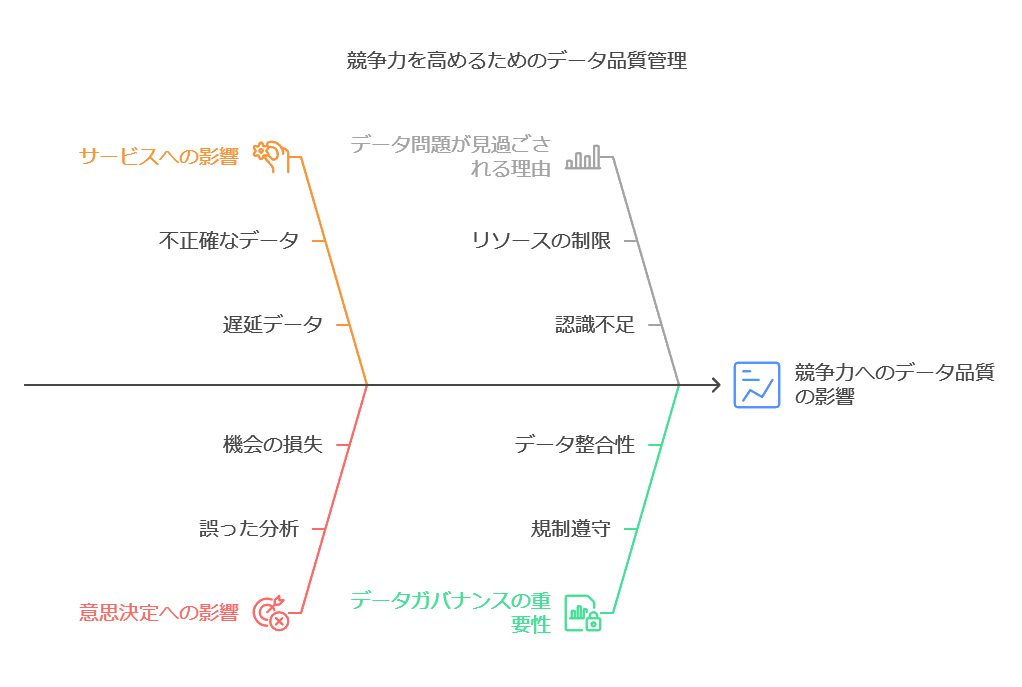
データ品質管理の重要性とその影響: 企業競争力を左右する要因
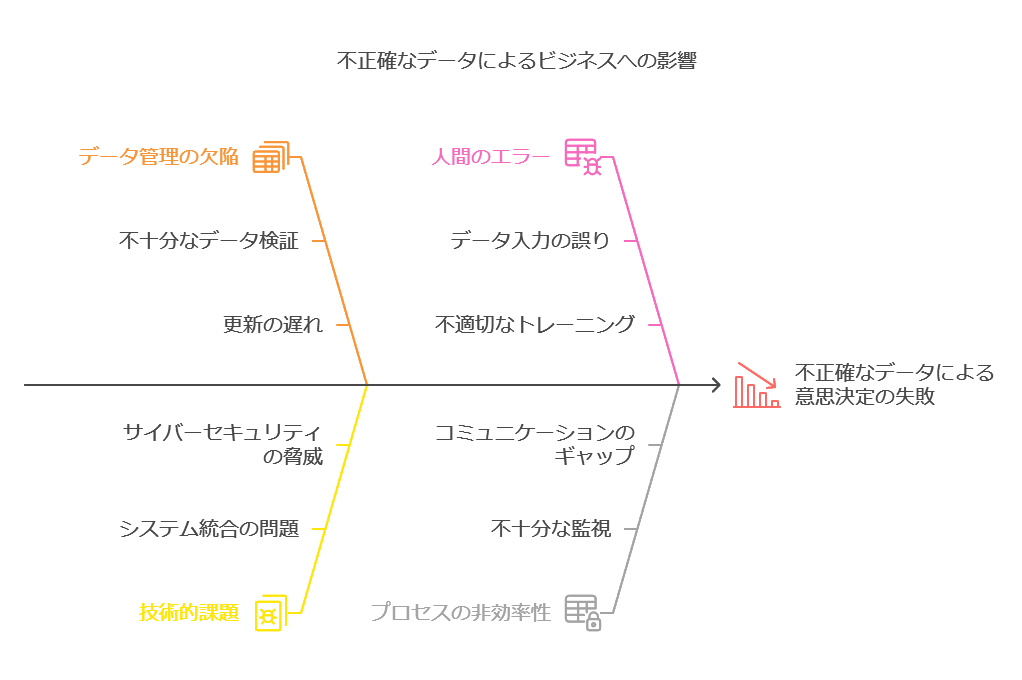
企業が提供するサービスの品質や意思決定の正確性は、データの品質に大きく依存しています。不正確なデータを放置することは、顧客満足度の低下やビジネス判断の誤りを引き起こし、結果として企業への信頼を損なうリスクがあります。Wakefield Research社の調査では、85%の企業が不正確なデータによって誤った意思決定を行い、収益に直接的な損失を被ったと報告されています。
なぜデータの問題は頻繁に見過ごされるのか
サーバーやネットワークの障害は、監視システムによって比較的容易に発見され解決できます。しかし、システムが正常に動作していても、データの中に潜む問題は発見が難しく、対応が遅れることが多いのが現状です。データの品質問題に対応が難しい理由には、以下の3つが挙げられます。
データの集約により、問題の発見が遅れる BIレポートやAIによる解析結果は、さまざまなデータソースから集約された情報を基にしています。これにより、最終結果から元データの品質に問題があることを発見するのは容易ではありません。たとえば、集計結果やグラフだけを見ても、元データの誤りや欠落に気づけないケースが多くあります。
ユーザーの知識不足による問題の見逃し ユーザーは、自身が利用しているデータの由来や背景を十分に理解していないことが多く、データに問題があると感じても、その原因を特定したり解決策を見つけることが難しい状況です。データの欠落や不正確さに気付いても、システムやデータフローに関する知識が不足しているため、解決までに時間がかかります。
データ担当者と業務部門の連携不足 データ担当者や情報システム部門はシステムの専門家であるものの、業務知識に詳しくない場合があります。そのため、データに問題が発生していても、それが業務にどのような影響を及ぼすかを正しく理解していないことがあります。これにより、問題のあるデータがそのまま業務ユーザーに提供され、意思決定に悪影響を与えるリスクが高まります。
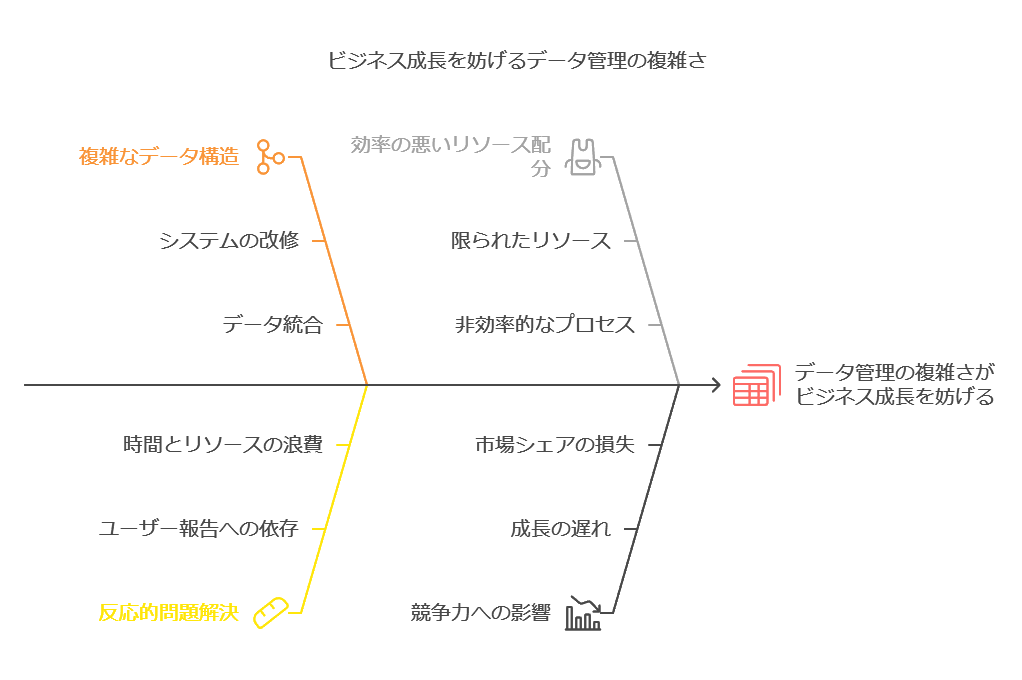
データの問題を放置するリスクと複雑化するシステム
ビジネスの規模拡大に伴い、システムの改修や統廃合が繰り返されることで、データ構造はますます複雑化していきます。多くの企業では、データの問題が発生しても、ユーザーからの報告を待って初めて気づき、その都度対応に多くの時間とリソースを費やしています。このような事後対応型のアプローチでは、ビジネスの成長を阻害する可能性が高く、企業の競争力を損なうリスクがあります。
データの可観測性向上が解決策の鍵
データの問題を根本的に解決するためには、リアルタイムでデータ品質を監視し、迅速に対応できる「データの可観測性」を向上させることが重要です。次項では、可観測性を高めるための具体的なアプローチについて詳しく解説します。
ここでは、データの品質問題が企業に与える影響を明確にし、ビジネスにおけるリスクを強調しています。また、具体的な問題点(データ集約による発見の遅れ、ユーザーや担当者の知識不足)に焦点を当て、データコンサルタントとしての洞察を提示しました。最後に、解決策として「データの可観測性向上」を強調し、次のステップを導入する形でストーリー性を持たせています。
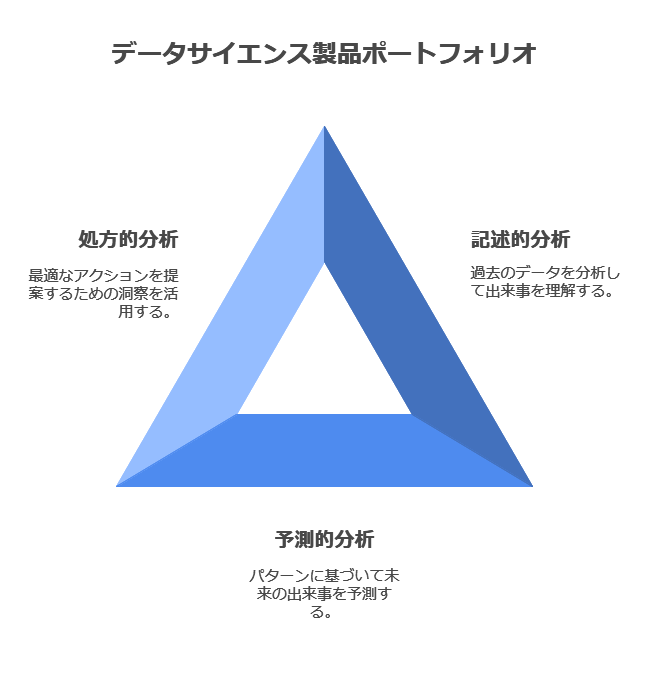
データ利活用におけるケイパビリティ — データドリブン戦略
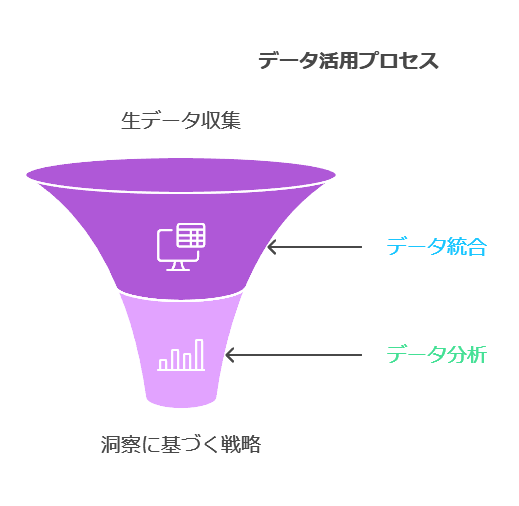
データ活用の3つの要素
データ活用を効果的に進めるためには、「データをためる」「データをつなぐ」、そして3つ目の重要な要素である「分析・活用する」というプロセスが不可欠です。IBMはこれらのプロセスに対して、業界において確固たる地位を築いており、特にデータサイエンスの分野で強力な製品群を提供しています。
3つの分析のゴール
データサイエンス製品ポートフォリオは、以下の3つの分析ゴールを包括的にサポート:
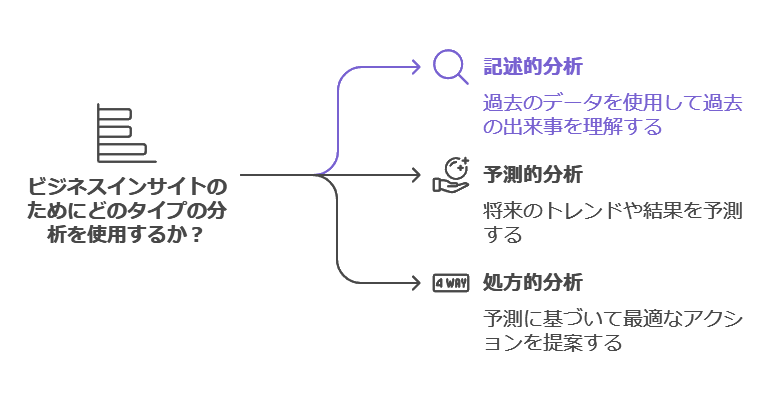
Descriptive Analysis (記述的分析): 何が起きたのかを過去のデータから分析する。
Predictive Analysis (予測的分析): 未来に何が起こりうるのかを予測する。
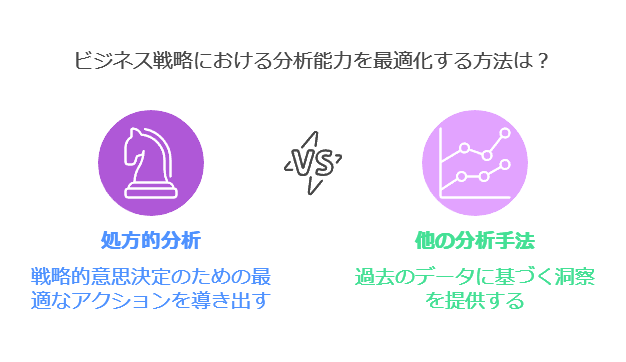
Prescriptive Analysis (処方的分析): 予測された結果をもとに、最適なアクションを導き出す。
特に処方的分析は、ビジネスの戦略立案や意思決定において最も高度な分析手法であり、これを完全にカバーするITベンダーは限られていこれらすべての領域をサポートすることで、企業のデータドリブン経営を強力に後押しします。
プログラミング不要のユーザー向けサポート
データサイエンス製品群は、プログラミング経験が豊富なエンジニアだけでなく、GUI(グラフィカルユーザーインターフェース)を用いて操作を行いたいユーザーも幅広くサポートしています。これにより、データ分析スキルのレベルに関わらず、組織内のあらゆるメンバーがデータを活用できる環境が提供されます。
成果物の再利用と連携の強化
製品間のシームレスな連携を実現しており、データ分析で得られた成果物を共有し再利用することが可能です。これにより、データ分析のプロジェクトを効率的に進めることができ、時間とコストの削減にも貢献します。
オンプレミスとクラウドの統合ソリューション
図4で示されるように、IBMはこれら3つの領域(記述的、予測的、処方的分析)をカバーしながら、機械学習を活用し、オンプレミスとクラウド環境をシームレスに統合しています。これにより、企業はクラウドの利点を最大限に活用しつつ、オープンソース技術を取り入れることで、柔軟なデータ活用が可能になります。
デジタルトランスフォーメーションの支援
データサイエンスおよび機械学習製品群は、企業が直面するデジタルトランスフォーメーションをサポートし、企業がデータドリブンな意思決定を迅速かつ効果的に行うための基盤を提供します。IBMのソリューションは、オンプレミスやクラウドの境界を超え、データを活用した未来志向のビジネス展開を支援します。
データコンサルタント視点のまとめ
データの蓄積、接続、そして分析・活用の3つの柱を基に、企業はデータドリブン経営を実現し、競争優位性を確保することが可能です。データサイエンスソリューションは、分析の高度化、オープンソース技術の活用、そしてクラウドとの統合により、企業のデジタルトランスフォーメーションを加速させる強力な武器となります。
データドリブン経営とインサイトドリブン経営へのステップ
データドリブン: 経営への第一歩
データドリブン経営を実現するには、どこからスタートすべきでしょうか?
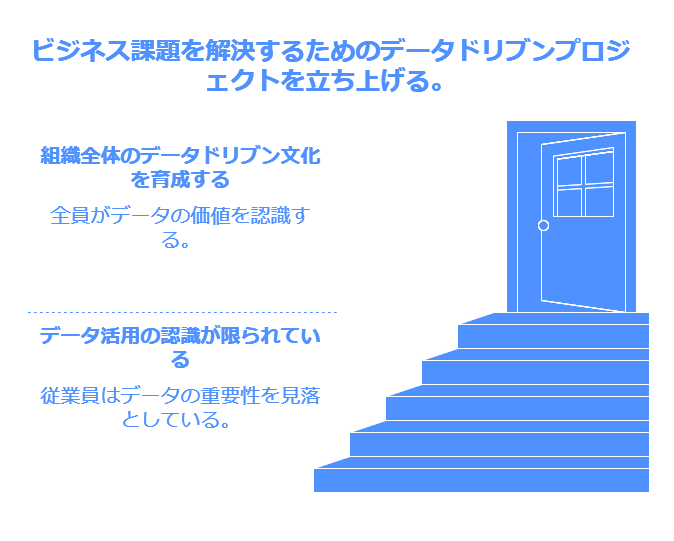
多くの場合、最初のステップは、特定のビジネス課題を解決するためにデータを活用するプロジェクトの立ち上げから始まります。チームが編成され、特定のテーマについて実際のデータを用いて課題を解き明かそうとするのです。この取り組みが成功すると、その成果に感銘を受けた他の社員や部門もデータ活用の重要性に気づき、徐々に組織全体に定着していきます。
企業文化の醸成とデータサイロの解消
これまでにも述べたように、データドリブンを目指すには、企業カルチャーが大きな役割を果たします。しかし、それだけでは不十分です。データ活用を推進するためには、IT部門、人事、会計・経理など異なる部門間の壁を壊し、データサイロを解消することが不可欠です。部門ごとのデータが孤立している状態では、全社的なインサイトを得ることは困難です。データの統合と共有を促進することにより、組織全体がデータの力を最大限に活用できるようになります。
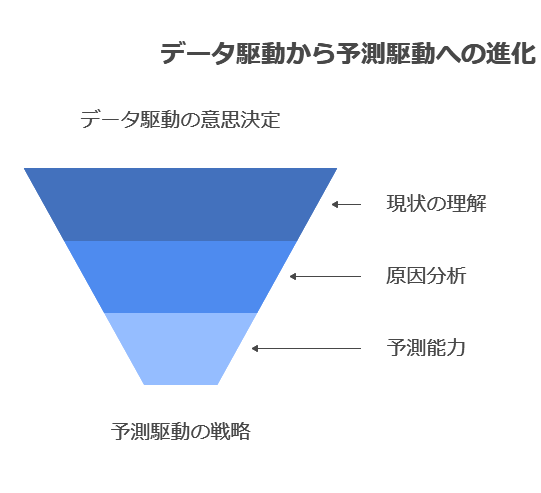
データ活用の初期段階: 現状把握と原因分析
この段階でのデータ活用の主なテーマは、「何が起きているのか?」という現状の把握です。データの可視化とレポートによって、ビジネスの現状を客観的に理解することが可能になります。さらに進んで、「なぜそれが起こったのか?」という原因分析を行うケースもありますが、ここではまだ主に現状の理解に焦点が当てられています。
インサイトドリブン: 次の段階への進化
データ活用が進み、次の段階に移ると、組織は「インサイトドリブン」なアプローチに進化します。この段階では、現状の把握や原因分析に加えて、「次に何が起こるのか?」を予測する能力が求められるようになります。
予測と意思決定の自動化
インサイトドリブンの段階では、データを基にした予測分析を活用して、将来の展開を予測し、ビジネスの成果を最大化することが可能になります。ここでの目標は、単に過去を分析するだけでなく、未来を見据えてビジネスを先回りする意思決定を行うことです。また、AIや機械学習を活用することで、意思決定の一部を自動化し、意思決定プロセスの効率化を図ることが可能です。
インサイトドリブンの技術基盤
この段階では、AI、機械学習、ディープラーニングといった先進技術が、ビジネスにおけるデータ活用の基礎を支えます。これらの技術を活用することで、企業はより高度なインサイトを得ることができ、デジタルトランスフォーメーション(DX)を推進する上での競争優位性を獲得します。
ディスラプションへの対応と創造的破壊
インサイトドリブン経営が進化すると、企業は単に現状を維持するだけでなく、**創造的破壊(ディスラプション)**を引き起こす方法を模索するようになります。これにより、競争優位性を高め、新たな市場やビジネスモデルを開拓する可能性が広がります。
結論: データドリブンからインサイトドリブンへの移行
データドリブン経営は、まず小さなプロジェクトから始まり、データに基づく意思決定が組織全体に浸透することで進化していきます。そして、インサイトドリブン経営へと移行することで、企業は未来を予測し、意思決定を自動化することで、競争力をさらに強化することが可能となります。このプロセスを成功させるためには、データの統合、技術基盤の整備、そして企業全体でのデータ文化の醸成が重要です。

データドリブン経営における多様なワークロードとデータガバナンスの重要性
データドリブン経営における多様なワークロードのサポート
データドリブンな経営を実現するためには、企業が扱うさまざまなデータワークロードに対応できる環境が不可欠です。例えば、従来のリレーショナルデータベース管理システム(RDBMS)だけでなく、データウェアハウス、NoSQLデータベース、Hadoopなどのソリューションもその範囲に含まれます。IBMはこの多様なデータ管理ニーズに対して、幅広いデータベースソリューションのポートフォリオを提供しており、これにより企業の多様なワークロードを支えています。
さらに、IBMの大きな特長として、これらの異なるデータベースソリューションに共通のSQLアクセスレイヤーを提供しています。これにより、エンドユーザーやアプリケーションはデータベースの種類に関わらず、アプリケーションを変更せずにデータにアクセスできるという利便性が得られます。IBMのこの共通レイヤーは、同社のデータベースだけでなく、Oracleなど他社製のデータベースもサポートしており、異なるシステム間のデータ管理に一貫性と効率性をもたらします。
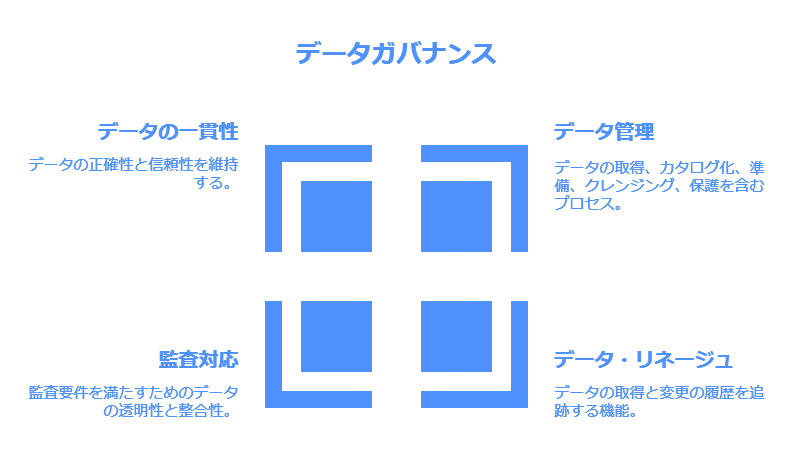
データガバナンスの重要性
データドリブン経営のもう一つの重要な要素が、データガバナンスです。企業におけるデータ管理は、その取得からカタログ化、データ準備、クレンジング、保護に至るまで、さまざまなプロセスを伴います。IBMは、これらの各プロセスをサポートする豊富な機能を提供しており、その製品は各種調査会社レポートでも高い評価を得ています。
特に注目すべき点は、データ・リネージュ(データの来歴管理)の機能です。この機能により、データがいつ、どこから取得され、その途中でどのような変更が加えられたかを追跡することが可能です。これにより、監査対応やデータのクリーンな状態の維持、そしてデータの一貫性を確保することができます。
データカタログ化とビジネス用語集の活用
さらに、IBMのデータガバナンス製品は、データをカタログ化し、企業内のビジネス用語集を作成する機能も提供しています。これにより、事業部門のユーザーやIT部門の開発者が、必要な信頼できるデータを簡単に見つけ、アクセスすることができます。データの可視性とアクセス性が向上することで、企業全体でのデータ活用が加速し、より効率的な意思決定を支援します。
結論: データドリブン経営を支える基盤
データドリブン経営の成功には、複数のデータベースソリューションをシームレスに統合し、効率的なデータ管理を実現することが不可欠です。また、データガバナンスの重要性を認識し、データの来歴やカタログ化を含む高度な管理機能を活用することで、企業はデータの一貫性と品質を保ちつつ、競争力のあるビジネスインサイトを得ることが可能となります。
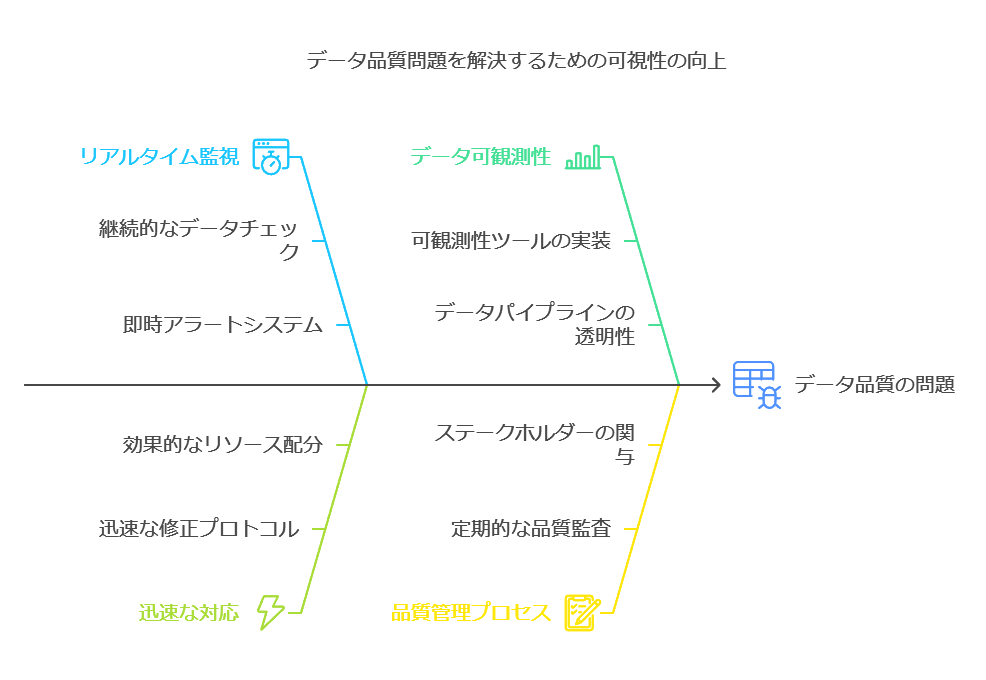
データ活用基盤構築における留意点と成功のための4つのポイント
データ活用基盤構築の重要性とDX推進の鍵
デジタルトランスフォーメーション(DX)の進展に伴い、業務の変革や効率化、さらには新たな価値創造を実現した企業の成功事例が次々と報じられるようになっています。しかし、その一方で、データを十分に活用できていない企業も多く、成功と遅れの二極化が進んでいるのが現状です。
データ活用が進まない企業には、いくつか共通する課題があります。具体的には、以下のような問題に直面しています。
データの所在が不明確であり、必要なデータを入手する際に、情報システム部門へ逐一依頼する必要がある。
データの品質に問題がある(欠損値や外れ値など)、そのままでは分析や意思決定に活用できない。
データ加工に時間がかかり、分析やアクションに移すまでのスピードが遅れてしまう。
これらの課題は、新型コロナウイルスの影響によるリモートワークの普及によってさらに顕著になりました。リモートワークを円滑に行うためには、どこにいても必要なデータに迅速にアクセスできる環境が必要です。こうした状況下、多くの企業がデータ活用基盤の構築に迫られるようになっています。
データ活用基盤構築を成功に導く4つのポイント
データ活用基盤を構築する際には、次の4つのポイントに注意することが、プロジェクトを成功に導くカギとなります。
目的を明確にする
まず、データ活用基盤を導入する目的を明確にすることが重要です。業務効率化を目指すのか、新規ビジネスの創出や顧客体験の向上を狙うのかなど、具体的な目標を設定することで、データ基盤の方向性や必要な機能が定まります。
組織体制を整える
データ活用基盤は、IT部門だけの責任ではなく、経営層から現場の各部署まで横断的な協力体制が必要です。データの所有者や利用者、責任者を明確にし、データガバナンスやセキュリティポリシーを統一することで、基盤の円滑な運用を支えます。
構築する環境を選定する
データ活用基盤は、クラウド、オンプレミス、またはそのハイブリッド環境で構築することが考えられます。企業の規模、業界特性、データの取扱量や重要性を踏まえたうえで、最適な環境を選定することが重要です。柔軟性と拡張性があり、将来的なニーズにも対応できる基盤を選ぶことが求められます。
コストを管理する
データ活用基盤の構築には、初期投資に加えて、運用・保守にかかるコストも考慮する必要があります。ROI(投資対効果)を明確に評価し、データ活用基盤がビジネスにどのような価値をもたらすのかを定量的に把握することが、長期的な成功のための鍵となります。
まとめ
データ活用基盤の構築は、DX推進のための重要なステップです。しかし、成功させるためには、目的の明確化、組織全体での連携、最適な環境選定、そしてコスト管理といったポイントに注意が必要です。これらの要素を踏まえて進めることで、企業は効率的なデータ活用基盤を構築し、データドリブンな経営へと確実に進化していくことができます。
データ活用基盤による業務効率化の実現と役割分担
データ活用基盤で実現する業務効率化
データ活用基盤を構築することで、どのような業務効率化や改善が可能になるのでしょうか?ここでは、実際にデータ活用基盤の効果を実感している企業の事例をもとに、その効果を探ります。
事例: 製造業A社におけるデータ統合とAI分析による生産性向上
製造業を営むA社は、生産性の向上、業務変革、そして業務効率化を目指し、全社的なデータ活用基盤を導入しました。A社では以前から材料や製造現場の環境データを収集していたものの、製造工程ごとにデータがバラバラに管理され、統合的なデータ分析が困難でした。この分散管理が、データ利活用の大きな障害となっていました。
A社は、これらの課題に対応するためにデータ活用基盤を構築し、各製造工程のシステムからのデータを統合できる環境を整えました。まず最初に取り組んだのは、不良品の削減です。以前は熟練の社員が経験やスキルに基づいて予測を行い製造を管理していましたが、それでも不良品の発生を完全に防ぐことはできませんでした。
データ活用基盤の導入後、A社はAIを活用して製造データを解析し、予測精度を向上させました。その結果、不良品の発生を大幅に減少させることに成功しました。この取り組みが成功したことで、社員のモチベーションも向上し、次々に新たなデータ活用のアイデアが生まれるようになりました。
A社では、一つの目的を達成したら次の課題に取り組み、それを全社に横展開することで、さらなる生産性の向上を目指しています。
データ活用基盤での役割分担: 5つの主要な役割
データ活用基盤の効果的な運用には、各専門職の明確な役割分担が重要です。以下の5つの役割が、データの提供・利用において中心的な役割を果たします。
データ・スチュワード (Data Steward)
全社のデータを収集し、データの品質を管理します。データの正確性や一貫性を保つことで、全社的に信頼できるデータの基盤を提供します。
データ・エンジニア (Data Engineer)
データの整理・変換を行い、データが利用可能な状態になるように整備します。大量のデータを効率的に管理し、分析に適したフォーマットに変換する重要な役割を担います。
データサイエンティスト (Data Scientist)
データを解析し、業務改善のための知見を提供します。統計モデルや機械学習を活用し、現場の業務に対する具体的な提言を導き出します。
ビジネス・アナリスト (Business Analyst)
業務の現状を理解し、現場のニーズをデータ活用に落とし込む役割です。データ活用がもたらす効果を具体的なビジネス成果に結びつけるための橋渡し役となります。
アドミン (Administrator)
データ活用基盤上で使用するアプリケーション全体を管理します。システムの安定運用とセキュリティを確保し、ユーザーが快適にデータへアクセスできる環境を提供します。
まとめ
データ活用基盤の導入は、データの統合管理やAI分析による生産性向上といった効果をもたらし、業務効率化を実現します。しかし、それを成功させるには、適切な役割分担と組織体制が不可欠です。データ・スチュワードからデータサイエンティストまで、各専門職が協力し合い、効果的にデータを活用することで、企業は持続的な改善と競争力の向上を目指せます。
データ活用基盤構築における4つの重要ポイント
1. 明確な目的設定
データ活用基盤を構築する際に、最も重要なステップは目的を明確に定めることです。「データ活用基盤を作りたい」という曖昧な目標では、プロジェクトの進行が滞る可能性が高くなります。まずは、現在の課題を整理し、それに対応するための具体的な目標を定めましょう。特に、最初の段階では小規模なプロジェクトから開始することが有効です。成功事例を積み重ねることで、その後の展開がスムーズに進むため、目的を持った段階的なアプローチが求められます。
2. 組織体制の整備
データ活用基盤の構築は、情報システム部門だけでなく、データオーナー、データ分析担当者、データガバナンス担当者など、複数の関係者が協力して進める必要があります。特に、部署間でデータを共有し利活用するためには、データの公開範囲やデータガバナンスに関するルール作りが重要です。データのマスキングや個人情報の取り扱い、また業務におけるデータの定義や用語の統一は、早期に合意を形成しておくことが必要です。
また、データカタログの作成も考慮するべきです。これにより、社内で誰がどのデータを持っているかが明確になり、エンドユーザーやデータ分析チームが必要なデータを素早く見つけて活用できるようになります。
3. 環境選定の重要性
データ活用基盤をどの環境で構築するかも、成功に向けた重要な要素です。まずは既存データの状態(データの所在、件数、内容、更新頻度など)を把握し、基盤に求められる要件を明確にします。主な選択肢としては、オンプレミス、IaaS、SaaSがあります。
オンプレミス: ハードウェアとソフトウェアの全てを自社で所有・運用するため、初期コストや運用負荷は高くなりますが、カスタマイズ性に優れています。
IaaS (Infrastructure as a Service): ハードウェアを所有せず、ソフトウェアは自社で管理します。オンプレミスよりも拡張性が高く、運用コストの調整が可能です。
SaaS (Software as a Service): ハードウェアやソフトウェアの全てを外部のサービス事業者から利用します。初期コストや開発工数を抑えられ、特にスモールスタートに適した選択肢です。
個人情報を取り扱う場合は、特にSaaSやIaaSでの利用に際して、個人情報が含まれるデータのアップロード制限など、適切なガバナンスを設定する必要があります。現状のデータ管理状況や活用目的に応じた、最適な環境を選択しましょう。
4. 長期的な費用計画
データ活用基盤は、構築しただけでは完結しません。運用と保守が不可欠であり、そのための費用を事前にしっかりと把握することが大切です。基盤構築後に発生する主な費用は、以下の通りです。
新たなビジネスニーズに応じた機能追加やソフトウェアの導入。
データ量の増加に伴うハードウェアやネットワーク容量の拡張。
上記対応のために必要となる人的リソースの確保。
さらに、基盤を構築する環境によって運用コストは大きく異なります。オンプレミスではハードウェアの更新費用が発生し、IaaSやSaaSでは利用規模に応じたランニングコストが増加します。これらの費用項目を中長期的に見積もり、運用計画を立てることが、持続可能なデータ活用基盤の運営に不可欠です。
まとめ
データ活用基盤の構築を成功させるためには、目的の明確化、体制の整備、環境の選定、そして長期的な費用計画が不可欠です。これら4つの要素を適切に管理することで、企業は効果的なデータ活用により、DX推進を加速させ、競争力を高めることができるでしょう。
次世代データプラットフォームとDX成功のためのデータ活用
これからデータ活用基盤を構築しようとしている企業にとって、次世代データプラットフォームは最適な選択肢となるでしょう。オンプレミス、IaaS、SaaSのいずれの環境でも利用可能であり、データ活用に必要な全ての機能を備えた統合的なプラットフォームです。以下は、主な機能の概要です。
主要機能: データの接続から活用まで一貫サポート
データの接続:
データ検索、可視化などの機能を活用して、企業内外の様々なデータを簡単にアクセス可能にします。データの所在を迅速に特定し、視覚的に理解できる環境を提供します。
データの整備:
データ理解、データ加工機能により、データのクレンジングや整合性確認を効率的に行えます。これにより、データの品質向上と正確な解析が可能になります。
データの活用:
ダッシュボード化や分析モデルの作成を支援する機能を提供し、現場の意思決定を強力にサポートします。これにより、ビジネスインサイトを迅速に得ることが可能です。
従来のデータ分析ソリューションでは、複数のツールを使い分ける必要があり、ツールの操作やデータの準備に多くの時間とリソースが費やされていました。データ加工から分析までを統合的なGUIで提供するため、フルサイクルのデータ処理を一貫して管理できる所についてはが大きな強みとなります。これにより、データ分析のサイクルが大幅に短縮され、スピーディーなデータ利活用が実現します。
デジタルトランスフォーメーション (DX) におけるビジネスモデルの変革
デジタルトランスフォーメーション(DX)は、単なる技術導入ではなく、ビジネスモデルそのものを変革するプロセスです。従来のような「一度限りのトランザクション」を繰り返すビジネスから、成果重視のアズ・ア・サービス(XaaS)モデルに移行していくことが求められています。これにより、企業は持続的な収益源や、レベニューシェアなどの新たなビジネス機会を生み出すことができます。
しかし、DXを進めていると認識している企業の多くが、実際にはまだ**データドリブン(データ駆動)**の段階に留まっているケースが見られます。つまり、データを収集し活用はしているものの、データを戦略的に活かしきれていないという状態です。
DXに向けた成功のためには、データドリブンから始まり、**インサイトドリブン(洞察駆動型)**へ、そして最終的にはビジネス全体がデジタルトランスフォーメーションを遂げる段階へと進化させる必要があります。それぞれの段階で成功するために重要な要素は、次の章で詳しく説明します。
DX成功のためのデータ利活用の3つのカギ
データの可視化と統合:
分散されたデータを一元的に管理し、データ同士を連携させることで、全社的なデータ資産として活用できる環境を整備します。
データ分析の高速化:
データ処理サイクルを最適化し、より短い時間で精度の高い分析結果を得ることが、競争優位を築くための鍵となります。
組織的なデータ文化の醸成:
データを活用するスキルを持つ人材を育成し、データの利活用を促進する社内体制を整えることで、DXの持続可能な推進が可能になります。
このように、次世代データプラットフォームは、企業がデータを活用してDXを成功に導くための強力な基盤となるでしょう。データドリブンからインサイトドリブン、そしてDXの達成に向けた一貫したアプローチが重要です。
データ時代を牽引するテクノロジーと組織への影響
データ主導の時代において、企業が競争優位を築くためには、運営方法や顧客関係、データの取り扱いに変革をもたらすテクノロジーの導入が鍵を握ります。特に、5G、IoT、AI/機械学習、AR/VR、ブロックチェーン、エッジコンピューティングは、データの生成や処理に大きな影響を与え、企業がより生産的にデータを活用する方法を提供します。
データ生成と活用の視点
IoT、AR/VR、ブロックチェーンは直接的にデータを生成する役割を担い、一方で5G、エッジコンピューティング、AI/機械学習はデータの生成環境や処理をサポートします。これらの技術がもたらす膨大なデータ量は、企業の戦略と運営に今までにない生産性向上のチャンスをもたらします。
技術の普及がもたらす新たな課題
企業がこれらの技術を活用しない場合でも、データ転送や処理の高速化、低遅延、収集能力の向上が市場全体で進んでいるため、間接的にその影響を受けることになります。例えば、5G対応のネットワークが普及すると、動画ストリーミングなどのデータ消費量が増え、企業にとっては新たなインフラ要求が生じます。
課題への認識と対応策の欠如
ITやビジネスマネージャーは、新しい技術がもたらすデータ増加の可能性を理解し、短期的な導入展開に期待を寄せていますが、データの急増に対するリスク管理が十分でない場合、組織全体に深刻な問題を引き起こしかねません。特に、準備不足のままでは、管理されずに放置される「ダークデータ」が増加し、データ活用による価値を享受することが困難になります。
データコンサルタントの視点からの提言
データ戦略を有効に活かすには、以下のようなアプローチが重要です:
データ管理体制の強化
新しい技術導入前に、データ管理ポリシーとそのリソース体制を見直し、増加するデータの効率的な収集と処理、暗号化を行う基盤を整備する必要があります。
データガバナンスとダークデータ対策
データの増加がもたらすダークデータ問題への取り組みが急務です。データガバナンスの強化と不要なデータの識別・削除を定期的に実施することで、データの品質維持とセキュリティが確保されます。
スケーラブルなインフラの整備
5Gやエッジコンピューティングを含む新技術の導入により、将来的なデータ負荷増加を予測し、スケーラブルなクラウドインフラやデータストレージの確保が重要です。
このように、新しいテクノロジー導入はその効果を十分に発揮させる一方、管理負荷やリスクを軽減する体制構築が求められます。
データ活用に関する課題と解決へのアプローチ
データ活用の主要な課題
多くの組織がデータドリブンな意思決定の重要性を認識している一方で、次のような課題が依然として存在しています。
人材不足とスキルギャップ:データ分析ツールを扱える人材の不足、または分析スキルやITの基礎知識が不足しているケースが多く見られます。データよりも経験や直感を重視する傾向が強いことも、データ活用の推進に障壁を生じさせています。
ツールと予算の制約:データ分析ツールの導入予算が確保できず、さらにツール導入の成果を定量化しにくいため、十分な投資を実行できない企業も多いです。また、ツール導入後に利用者向けの研修や教育が不足していることも課題です。
データ管理の分散と品質の課題:社内データの品質が低かったり、データが組織内で分散・サイロ化していることがしばしば見られ、統合的なデータ利用を難しくしています。また、Excelでの管理が主流のため、データリテラシーの向上が求められています。
計画段階での停滞:データ活用に取り組もうとしても、何から始めるべきか分からず行動に移せないケースも少なくありません。
データ活用環境の強化とIPAの取り組み
IPAでは、データ活用と分析における広範なエコシステムを構築しており、エンジニア、データサイエンティスト、アナリストといった専門人材が、40を超えるデータソースから得られるデータを活用できるようにしています。このデータ基盤には以下のようなソースが含まれます:
AWSのデータレイク(70億件以上のトランザクションデータを保存)
オンプレミスのデータウェアハウス(Oracle、Teradataなどの複数の技術)
外部API(Google APIなど)
また、IPAのプラットフォームはパーソナルバンキング、コーポレートバンキング、ウェルスマネジメント、マーケットなど、さまざまな事業単位が利用しており、論理データファブリックにより、約250名のデータサイエンティストとアナリストがアクセスできるデータサイエンスラボとデータマーケットプレイスが構築されています。
グローバルなデータ活用のユースケース
IPAの論理データファブリックとそれが実現するグローバルなIPAフレームワークにより、幅広いユースケースがホストされています。例えば、モバイルバンキングにおいても、リアルタイムデータの利用が進められており、より迅速でパーソナライズされたユーザー体験を提供できるようになっています。