
目次
「データ仮想化」や「データカタログ」の定義と価値の明確化
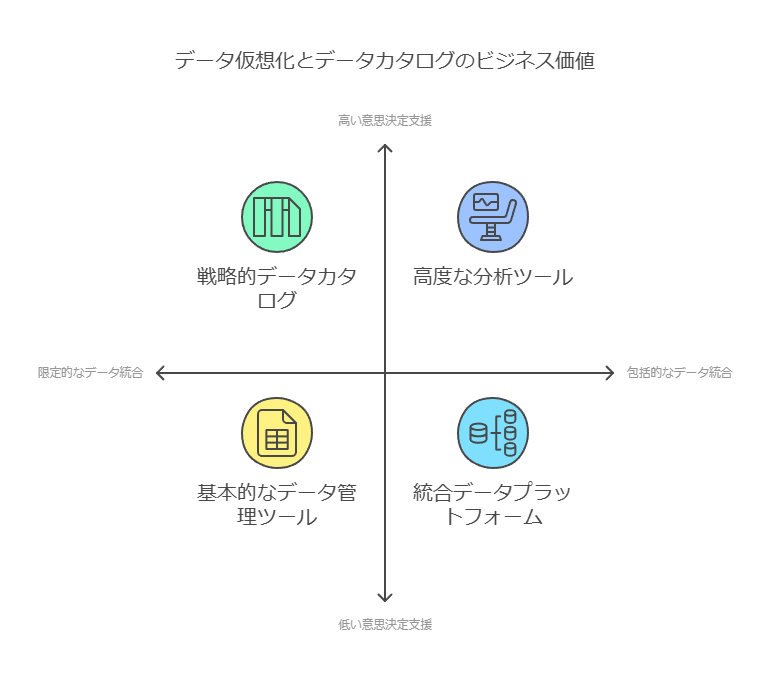
ステップ1: データ仮想化とデータカタログの重要性
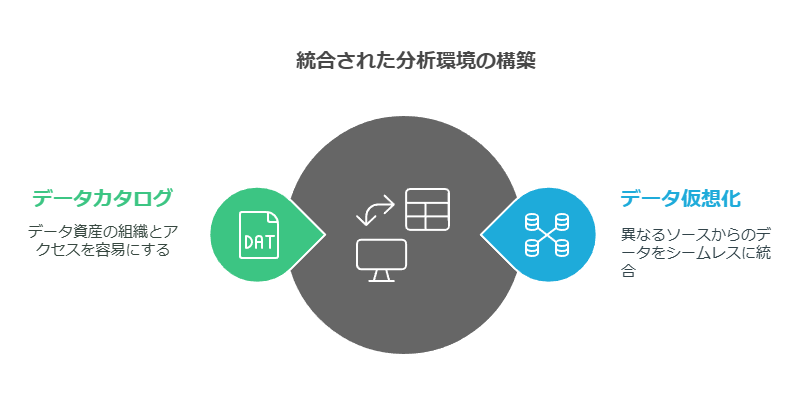
データに基づく意思決定を迅速かつ正確に行うためには、まずは統合された分析環境の整備が不可欠です。企業には様々な場所に保管された、形式も異なるデータが存在しますが、それらを必要なタイミングで活用できる環境を構築することが求められています。そこで、「データ仮想化」や「データカタログ」が重要な役割を果たします。
2. データ仮想化の効果と具体的な技術的メリットを強調する
データ仮想化がどのように企業のデータ管理を効率化し、ビジネスに貢献するかを明示します。データサイロの課題解決とコスト削減という観点から説明します。
ステップ2: データ仮想化によるデータ統合とコスト削減
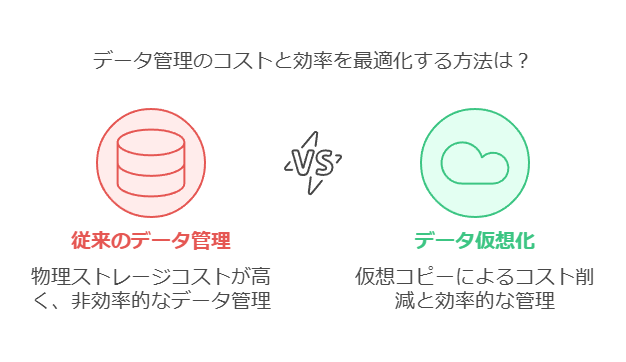
「データ仮想化」は、多様化するデータを1つの仮想的なデータソースに集約し、企業全体でデータを一貫性のある形で活用できるようにする技術です。企業には、部門ごとに独立した「データサイロ」が存在しますが、これらは一般的に他の部門やアプリケーションから隔離されています。データ仮想化ツールを使用すれば、これらのサイロを仮想的に統合し、データの一貫性を保ちながら、アプリケーション間でデータを有効に活用することが可能です。
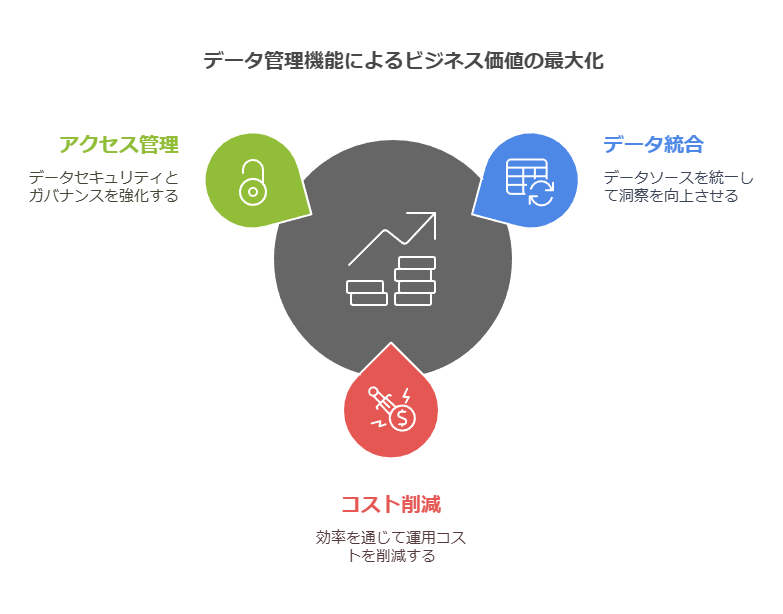
さらに、データ仮想化によりデータの「仮想コピー」が作成されるため、物理的なデータコピーを都度取得する必要がなくなり、ストレージコストの削減にも寄与します。企業は、より効率的なデータ管理を実現でき、全体的なコスト削減を図ることができます。
3. データ仮想化ツールの機能を、ビジネスニーズに応じて整理
データ仮想化ツールの具体的な機能とその利点を整理し、導入時に考慮すべきポイントを明確化します。特に、データ連携や変換、アクセス管理などの機能がどのようにビジネスに役立つかを説明します。
ステップ3: データ仮想化ツールの主な機能と導入時のポイント
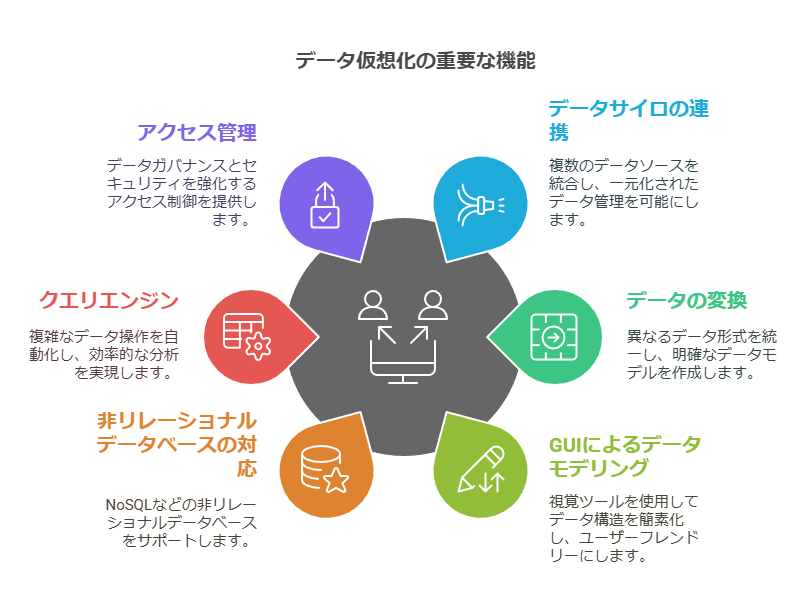
データ仮想化ツールには多様な機能がありますが、企業は自社のニーズに応じて以下の機能が必要かどうかを評価することが重要です。
データサイロの連携
複数のデータソースを統合し、企業内で一元的にデータを管理することで、部門や業務を超えたデータ活用が可能になります。
データの変換
異なる形式のデータを統一的に扱うためのデータ変換機能は、データモデルの明確化や可視化に貢献します。
GUIによるデータモデリング
プログラミングスキルがなくても、視覚的にデータ構造を整理できるため、ビジネスユーザーでもデータの利用がしやすくなります。
非リレーショナルデータベースの対応
リレーショナルデータベースに限らず、NoSQLなどの非リレーショナルデータベースを活用できる柔軟性が、現代の多様なデータソースに対応します。
クエリエンジン
複雑なデータ操作を自動化するためのクエリ生成機能は、効率的なデータ抽出と分析を実現します。
アクセス管理
データへのアクセス制限やセキュリティ管理機能により、データガバナンスとセキュリティが強化され、企業のデータ資産を守ります。
完成したデータコンサルタント視点での文章
データ活用の基盤整備: データ仮想化とデータカタログの重要性
データドリブンな意思決定を支えるためには、まず分析環境の整備が必要です。企業には、様々な場所に保存された異なる形式のデータが存在しますが、それらを迅速に統合し、必要に応じて活用するための仕組みが重要となります。ここで、注目すべき技術が「データ仮想化」や「データカタログ」です。
データ仮想化の導入効果
データ仮想化は、企業内に点在するデータサイロを仮想的に統合し、一元管理を実現します。これにより、部門間のデータ連携がスムーズになり、企業全体で一貫性のあるデータ活用が可能になります。また、データの物理的コピーを作成する必要がないため、ストレージコストの削減やデータ管理の効率化にも貢献します。
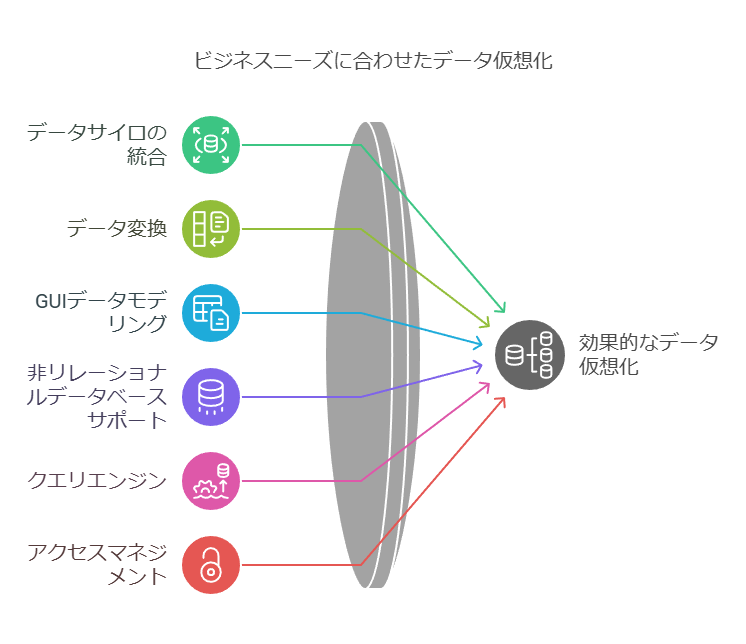
データ仮想化ツールの主な機能
データ仮想化ツールは、以下のような機能を提供し、企業のデータ活用を促進します。
データサイロの連携: 部門ごとに独立しているデータを統合し、全社で活用可能にします。
データ変換機能: 異なるデータ形式を統一的に扱い、データモデリングを容易にします。
GUIによるデータモデリング: ビジュアルなデータ管理を可能にし、専門知識がなくても利用しやすい環境を提供します。
非リレーショナルデータベース対応: 多様なデータベース形式に対応し、現代の複雑なデータ環境に柔軟に対応します。
クエリエンジン: 複雑なクエリを自動生成し、効率的なデータ分析をサポートします。
アクセス管理: セキュリティ機能を強化し、データの安全な利用を保証します。
企業はこれらの機能を活用し、効率的なデータ活用を通じてビジネス価値を最大化することができます。
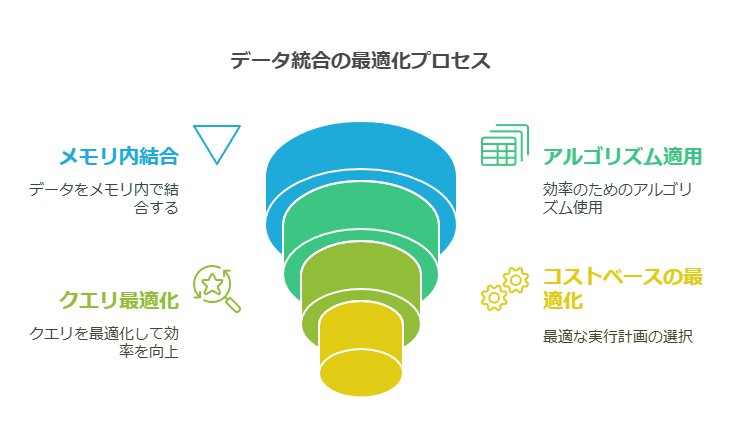
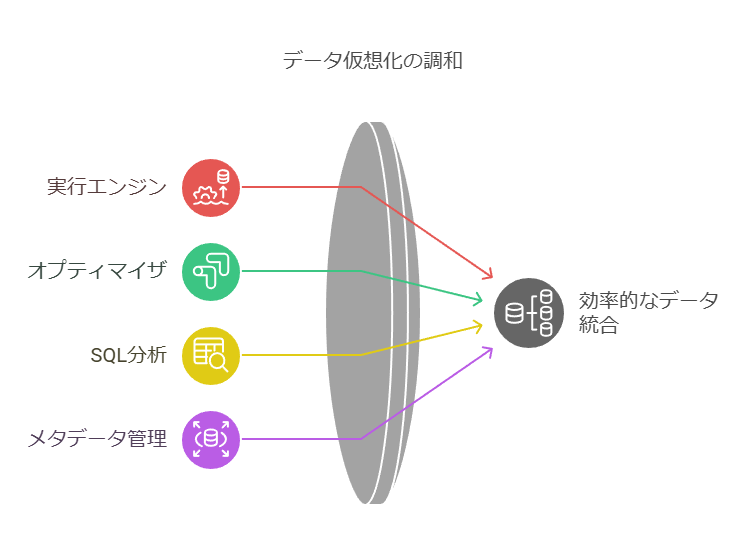
データ統合における実行エンジンと最適化の役割
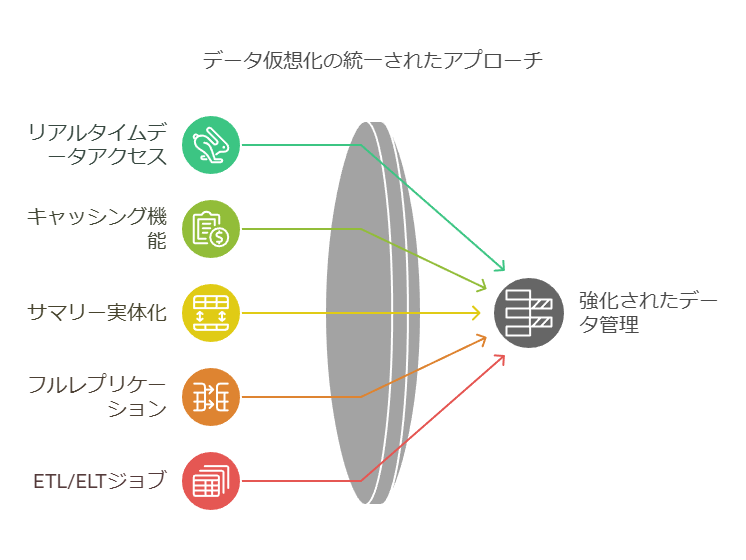
データ仮想化レイヤーで重要な役割を果たすのが、実行エンジンとそのオプティマイザです。これらは、データ取得の効率を最大化するための最適な実行計画の作成を担い、リレーショナルデータベースのエンジンに似た機能を持ちます。SQLと内部メタデータを分析してクエリ実行計画を策定する一方で、仮想レイヤーにはメタデータのみが含まれており、実際のデータはオリジナルのソース(またはキャッシュされたコピー)から取得されます。そのため、リレーショナルデータベース(RDBMS)の技術とデータ統合の論理を組み合わせる必要があります。
データが単一ソースから取得される場合、データ仮想化レイヤーは必要な言語変換を行いつつ、主要な処理は基礎となるソース側で実行します。このように、SQL以外のプロトコルの場合、データ仮想化レイヤーはAPIマネージャーのように動作し、オーバーヘッドを最小限に抑えることが可能です。
しかし、仮想化の真価が発揮されるのは、複数のデータソースが絡むケースです。この場合、リアルタイムの実行時に、データの結合や集約をメモリ内で実行するため、さまざまなアルゴリズム(ハッシュ結合、ネストループ、オンザフライでの一時テーブルへのデータ移動など)を駆使します。さらに、分岐プルーニングや部分集約分割といったクエリ最適化技術を活用し、効率を高めます。特に、コストベースのオプティマイザは、処理ボリュームの見積もりを基に各オプションのパフォーマンスを評価し、最適な実行計画を選択する際に重要な役割を担います。
高度なデータ仮想化エンジンは、リアルタイムのデータアクセスに加え、キャッシングやサマリーの選択的実体化といったパフォーマンス向上機能も備えています。フルレプリケーションもサポートしており、要件に応じてETL/ELTジョブを実行することが可能です。
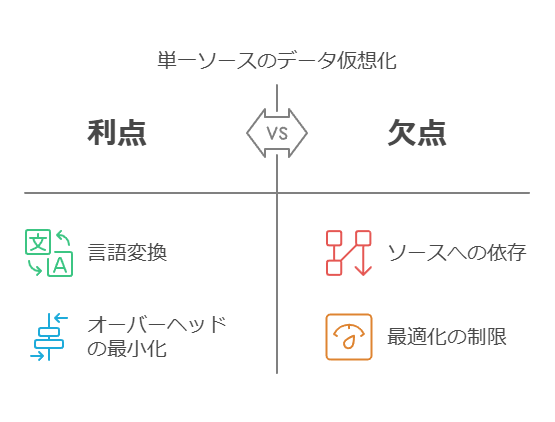
データ仮想化が実現する、次世代データ統合戦略
データ仮想化は、従来の物理的なデータ統合(ETL/ELT)とは一線を画す、論理的なデータ統合アプローチです。データを物理的に移動・複製して一箇所に集約するのではなく、データが格納されている元のソースシステムに置いたまま、それらを仮想的に統合し、リアルタイムで統一されたビューとして提供します。
データ仮想化が提供する戦略的価値
データ活用の現場では、データのサイロ化、開発の遅延、増大するインフラコストといった課題が常に存在します。データ仮想化は、これらの課題を解決するための具体的なソリューションを提供します。
圧倒的な俊敏性(Agility)の獲得:
物理的なデータパイプラインの開発を必要としないため、ビジネス要件の変化や新たなデータソースの追加に対して、数週間から数ヶ月かかっていた対応を、数日あるいは数時間単位で完了させることが可能です。これにより、ビジネスのスピードに即応したデータ提供を実現します。
TCO(総所有コスト)の削減:
データの複製を最小限に抑えることで、データウェアハウス(DWH)やデータマートのための高価なストレージコストを大幅に削減します。また、ETL処理の開発・運用・保守にかかる工数を削減し、ITリソースをより価値の高い業務へシフトさせることができます。
データガバナンスとセキュリティの一元化:
仮想レイヤーにアクセス制御、マスキング、監査ログなどのセキュリティポリシーを集約できます。これにより、データソースごとに個別対応する必要がなくなり、エンタープライズレベルでの一貫したデータガバナンスを効率的に実現します。
真のセルフサービスデータ活用:
データアナリストやビジネスユーザーは、データの物理的な場所やフォーマット(構造化、非構造化など)を意識する必要がありません。使い慣れたBIツールやアプリケーションから、統一された仮想レイヤーに接続するだけで、必要なデータをオンデマンドで取得・分析できます。
アーキテクチャの核心:「抽象化レイヤー」
データ仮想化の技術的な中核は、データソースとデータを利用するアプリケーションやユーザーとの間に設置される「抽象化レイヤー(論理データレイヤー)」です。
このレイヤーは、各データソースへの接続情報やデータ構造を定義したメタデータのみを保持します。ユーザーからのクエリ(データ要求)を受け取ると、メタデータに基づいて最適な実行計画をリアルタイムで策定し、各データソースから必要なデータのみを取得・結合して結果を返します。データそのものを保持しないため、システムは極めて軽量かつ柔軟に機能します。
このアーキテクチャにより、オンプレミスやクラウド、リレーショナルデータベースや非構造化データストアといった多様な環境に散在するデータを、あたかも単一のデータベースであるかのように見せることが可能になります。
高度な機能によるパフォーマンス最適化
データ仮想化は、単にデータを仲介するだけではありません。インテリジェントな機能により、リアルタイム処理におけるパフォーマンスを最大化します。
クエリオプティマイザ: 実行計画をリアルタイムで最適化し、データソースの特性やネットワーク状況を考慮して、最も効率的なデータ取得・結合処理を実行します。
インテリジェントキャッシングとインメモリ処理: 頻繁にアクセスされるデータや、処理に時間のかかるクエリ結果をキャッシュすることで、ソースシステムへの負荷を軽減し、ユーザーへのレスポンス速度を劇的に向上させます。
多様な接続性: 標準的なSQLだけでなく、API(REST/OData等)経由でのデータ提供も可能です。これにより、分析用途だけでなく、業務アプリケーションとのデータ連携基盤としても機能します。
結論:データ活用のパラダイムシフト
データ仮想化は、単なる既存のデータ統合手法の置き換えではありません。これは、変化し続けるビジネス環境において、データの価値を迅速かつ最大限に引き出すための戦略的なデータアーキテクチャです。既存のDWHやデータレイクを補完し、あるいはそれらを発展的に置き換えることで、より柔軟でコスト効率の高いデータプラットフォームを構築し、企業のデータドリブン経営を強力に推進します。
データ仮想化の適用領域とソリューション選定の視点
データ仮想化は、単一の論理レイヤーを通じて、社内外に散在するあらゆるデータへの統一されたアクセスポイントを提供します。このアーキテクチャは、データガバナンスの観点から極めて重要です。仮想レイヤーを介してデータアクセスを一元管理することで、データの冗長性や不整合といった品質問題を早期に発見し、エンタープライズ全体で一貫したセキュリティ制御とアクセス管理を適用することが可能になります。
データ仮想化の限界と現実的な導入アプローチ
一方で、データ仮想化にも不得意な領域が存在します。それは、物理的な大規模データ転送を前提とするETLのような、夜間バッチ処理です。データ仮想化はリアルタイムなデータアクセスを得意としますが、テラバイト級のデータを一括で移動・複製するようなユースケースには最適ではありません。
このような要件が存在する場合、データ仮想化がETLを完全に置き換えるのではなく、両者を共存させるハイブリッドなアーキテクチャが現実的かつ効果的な解決策となります。例えば、基幹システムのデータをDWHに連携する部分は従来のETLを用い、DWHとその他のリアルタイム性が求められるデータを組み合わせて分析する部分にデータ仮想化を活用する、といった使い分けが考えられます。
目的別に見るデータ仮想化ソリューションの5つのレベル
「データ仮想化」という言葉が指し示す機能や性能は、ソリューションによって大きく異なります。特定のツールに組み込まれた限定的な機能から、エンタープライズ全体のデータ基盤となり得る包括的なプラットフォームまで様々です。ここでは、その機能と適用範囲に応じてソリューションを5つのレベルに分類し、自社の目的に合った製品を選定するための視点を提供します。
レベル1:データブレンディング機能(BIツール内蔵型)
BIツールの多くは、複数のデータソースをレポート上で組み合わせる「データブレンディング」機能を提供します。これはデータ仮想化のコンセプトの一端を担うものですが、その利用は特定のBIツール内に限定されます。
主な用途: アナリスト個人や特定部門による、アドホックなレポート作成。
制約: 作成されたデータセットは他のアプリケーションから再利用できず、全社的なガバナンスの適用が困難です。
レベル2:データサービスモジュール(既存製品の拡張機能)
多くのデータ統合(ETL)ツールやDWHベンダーが、アドオンとしてデータ仮想化機能を提供しています。
主な用途: 既存のETL/MDMプロセスの補完や、データ統合のプロトタイピング。
制約: 多くはETL処理の補完として設計されており、高度なクエリ最適化、リアルタイムキャッシュ、多様な非構造化データへの対応といった点で、専門のプラットフォームには及びません。
レベル3:「SQL on X」製品(特定領域特化型)
ビッグデータやHadoopエコシステム上で、SQLによるデータアクセスを可能にするソリューションです。
主な用途: 特定のビッグデータ基盤(データレイク等)に格納されたデータと、一部のリレーショナルデータベース等を組み合わせた分析。
制約: ビッグデータ技術スタックに最適化されている反面、それ以外の多様なエンタープライズデータソースを網羅的に扱う汎用性には欠けます。
レベル4:クラウドデータサービス(クラウド連携特化型)
主にクラウド環境での利用を前提とし、SaaSアプリケーションやクラウドDB間のデータ連携を容易にするサービスです。
主な用途: 中規模プロジェクトにおける、クラウド中心のデータ統合。
制約: 正規化されたAPIを提供し、迅速な連携を実現しますが、オンプレミスの基幹システム、メインフレーム、大規模な非構造化データなどを扱う複雑なエンタープライズ要件への対応は困難な場合があります。
レベル5:データ仮想化プラットフォーム(エンタープライズ基盤型)
エンタープライズ環境において、多様なデータソースと多様なデータ利用者を「多対多」で結びつける、論理的なデータ統合レイヤーを構築するために専用設計されたソリューションです。
主な用途: 全社的なデータハブ、論理データウェアハウス(LDW)、データファブリックの中核としての利用。
特徴: 高度なクエリ最適化、パフォーマンス、セキュリティ、ガバナンス機能を網羅し、あらゆるデータとユーザーに対して高速かつ俊敏なデータアクセスを提供します。
まとめ
データ仮想化ソリューションの選定においては、単機能の比較だけでなく、自社が解決したい課題と将来のデータ戦略に照らし合わせ、どのレベルのソリューションが最適かを見極めることが成功の鍵となります。
データ仮想化がもたらすビジネス価値:評価すべき10の視点
データ仮想化プラットフォームは、既存のデータ統合ソリューションを補完、あるいは刷新する強力なアプローチです。その導入効果は多岐にわたりますが、ここでは特にデータ戦略を推進する上で評価すべき10の視点を、ビジネスインパクトの観点から解説します。
【戦略・経済的インパクト】
1. 驚異的な投資対効果(ROI)と開発生産性の向上
データ仮想化プロジェクトは、一般的に導入から6ヶ月以内という短期間での投資回収が報告されています。物理的なデータパイプラインの開発を不要とすることで、従来の統合手法と比較して50%から80%もの工数削減を実現します。これは単なるコスト削減に留まらず、ビジネスの要求に迅速に応える「市場投入時間(Time-to-Market)」の短縮に直結します。
2. TCO(総所有コスト)の抜本的削減
従来のデータ統合では、データの複製・移動・保管が繰り返されるため、高価なストレージコストやETL処理の運用コストが増大し続けます。データ仮想化は、データを物理的に移動させない「論理データレイヤー」を提供するため、これらのデータレプリケーションに伴うコストを原理的に排除します。
3. アジャイルな開発とリスクの低減
データ仮想化は、本格的な開発に着手する前に、仮想的なデータモデルを用いて迅速にプロトタイピングを行うことを可能にします。ビジネス要件の検証やデータ活用のPoC(概念実証)を素早く実行できるため、手戻りを防ぎ、開発リスクを大幅に低減させながら、より柔軟なプロジェクト推進を実現します。
4. データ活用の民主化とビジネス部門の自律性向上
ビジネスユーザーが必要なデータを、IT部門を介さずに直接、かつ安全に探索・利用できるセルフサービス環境を構築します。これにより、データに基づいた問いを立て、自ら答えを見つけ出すサイクルが加速し、組織全体のデータリテラシーと意思決定の質が向上します。
【業務・運用インパクト】
5. リアルタイムな意思決定とデータ鮮度の最大化
ETL処理のように、データの抽出・加工・ロードに数時間から数日を要するプロセスでは、意思決定の時点ですでにデータが古くなっているという課題がありました。データ仮想化は、データソースを直接参照するため、常に最新のデータに基づいたリアルタイムなインサイトを提供し、ビジネス機会の損失を防ぎます。
6. 一元的なデータガバナンスとセキュリティ統制の実現
エンタープライズ環境に散在するあらゆるデータソースへのアクセスポイントを、仮想レイヤーに集約します。これにより、誰が・いつ・どのデータにアクセスしたかという監査証跡の取得や、項目レベルでのアクセス制御、マスキングといったセキュリティポリシーを一元的に適用でき、堅牢なデータガバナンス体制を効率的に構築できます。
7. 既存IT資産(データウェアハウス等)の価値最大化
データ仮想化は、既存のデータウェアハウス(DWH)やデータレイクを置き換えるだけのものではありません。むしろ、これらの既存資産と連携し、そこに格納されたデータと、他のシステムにあるリアルタイムデータなどを柔軟に組み合わせることで、既存投資を保護しながらデータ活用の範囲を拡張し、その価値を最大化します。
【技術的インパクト】
8. 先進的なアナリティクス基盤の構築
ビッグデータ、IoTデータ、クラウド上のSaaSデータなど、日々増え続ける多種多様なデータを、予測分析や機械学習モデルで利用可能な形式にオンデマンドで統合・整形します。データ準備にかかる時間を短縮し、データサイエンティストがより高度な分析業務に集中できる環境を提供します。
9. 次世代データ統合アーキテクチャへの進化
データ仮想化は、単なるデータ連携技術の寄せ集めではありません。10年以上の実績を持つ安定した技術を基盤としながらも、インテリジェントなクエリ最適化、データカタログによるセルフサービスでのデータ探索機能などを提供し、従来のデータ統合の概念を超える、柔軟で拡張性の高いアーキテクチャを実現します。
10.(視点の再定義)論理データファブリックの中核としての役割
データ仮想化は、組織内のあらゆるデータ消費者とデータソースを、場所や形式を問わずにインテリジェントに結びつける「論理データファブリック」構想の中核を担う技術です。これにより、データはサイロから解放され、組織全体で柔軟かつ統制の取れたデータ活用が可能になります。
データ仮想化とデータ整理:分散データをつなぐ次世代のIT戦略
企業のデータ活用が高度化する中で、「データ仮想化(Data Virtualization)」という技術が注目を集めています。これは、物理的に異なる場所に存在するデータを、あたかも一つの場所にあるかのように扱える仕組みであり、データ統合や分析の柔軟性を大きく高めるものです。
しかし、どれほど高度な仮想化技術を導入しても、元となるデータが整理されていなければ、正確な分析や意思決定にはつながりません。そこで重要になるのが、「データ整理」と「データマネジメント」の取り組みです。
この記事では、データ仮想化の基本と整理の必要性、そして最近のITトレンドと連動した実践的なアプローチについて解説します。
データ仮想化とは?
データ仮想化とは、複数の異なるデータソース(例:クラウド、オンプレミス、データベース、ファイルサーバーなど)に分散して存在するデータを、物理的に移動させることなく、統合的にアクセス・操作できる技術です。
従来のデータ統合では、ETL(Extract, Transform, Load)処理を通じてデータを一か所に集める必要がありましたが、データ仮想化ではリアルタイムに各ソースへアクセスし、必要な情報だけを取得できます。
主なメリットは以下の通りです:
データの複製や移動が不要なため、コストと時間を削減できる
リアルタイム性が高く、最新の情報に基づいた意思決定が可能
データソースの追加・変更に柔軟に対応できる
なぜ「データ整理」が不可欠なのか?
データ仮想化は、あくまで「データへのアクセス方法」を変える技術です。つまり、仮想化によって見えるデータが重複していたり、意味が不明確だったり、品質にばらつきがある場合、分析結果も信頼できないものになってしまいます。
そのため、以下のようなデータ整理の取り組みが不可欠です。
メタデータの整備:データの意味、出所、更新履歴などを明確にする
マスターデータの統一:顧客IDや商品コードなどの基幹情報を標準化する
データ品質の管理:重複、欠損、誤記などを検出・修正する
分類とタグ付け:業務や用途ごとにデータを整理し、検索性を高める
これらを通じて、仮想化されたデータが「使える状態」に整い、業務効率や分析精度が大きく向上します。
最近のITトレンドとデータ仮想化の進化
2026年現在、データ仮想化は単なるデータ統合手段にとどまらず、さまざまなITトレンドと連携しながら進化を遂げています。
1. ハイブリッドクラウドとマルチクラウド対応
多くの企業がオンプレミスとクラウドを併用するハイブリッド環境や、複数のクラウドサービスを使い分けるマルチクラウド戦略を採用しています。データ仮想化は、これらの環境にまたがるデータを一元的に扱えるため、柔軟なIT基盤の構築に貢献します。
2. データファブリックとの融合
データファブリックは、企業全体のデータを仮想的に統合し、ユーザーが一貫した形でアクセスできるようにするアーキテクチャです。データ仮想化はその中核技術として位置づけられており、部門間の壁を越えたデータ活用を可能にします。
3. 生成AIによるメタデータ自動生成
生成AIを活用して、非構造化データの内容を自動で解析し、メタデータを付与する技術が進化しています。これにより、仮想化されたデータの意味づけが容易になり、検索性や再利用性が向上します。
4. データガバナンスとセキュリティの強化
GDPRや日本の個人情報保護法などの法規制に対応するため、データ仮想化環境でもアクセス制御や監査ログの整備が求められています。整理されたデータは、こうしたガバナンス体制の構築にも不可欠です。
企業が取り組むべきステップ
データ仮想化とデータ整理を両立させるために、企業が実践すべきステップは以下の通りです。
データ資産の棚卸し:どの部門がどのようなデータを保有しているかを可視化
メタデータ管理の導入:データの意味や出所を明確にし、再利用性を高める
マスターデータの整備:基幹情報を標準化し、部門間での整合性を確保
仮想化ツールの選定と導入:Denodo、TIBCO、IBM Cloud Pakなどのツールを検討
継続的な品質管理とガバナンス:データの正確性や整備状況を定期的に見直す
これらの取り組みを通じて、企業はデータ仮想化を活用した俊敏な意思決定と、全社的なデータ活用の高度化を実現できます。
日本企業における「データ仮想化」と「データ整理」:分散データを活かす次世代の情報戦略
日本企業では近年、DX(デジタルトランスフォーメーション)の推進に伴い、社内外に分散するデータの統合と活用が大きな課題となっています。営業、製造、マーケティング、経理など、部門ごとに異なるシステムを運用している企業も多く、データのサイロ化が進行しやすい状況です。
こうした中で注目されているのが、「データ仮想化(Data Virtualization)」という技術です。これは、物理的に異なる場所にあるデータを、あたかも一つの場所にあるかのように扱える仕組みであり、データ統合の柔軟性を大きく高めるものです。
しかし、どれほど高度な仮想化技術を導入しても、元となるデータが整理されていなければ、正確な分析や意思決定にはつながりません。そこで重要になるのが、「データ整理」と「データマネジメント」の取り組みです。
データ仮想化とは?国内企業での導入背景
データ仮想化とは、複数の異なるデータソース(例:オンプレミスの基幹システム、クラウドサービス、Excelファイルなど)に分散して存在するデータを、物理的に移動させることなく、統合的にアクセス・操作できる技術です。
日本企業では、以下のような背景からデータ仮想化の導入が進んでいます。
社内に複数の業務システムが存在し、データが分断されている
クラウドとオンプレミスが混在するハイブリッド環境が一般的になっている
データ統合のためのETL開発に時間とコストがかかっている
リアルタイムでのデータ活用ニーズが高まっている
特に、製造業や金融業、流通業などでは、複数拠点や部門をまたぐデータ連携が求められる場面が多く、仮想化による柔軟な統合が注目されています。
なぜ「データ整理」が不可欠なのか?
データ仮想化は、あくまで「データへのアクセス方法」を変える技術です。つまり、仮想化によって見えるデータが重複していたり、意味が不明確だったり、品質にばらつきがある場合、分析結果も信頼できないものになってしまいます。
そのため、以下のようなデータ整理の取り組みが不可欠です。
メタデータの整備:データの意味、出所、更新履歴などを明確にする
マスターデータの統一:顧客IDや商品コードなどの基幹情報を標準化する
データ品質の管理:重複、欠損、誤記などを検出・修正する
分類とタグ付け:業務や用途ごとにデータを整理し、検索性を高める
これらを通じて、仮想化されたデータが「使える状態」に整い、業務効率や分析精度が大きく向上します。
国内で進むITトレンドとデータ仮想化の進化
2026年現在、日本国内では以下のようなITトレンドがデータ仮想化の活用と整理を後押ししています。
1. ハイブリッドクラウドとマルチクラウドの普及
多くの企業がオンプレミスとクラウドを併用するハイブリッド環境を採用しており、AWSやAzure、Google Cloudなど複数のクラウドサービスを使い分けるケースも増えています。データ仮想化は、これらの環境にまたがるデータを一元的に扱えるため、柔軟なIT基盤の構築に貢献します。
2. データファブリックとの融合
データファブリックは、企業全体のデータを仮想的に統合し、ユーザーが一貫した形でアクセスできるようにするアーキテクチャです。データ仮想化はその中核技術として位置づけられており、部門間の壁を越えたデータ活用を可能にします。
3. 生成AIによるメタデータ自動生成
ChatGPTのような生成AIを活用して、非構造化データの内容を自動で解析し、メタデータを付与する技術が進化しています。これにより、仮想化されたデータの意味づけが容易になり、検索性や再利用性が向上します。
4. データガバナンスと法令対応の強化
日本の個人情報保護法やマイナンバー制度など、法令遵守の観点からも、データの取り扱いルールやアクセス制御の整備が求められています。データ仮想化においても、暗号化や監査ログの管理が重要です。
日本企業が取り組むべきステップ
データ仮想化とデータ整理を両立させるために、日本企業が実践すべきステップは以下の通りです。
データ資産の棚卸し:どの部門がどのようなデータを保有しているかを可視化
メタデータ管理の導入:データの意味や出所を明確にし、再利用性を高める
マスターデータの整備:基幹情報を標準化し、部門間での整合性を確保
仮想化ツールの選定と導入:Denodo、TIBCO、IBM Cloud Pakなどのツールを検討
継続的な品質管理とガバナンス:データの正確性や整備状況を定期的に見直す
これらの取り組みを通じて、日本企業はデータ仮想化を活用した俊敏な意思決定と、全社的なデータ活用の高度化を実現できます。
海外企業が進める「データ仮想化」と「データ整理」:分散データを統合するグローバル戦略
グローバル市場では、企業が扱うデータの量と種類が急増しており、複数の拠点やクラウド環境にまたがるデータの統合と活用が大きな課題となっています。こうした中で注目されているのが、「データ仮想化(Data Virtualization)」という技術です。
データ仮想化は、物理的に異なる場所にあるデータを、あたかも一つの場所にあるかのように扱える仕組みであり、リアルタイム性と柔軟性を兼ね備えたデータ統合手法として、海外の大手企業を中心に導入が進んでいます。
しかし、仮想化されたデータが整理されていなければ、正確な分析や意思決定にはつながりません。そこで重要になるのが、「データ整理」と「データマネジメント」の取り組みです。
データ仮想化とは?海外企業での導入背景
データ仮想化とは、複数の異なるデータソース(オンプレミス、クラウド、SaaS、IoTデバイスなど)に分散して存在するデータを、物理的に移動させることなく、統合的にアクセス・操作できる技術です。
米国や欧州のグローバル企業では、以下のような理由からデータ仮想化の導入が進んでいます。
多国籍拠点から発生するデータをリアルタイムで統合したい
クラウドとオンプレミスが混在する環境で柔軟にデータを扱いたい
データウェアハウスへのETL処理にかかる時間とコストを削減したい
AIやBIツールによる分析を迅速に行いたい
特に、製薬、金融、通信、エネルギーなどの業界では、複雑なデータ環境を効率よく統合する手段として、データ仮想化が不可欠な存在となっています。
なぜ「データ整理」が不可欠なのか?
データ仮想化は、あくまで「データへのアクセス方法」を変える技術です。つまり、仮想化によって見えるデータが重複していたり、意味が不明確だったり、品質にばらつきがある場合、分析結果も信頼できないものになってしまいます。
そのため、以下のようなデータ整理の取り組みが不可欠です。
メタデータの整備:データの意味、出所、更新履歴などを明確にする
マスターデータの統一:顧客IDや製品コードなどの基幹情報を標準化する
データ品質の管理:重複、欠損、誤記などを検出・修正する
分類とタグ付け:業務や用途ごとにデータを整理し、検索性を高める
これらを通じて、仮想化されたデータが「使える状態」に整い、業務効率や分析精度が大きく向上します。
海外で進むITトレンドとデータ仮想化の進化
2026年現在、海外では以下のようなITトレンドがデータ仮想化の活用と整理を支えています。
1. データファブリックとデータメッシュの融合
米国や欧州の大手企業では、データファブリック(全社横断の仮想データ統合基盤)やデータメッシュ(ドメインごとの分散管理と標準化)といったアーキテクチャが注目されています。データ仮想化は、これらの基盤を支える中核技術として活用されています。
2. 生成AIによるメタデータ生成と分類
生成AIを活用して、非構造化データ(文書、画像、音声など)の内容を自動で解析し、メタデータを付与する技術が進化しています。これにより、仮想化されたデータの意味づけが容易になり、検索性や再利用性が向上しています。
3. ハイブリッド・マルチクラウド対応の加速
多くのグローバル企業が、AWS、Azure、Google Cloudなど複数のクラウドサービスを併用しており、データ仮想化はそれらを横断的に統合する手段として活用されています。これにより、各地域の法規制やインフラ事情に応じた柔軟なデータ戦略が可能になります。
4. データガバナンスとコンプライアンスの強化
GDPR(EU一般データ保護規則)やCCPA(カリフォルニア州消費者プライバシー法)など、各国の法規制に対応するため、データの取り扱いルールやアクセス制御の整備が求められています。データ仮想化環境でも、暗号化、監査ログ、ポリシー管理などの機能が強化されています。
海外企業が取り組むべきステップ
データ仮想化とデータ整理を両立させるために、海外企業が実践しているステップは以下の通りです。
データ資産の棚卸し:どの拠点・部門がどのようなデータを保有しているかを可視化
メタデータ管理の導入:データの意味や出所を明確にし、再利用性を高める
マスターデータの整備:基幹情報を標準化し、部門間での整合性を確保
仮想化ツールの選定と導入:Denodo、TIBCO、IBM Cloud Pakなどのツールを活用
継続的な品質管理とガバナンス:データの正確性や整備状況を定期的に見直す
これらの取り組みを通じて、海外企業はデータ仮想化を活用した俊敏な意思決定と、グローバルなデータ戦略の実現を目指しています。