
目次
- 1 データコンサルタントの視点で、ビッグデータ活用の価値とその成功要因を強調し、具体的なアクションプランを提示
- 2 データ戦略の視点からビッグデータの収集方法
- 3 ビッグデータの収集方法
- 4 ビッグデータのパイプラインは、複数のステップに分かれており、それぞれのステップで異なる技術が使用されることがあります。
- 5 一時的なワークロードをクラウドに移行することでコストを最適化することは、多くの企業にとって効果的な戦略です。
- 6 クラウドにおけるビッグデータワークロードの最適化
- 7 モダンなデータアーキテクチャ: データとアナリティクスの活用
- 8 クラウド環境とオンプレミス間のデータ移動の最適化
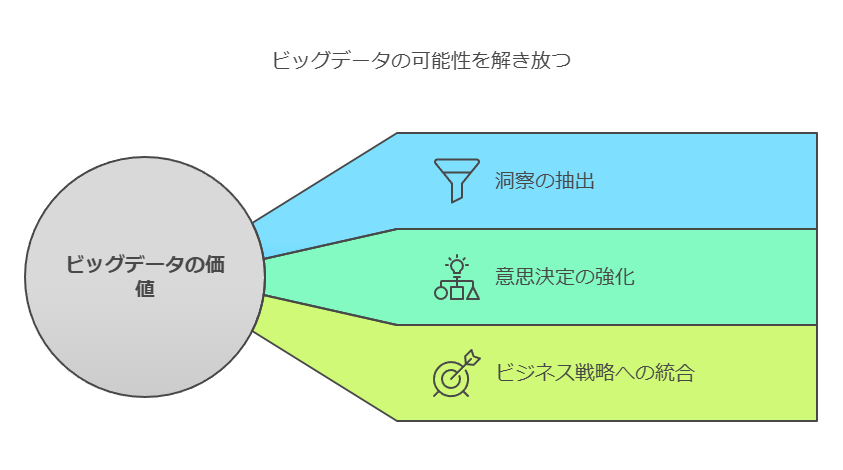
- 9 ビッグデータの価値は「量」ではなく「正しい意思決定」を引き出す能力にある
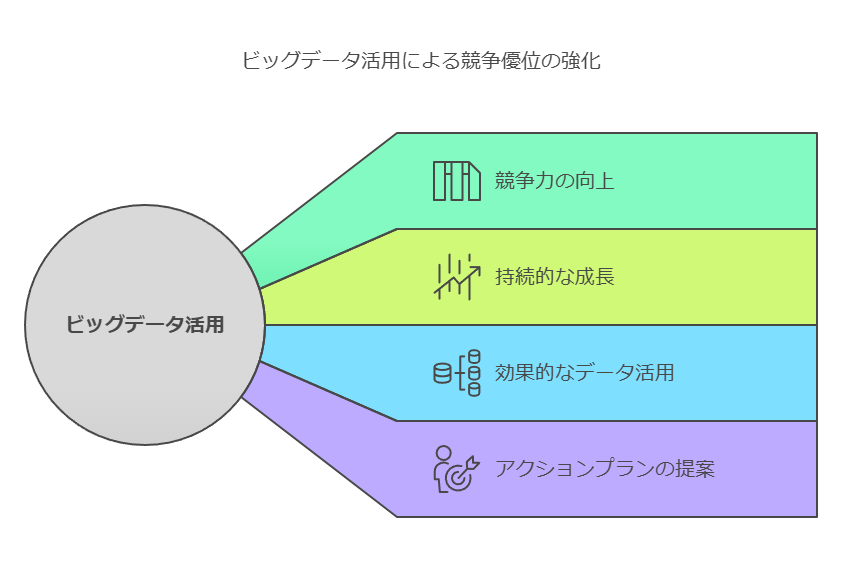
データコンサルタントの視点で、ビッグデータ活用の価値とその成功要因を強調し、具体的なアクションプランを提示
ビッグデータの真の価値は量ではなく、意思決定への影響力にある
ビッグデータを活用してビジネスにおける「正しい意思決定」を引き出すためには、データの収集と分析を効果的に行う仕組みが不可欠です。単に膨大なデータを所有しているだけでは、ビジネス成果を生むことはできません。では、企業はどのようにしてビッグデータの活用を成功に導けばよいのでしょうか?
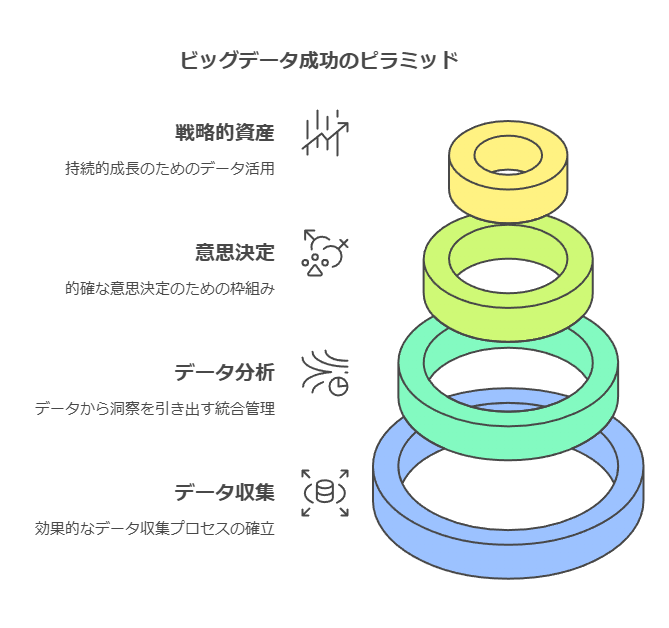
データを活かすための出発点:効果的なデータ収集と分析基盤の構築
データが企業の価値資産として機能するためには、収集したデータが的確な意思決定を支えるものでなければなりません。2021年に在る会社が実施した調査では、回答企業の99%がビッグデータの活用に注力しており、96%がAI技術を使ったデータ分析がビジネスのパフォーマンスに貢献していると回答しています。これに加えて、企業の約9割程度がビッグデータ関連の投資を増加させ、81%がAIを活用したさらなる分析に前向きな姿勢を示しています。
しかし、こうしたデータ活用を成功させるためには、「準備段階の整備」が極めて重要です。企業は膨大なデータを持つだけではなく、そのデータをどのように効果的に収集し、どの意思決定に繋げるかを明確にする必要があります。
量ではなく質が鍵:価値を引き出すためのデータ基盤の整備
ビッグデータの価値は、その量に依存するのではなく、どれだけ効果的に意思決定に役立てられるかにかかっています。経営層はデータを単なる情報として捉えるのではなく、そこから洞察を引き出し、ビジネス戦略に応用するためのツールとして活用することが求められます。
企業はデータが自社のビジネスにどのように貢献するかをしっかりと定義した上で、ビッグデータ活用に投資するべきです。膨大で多様なデータの中から「価値」を引き出すためには、まずデータの効果的な収集基盤を整えることが必要だと言われております。
実際に企業が直面する課題と対策
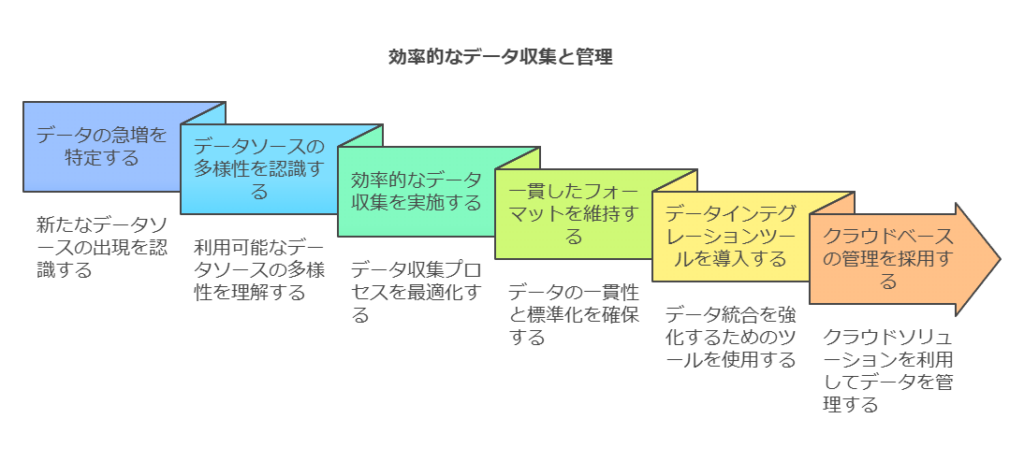
データの収集と準備:データの量が急増し、IoTやAIの導入により多様なデータソースが生まれています。これらを効率的に収集し、一貫性のあるフォーマットで管理することが重要です。データインテグレーションツールの導入や、クラウド基盤でのデータ管理が推奨されます。
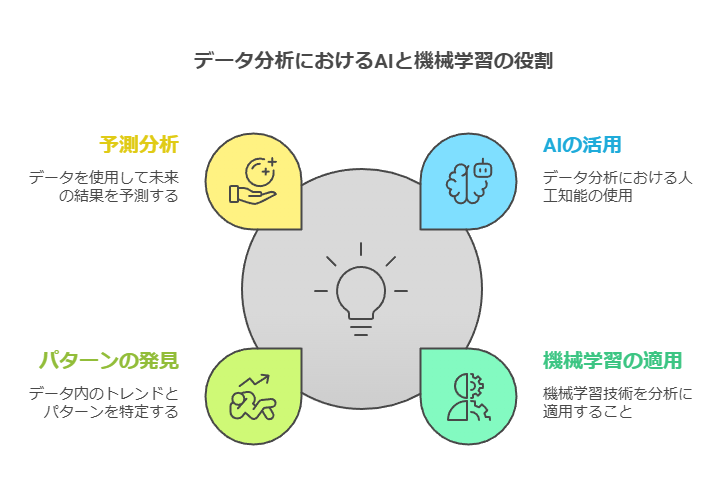
データの有効活用:収集されたデータをどのように分析に結びつけるかが鍵です。AIや機械学習を活用し、パターンの発見や予測分析を行うことで、データの潜在的な価値を引き出します。ここでは、ビジネス目標に即した分析のアプローチを定めることが重要です。
意思決定への反映:最終的に、データ分析によって得られたインサイトを、迅速かつ効果的に意思決定に組み込む体制が必要です。ビジネスリーダーがリアルタイムにデータを活用できるよう、ダッシュボードやレポートツールの整備を進めるべきです。
まとめ:ビッグデータ活用を成功に導くために
企業がビッグデータを活用して成功するためには、単にデータの量を追求するのではなく、そのデータから的確な意思決定を引き出すための仕組みを整えることが重要です。効果的なデータ収集、分析、意思決定のプロセスを統合的に管理することで、ビッグデータは企業にとっての「戦略的資産」として機能し、持続的な成長を支える力となるでしょう。
データ戦略の視点からビッグデータの収集方法
データ収集は決して新しい概念ではありません。人類は何千年にもわたり、さまざまな情報を集め、生活やビジネスに役立ててきました。しかし、現代では、データの量、種類、そして生成速度が劇的に増加し、これがいわゆるビッグデータという規模にまで発展しています。今日では、世界中で毎日膨大なデータが生成され、企業にとっては、このデータを適切に収集し、管理し、活用することが競争優位性を保つための鍵となっています。
現代のデータ形式とその分類
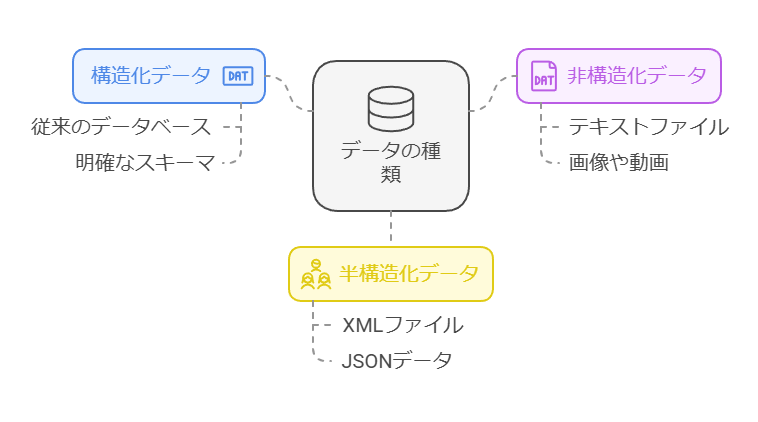
ビッグデータは、一般的に以下の3つの形式に分類されます。これらの形式を正確に理解し、それぞれの特性に応じた収集と分析を行うことが重要です。
構造化データ
例えば、クレジットカード番号やGPS座標など、規則的なフォーマットに基づき、数値や文字列として扱われるデータです。このデータは明確な形式を持ち、従来のデータベースに格納され、容易に検索や整理が可能です。
非構造化データ
メールやソーシャルメディアの投稿のように、事前に定められた形式を持たないデータです。テキスト、画像、ビデオなどがこれに該当し、膨大な量の情報が含まれていますが、その分析には高度な技術が求められます。
半構造化データ
これは構造化データと非構造化データが混在したデータです。例えば、JSONやXMLのようなデータ形式が該当します。柔軟性が高い一方で、特定の部分が明確に整理されていないため、扱いが難しいケースもあります。
データソースの特定と選定
企業がビッグデータを収集する際には、まずどのデータソースを活用するかを明確にする必要があります。一般的なデータソースには次のようなものが含まれます。
取引データ(POSシステムなど):販売時点情報を管理するシステムは、リアルタイムの取引データを収集するために不可欠です。
IoTデバイス:センサーやスマートデバイスから収集されるデータは、リアルタイムで膨大な情報を提供します。
マーケティング企業や調査会社のデータ:企業が外部から購入できる市場データや顧客インサイトを提供します。
ソーシャルメディア:顧客の意見やフィードバックが投稿されるSNSは、消費者行動やトレンドを把握するための有力なデータソースです。
位置情報データ:スマートフォンなどから取得できるリアルタイムの位置情報も、重要な分析データとなります。
データ収集の目的と戦略の明確化
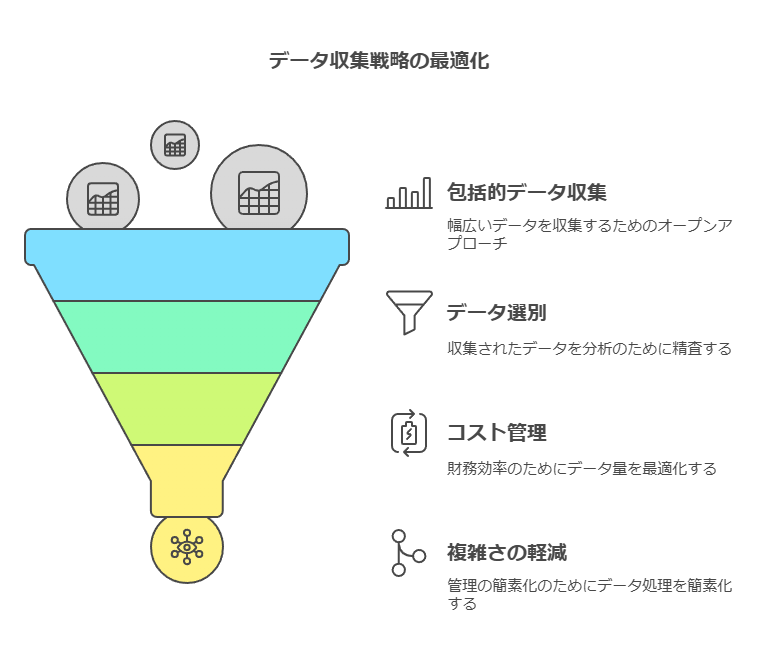
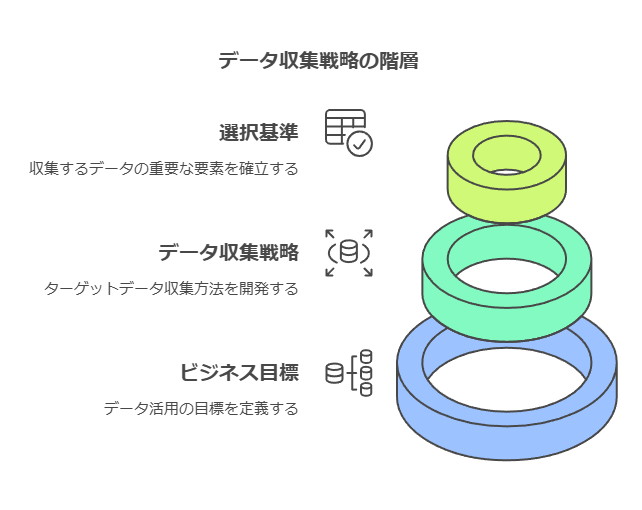
すべてのデータを無差別に収集しても、企業にとって有益な洞察を得られるとは限りません。むしろ、膨大なデータが持つコスト負担や個人情報保護のリスクを考慮し、戦略的にデータを収集する必要があります。企業は、まず自社のビジネス目的に合致するデータ活用のゴールを明確にし、その目標に基づいてデータ収集戦略を策定すべきです。
データ活用の目的を定める:ビジネスのどの側面を強化したいのか(例えば、顧客満足度向上や業務効率化)をまず設定します。
必要なデータを選別する:目的に応じて、どのデータが必要かを選定し、無駄なデータ収集を避けることで、コストや管理負担を軽減します。
ある専門家は、「革新的なデータ活用を実現するためには、できる限り多くのデータを収集することが重要だ」と述べています。一方で、別の専門家は、「収集するデータは慎重に選び、分析プロセスの効率化やプライバシーの保護を最優先にすべきだ」としています。この2つの意見をどうバランスさせるかが、企業のデータ活用戦略の成功の鍵となります。
まとめ:ビッグデータ収集の最適化
データの収集は、単に技術的なプロセスであるだけでなく、企業のビジネス戦略と密接に関連しています。ビッグデータの量や多様性が増す中で、企業はデータ活用の目的に応じた収集・分析戦略を構築し、適切なデータソースを特定することが不可欠です。戦略的なデータ収集により、企業は効率的な意思決定と競争優位性の強化を実現できるでしょう。
データコンサルタントの視点から、ITXプロジェクトの推進に関連するITインフラ整備やデータ活用の重要性を強調し、企業がどのようにデジタル変革を成功させるべきかを、より具体的なアプローチで説明しました。
ITXがIT戦略を再定義する
ITX(ITトランスフォーメーション)は、デジタル化の加速とデータの有効活用を目指す企業にとって、戦略的な転換点となっています。既存のプロセスやワークフローをデジタル化するだけでなく、データの収集、保存、配信、およびデータ保護やビッグデータ分析を含む拡張性の高いITインフラの導入が、ITXプロジェクト推進の主な動機となっています。
特に、企業が直面する複雑なデータ管理の課題に対応するためには、クラウド、セキュリティ、そして自動化インフラが不可欠です。例えば、ヨーロッパにおけるGDPR(一般データ保護規則)の導入は、コンプライアンス強化の一環として、企業に大規模なデータ収集・利用に伴う新たな難題をもたらしました。このような規制対応を含め、データ保護を強化しつつ、データドリブンな意思決定を可能にするインフラ構築が求められています。
ITXプロジェクト推進の主要な動機
ITXプロジェクトを推進する最も一般的な動機は、クラウドコンピューティングのさらなる活用であり、オンプレミスインフラの効率化や、コスト削減、アジリティの向上が挙げられています。また、2位に挙げられるのは、データ分析とビジネスインサイトの活用であり、IoT(Internet of Things)やAI/ML(人工知能/機械学習)、リアルタイムストリーミング分析などの先進技術の活用がその鍵となっています。
特に、ITXによって企業は、これらの技術を通じてデータを収集・分析し、リアルタイムに意思決定を行う能力を向上させることができます。このため、ITXプロジェクトの導入により、データ活用を高度化し、競争優位性を確立する機会が広がると言えるでしょう。
ビッグデータの価値を引き出すためには?
ビッグデータの真の価値は、その量ではなく、いかにしてそれをビジネス上の**「正しい意思決定」**に結びつけるかにあります。データコンサルタントの視点から、ビッグデータを効果的に活用するためには、次のポイントが重要です。
データ収集の最適化:ビジネスにとって最も価値のあるデータを的確に収集できる仕組みを整備することが不可欠です。収集したデータは、単なる数値や記録としてではなく、ビジネスのインサイトを引き出すための基盤として活用されなければなりません。
データ分析の自動化とAI/MLの導入:膨大なデータの中から重要な情報を見つけ出し、迅速な意思決定に繋げるためには、AI/MLを活用した自動化が効果的です。これにより、リアルタイム分析を通じて、ビジネスの変化に迅速に対応できます。
データガバナンスとコンプライアンスの強化:特にGDPRなどのデータ保護規則への対応が重要です。データガバナンスを強化し、コンプライアンス遵守を徹底することで、データリスクを軽減しつつ、データの利活用を促進します。
データ活用を成功させるための第一歩
ビッグデータをビジネスに活かすために最初に行うべきは、データの収集から分析までのプロセスの明確化です。ITXを活用することで、企業はデータインフラを強化し、適切なデータ収集・分析基盤を整えることが可能になります。これにより、データの持つ潜在的な価値を最大化し、ビジネスの意思決定を迅速かつ精度高く行うための土台が構築されるでしょう。
データの力を最大限に引き出すために、ITXプロジェクトを通じて、ビッグデータの効率的な収集・分析と、ビジネス戦略への適用を同時に推進することが、企業の競争力を高める鍵となります。
ビッグデータの収集方法
データの収集は決して新しい概念ではありません。人類は何千年もの間、さまざまな情報を集めて生活の改善や意思決定に活用してきました。現代においても、データの管理と分析は引き続き重要な課題であり、特にビッグデータの量、多様性、そして増加速度は、かつてない規模に達しています。今日では、全世界で膨大なデータが毎日生成され、その利活用が企業にとっての重要な競争要因となっています。
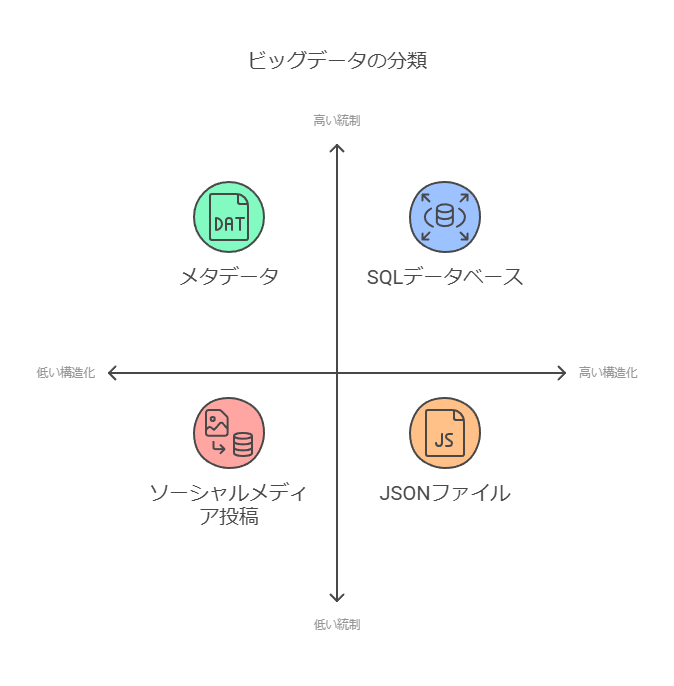
ビッグデータは、構造化データ、非構造化データ、半構造化データという3つの形式に分類されます。
構造化データ: クレジットカード番号やGPS座標など、一定のフォーマットやルールに従って表現されるデータ。
非構造化データ: ソーシャルメディアの投稿や電子メールのように、決まった形式を持たずに生成されるデータ。
半構造化データ: 構造化と非構造化が混在したデータ、たとえばXMLファイルや一部のログデータなど。
これらのデータを効果的に収集するためには、まずデータソースの特定が重要です。代表的なデータソースとしては、以下のものが挙げられます。
取引データ: POSシステムやERPなど、ビジネス取引を記録するシステム。
IoTデバイス: センサーやスマートデバイスから生成されるリアルタイムデータ。
マーケティングデータ: 調査会社や第三者から提供される市場データ。
ソーシャルメディア: 顧客や見込み客が生成する投稿やフィードバック。
位置情報: スマートフォンや車載デバイスから収集される位置情報データ。
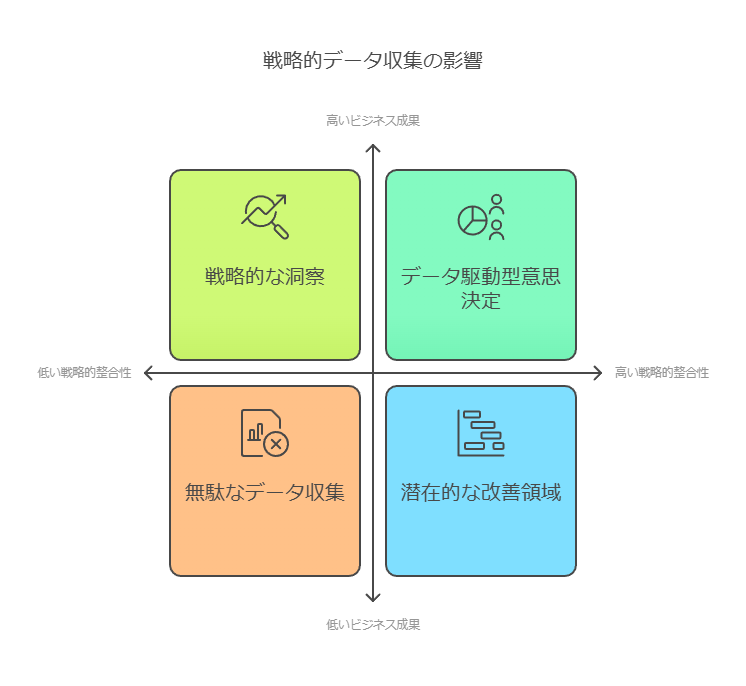
データ収集戦略の策定
ビッグデータの利活用を目指す企業が直面する最初のステップは、データ活用の目的を明確化することです。どのような意思決定やビジネス価値を引き出したいかを理解し、その目的に沿ったデータ収集のためのシステム構築に取り組む必要があります。
収集するデータの選定に関しては、2つの視点が存在します。
多くのデータを収集するアプローチ: 一部の専門家は、革新的なビジネスインサイトを得るために、できる限り多くのデータを収集すべきだと主張します。このアプローチは、特にAIや機械学習を活用するプロジェクトにおいて、データ量が精度や洞察の質に直結するため、適切です。
データの選別を行うアプローチ: 一方で、コスト管理や解析プロセスの複雑化、さらには個人情報保護の問題を考慮し、収集するデータを慎重に選別することを推奨する専門家もいます。企業は、過剰なデータ収集がリソースを圧迫し、効率的な分析を妨げるリスクがあることを理解する必要があります。
収集データの活用とガバナンス
データ収集の次に重要なのは、収集したデータをどのように活用するかです。収集されたデータを分析し、ビジネスインサイトや意思決定に役立てるためには、データ管理とガバナンスの強化が不可欠です。データガバナンスは、データの品質やセキュリティ、プライバシーを維持しながら、組織内でデータが一貫して活用されるようにするプロセスです。
効果的なデータ収集と活用を行うためには、次の点を考慮する必要があります。
データ収集の自動化: 手作業による収集は限界があります。IoTやAPIを活用して、リアルタイムでデータを収集し、効率的な処理を可能にするインフラを整備することが重要です。
データ品質の向上: ノイズや欠損データの除去、データの正規化を行い、信頼性の高いデータセットを構築する。
法的および規制の遵守: GDPRなどのデータ保護規則に対応し、データのプライバシーとセキュリティを確保する。
ビッグデータの収集は、単なるデータの蓄積ではなく、ビジネスゴールに直結する戦略的なプロセスです。収集したデータを活用して、競争力のあるビジネスインサイトを引き出すためには、明確な目的設定と、それに基づく適切なデータ収集システムの構築が必要です。また、企業は収集データの選定とガバナンスを強化し、データ保護と効率的な分析プロセスを両立させることで、ビッグデータの潜在力を最大限に引き出すことが可能です。
ビッグデータのパイプラインは、複数のステップに分かれており、それぞれのステップで異なる技術が使用されることがあります。
例えば、エンドツーエンドのデータ処理パイプラインでは、データのストリーミングにApache Kafka、データフローの管理にApache NiFi、データサイエンスと機械学習 (ML) にApache Spark、データの保存にHadoop分散ファイルシステム (HDFS)、SQLクエリの実行とビジネスインテリジェンスによるデータ分析にApache Hiveを使用することが一般的です。
ただし、こうしたパイプライン全体を異なるクラウドネイティブサービスで実装することは、運用面とコスト面の両方で難題を引き起こします。クラウドベンダーによっては、同様の機能を持つネイティブサービスを提供している場合もありますが、そこには3つの主な問題があります。
サポート体制の不足: 多くのクラウドプロバイダーは、オープンソースソフトウェア(OSS)をパッケージ化して提供していますが、顧客が運用するビッグデータのワークロードを十分にサポートするための開発者やコミッターを抱えていないことが多いです。
オーケストレーションの負担: 複数のクラウドネイティブサービスを統合してエンドツーエンドのパイプラインを構築する場合、その多くの責任は顧客側にあります。ベンダーは、エンタープライズレベルでの包括的なサポートを提供しないことが一般的です。
予測不可能なコスト構造: クラウドサービスの料金モデルはサービスごとに異なることがあり、総合的なコストを事前に正確に見積もることが難しいです。
データ分析ワークロードをクラウドに移行する際は、そのワークロードの実行に必要なリソースメトリクスを理解し、それに基づいたクラウドの課金モデルとサービスコストを把握することが重要です。効果的なコスト管理戦略として、長期間実行されるワークロードはオンプレミスに残し、弾力的なリソースが求められる一時的なワークロードのみをクラウドに移行するという方法が考えられます。
適切な運用の管理とビッグデータ分析ワークロードにおけるクラウドリソースの最適化を行うことで、全体のコストを大幅に削減することが可能です。
データコンサルタントとしての提言:
OSSの選定とサポートの強化: 運用面での安定性を確保するために、OSSを採用する際にはサポート体制が強固なベンダーや社内での専門家の確保が不可欠です。
オーケストレーションの自動化ツール導入: 手動でのオーケストレーションの負担を軽減するため、自動化ツールの導入を検討することが重要です。
コスト最適化ツールの活用: クラウド利用におけるコスト管理のために、可視化・モニタリングツールを活用してコストの見える化を進め、事前に予測しやすい環境を整備します。
一時的なワークロードをクラウドに移行することでコストを最適化することは、多くの企業にとって効果的な戦略です。
クラウドにはITインフラストラクチャの管理を簡素化し、コスト最適化を支援する数多くの利点があります。特に、クラウドプロバイダーによっては、使用量に応じたリアルタイムの課金モデルを提供し、必要なリソースを即座に利用できる点が大きなメリットです。これにより、一時的なリソース需要に迅速に対応できるため、無駄なコストを抑えることが可能です。
クラウド環境は、大規模なデータストレージや柔軟に利用可能なコンピュートリソース(CPU、GPU、メモリ)など、ビッグデータ処理に必要なビルディングブロックを提供しています。さらに、クラウドの大きな利点の一つは、コンピューティングリソースとストレージリソースが独立している設計にあります。これにより、ワークロードの要件に応じて、ストレージとコンピュートを個別に拡張し、最適なリソース配分が可能となります。
クラウドへのビッグデータアプリケーションの導入に際しては、まずワークロードのタイプ(バッチ処理、インメモリ処理、対話型処理、リアルタイム処理など)とその使用パターンを正確に把握し、リソース要件を明確にすることが重要です。ワークロードが長期的に続くものか、一時的なものかを見極め、クラウドリソースの弾力性を活用して、必要なときにのみリソースを活用することで、コスト効率を最大化できます。
ビジネスニーズに応じて、クラウドの弾力性を活かした一時的なワークロードを導入することで、データから洞察を得るまでの時間を短縮し、コストも削減できるでしょう。また、ほとんどのクラウド課金モデルは使用量ベースであるため、リソースの配備量だけでなく、実際の使用量に基づいて最適化を行うことが、コスト削減の鍵となります。
データコンサルタントとしての提言:
ワークロードの特性把握: 一時的なワークロードやバースト的な負荷に対するクラウドの弾力性を活かすため、リソース使用パターンを明確にし、適切なリソース割り当てを行います。
コストモニタリングツールの活用: クラウドサービスには、コストモニタリングツールが提供されていることが多いため、これを活用して、リアルタイムでコストの最適化を進めます。
適切な課金モデルの選択: 長期的なワークロードには予約型リソースを、一時的なワークロードにはオンデマンド型リソースを選択することで、コスト効率をさらに高めます。
クラウドへの移行を成功させるには、ビジネスニーズとリソース使用量に基づいた戦略的なクラウド活用が必要不可欠です。
クラウドにおけるビッグデータワークロードの最適化
クラウドでのビッグデータワークロードのプロビジョニングをシンプルかつ反復的に実行するためには、エンタープライズデータプラットフォームが必要です。このプラットフォームは、クラウドリソースのプロビジョニングやワークロードの展開を自動化し、ビジネスユーザーがセルフサービスで利用できるような環境を提供します。具体的には、ITオペレーターが定義したワークロードブループリントを用い、ビジネス部門が容易に活用できる仕組みが求められます。
データコンサルタント視点の改善ポイント
ワークロードの自動スケーリング: ワークロードがビジネスのサービスレベルアグリーメント(SLA)とリソース使用量に基づいて自動的にスケールアップやスケールダウンされる仕組みが不可欠です。この自動化により、リソースの無駄を減らし、コスト効率を高めることができます。
リソースの動的調整: ワークロードやアクティビティの変化に応じてクラスタを自動で調整し、リソースを最適化できるようにすることは、ビッグデータの効率的な運用に欠かせません。この仕組みを持つプラットフォームは、クラウドリソースの使用量を最小限に抑えつつ、必要なパフォーマンスを維持するために重要です。
使用量ベースのコスト管理: プロビジョニングされたインフラに応じた課金ではなく、実際のリソース使用量やビジネス価値に基づいたコストモデルが理想です。これにより、無駄な支出を避け、ビジネス価値に直結したコスト管理を実現できます。
柔軟なクラウド戦略とベンダーロックインの回避: 特定のクラウドプロバイダーやアプリケーションレイヤでのロックインを回避することが重要です。ロックインは、他のシステムとの統合を妨げたり、イノベーションの制約となったりするため、ビジネスの柔軟性を損なうリスクがあります。そのため、オープンソース技術やインターフェースの利用を検討し、相互運用性を高めることが推奨されます。
オープンソース技術の役割
近年、オープンソースソフトウェア(OSS)の導入が注目されています。ビジネスが特定のベンダーに依存しないための手段として、特にHadoopをはじめとするオープンソースのビッグデータ技術が普及しています。多くのテクノロジー大手企業は、OSSを導入することでロックインの回避やイノベーションの加速を目指しており、その結果、OSSを中心としたエコシステムが拡大しています。
しかし、クラウド戦略を採用する場合、データやアプリケーションをクラウドベンダーのインフラ上で動かすことで、ベンダーロックインのリスクは避けられません。特に、クラウドプロバイダーのネイティブクラウドサービスを利用すると、特定のインフラに依存するため、他のプラットフォームやオンプレミスに移行する際に制約が生じる可能性があります。これにより、以下のような課題が発生します。
アプリケーションの移行困難: 別のクラウドプラットフォームへの移行、もしくはオンプレミスに戻す際に、クラウドベンダーの特定サービスに依存していると柔軟性が失われ、移行に大きなコストが発生することがあります。
相互運用性の低下: クラウドプロバイダーの独自サービスを利用することで、OSSの機能や他のシステムとの統合が制限され、ビジネス全体の運用効率が低下する可能性があります。
データコンサルタントとしての推奨アクション
オープンソースの活用: ロックインを回避するため、OSSを積極的に採用し、標準化された技術スタックを構築します。これにより、システムの相互運用性を高め、将来的なクラウドプラットフォーム変更に備えることができます。
ベンダーロックインのリスク評価: 現在使用しているクラウドサービスや今後導入を検討しているサービスについて、ロックインリスクの評価を行い、代替手段や移行戦略を策定します。
クラウドネイティブとOSSのバランス: クラウドネイティブなサービスを活用しつつ、OSSの相互運用性を維持するために、ハイブリッドなアプローチを採用し、柔軟なシステムアーキテクチャを構築します。
モダンなデータアーキテクチャ: データとアナリティクスの活用
ビジネスが競争力を維持し、成長を加速させるためには、データとアナリティクスを中心としたモダンなデータアーキテクチャが不可欠です。このアーキテクチャは、業界固有のニーズに対応するために、ビジネスワークフローとアナリティクスを密接に統合し、特化したビジネスアプリケーションを提供します。データを活用してビジネス価値を創出し、競争優位性を確保することこそが、モダンなデータアーキテクチャの核心にあります。
データコンサルタント視点の改善ポイント
異種システムの統合: 現代のビジネスアプリケーションは、オンプレミス環境やクラウドベースのシステム、さらには複数のベンダーにまたがる異種システムとも統合できる必要があります。これにより、企業は柔軟性を持ってデータを管理し、各システムの利点を最大限に活用できるようになります。モダンなアーキテクチャを採用することで、シームレスな統合が可能となり、データを一元管理し、効率的なビジネス運用を実現します。
ビジネス価値の最大化: 今日の企業リーダーが真に求めているのは、単なる機能の多さではなく、ビジネス価値を直接的に高めるアプリケーションです。モダンなデータアーキテクチャは、分析機能とビジネスプロセスを統合することで、迅速にデータからインサイトを得ることを可能にし、意思決定の精度を向上させ、ビジネスの俊敏性を高めます。
簡素化された所有体験: モダンなデータアーキテクチャは、複雑なシステム管理を簡素化し、顧客がすぐに価値を享受できるよう設計されています。例えば、ERPの完全導入がまだ完了していない場合でも、クラウドの自動化とオープンアーキテクチャを活用することで、あらゆるデータソースに接続し、すぐにビジネス価値を創出できるという柔軟性を提供します。これにより、導入初日からデータ活用を推進し、業務効率化を促進します。
多様なユーザー層への対応: モダンなデータアーキテクチャの重要な特徴は、技術者と非技術者の双方が使いやすいことです。高度なデータサイエンティストやエンジニアだけでなく、ビジネスユーザーも利用できる直感的なツールが揃っており、ビジネス部門が独立してデータに基づいた意思決定を迅速に行えるよう支援します。
具体的な機能と利点
ERP、iPaaS、BI、AI、データレイクソリューションの提供: これらのソリューションは、業務の自動化や効率化を促進し、時間とコストの大幅な削減を実現します。特に、データレイクを活用することで、大量かつ多様なデータを一元的に管理し、ビジネスインテリジェンス(BI)やAIの活用によって迅速に分析を行うことができます。
セルフサービス型のデータアクセス: 技術者だけでなく、ビジネスユーザーがセルフサービスでデータにアクセスし、レポートや分析を作成できる環境が整備されています。これにより、手動プロセスの削減が可能となり、より迅速で効率的な業務運用が実現します。
ダッシュボードや統合機能の強化: 幅広いダッシュボード機能やアナリティクス、統合機能を活用し、経営層や現場のユーザーがリアルタイムでビジネスパフォーマンスを可視化できるようになります。これにより、データに基づく意思決定が強化され、ビジネス全体の生産性が向上します。
データコンサルタントとしての推奨アクション
データ統合戦略の最適化: 異種システムの統合を推進し、データを一元管理することで、データのサイロ化を防ぎ、ビジネス全体でデータを最大限に活用できるよう支援します。
セルフサービスアナリティクスの導入: ビジネスユーザーが独立してデータを利用できるセルフサービスの仕組みを導入し、データに基づく迅速な意思決定を可能にします。
クラウドの自動化とオープンアーキテクチャの活用: クラウドの自動化機能とオープンアーキテクチャを活用して、あらゆるデータやツールに接続し、業務効率化を推進します。
モダンなデータアーキテクチャの導入は、データの活用を通じて、ビジネスの変革を加速させるための強力な基盤となります。
クラウド環境とオンプレミス間のデータ移動の最適化
ビジネスのデータ戦略において、複数のクラウドサービスやオンプレミス環境間でのデータ移動は、重要な要素です。しかし、クラウドベンダーの分析サービスが特定のカスタムデータ形式を使用する場合、データの変換が必要となるため、互換性の課題が生じることがあります。これにより、データの移動や統合が煩雑になり、エンタープライズのデータ戦略に影響を及ぼします。
データコンサルタントの視点からの改善ポイント
データポータビリティの確保: クラウドやオンプレミス間でデータを移動させる際には、互換性や標準化が鍵となります。ベンダーロックインを避けるため、OSS(オープンソースソフトウェア)のイノベーションを活用し、標準化されたフォーマットやオープンプロトコルを採用することで、データのポータビリティを確保しましょう。また、クラウド間でデータが移動する際には、メタデータやセキュリティポリシーの一貫性を維持することが求められます。
ハイブリッドクラウド戦略: ハイブリッドクラウドに移行する際、オンプレミスで使用しているビッグデータ技術のOSSエコシステムをクラウド上でも活用することが、柔軟かつ効率的な運用を実現するためのカギとなります。これにより、データファブリックを活用して、オンプレミス、クラウド、ハイブリッド環境全体でデータ管理やセキュリティを一貫して適用できるようになります。
データリネージとガバナンスの強化: データが異なる環境間を移動する際には、データリネージ(データの流れの追跡)やメタデータの管理が特に重要です。データがどこで生成され、どのように処理され、どこに保存されるかを明確に把握することで、セキュリティリスクを最小限に抑え、コンプライアンス要件にも対応できます。
技術的ヒント
オープンソースベースのエンタープライズデータプラットフォーム: オープンソースのデータプラットフォームを選択する際には、特定のクラウドに依存せず、異なる環境間で容易にデータアセットやメタデータ、ワークフローを移行できることが重要です。これにより、企業は将来的なクラウドベンダーの変更にも柔軟に対応でき、コスト効率の高いデータ運用が可能となります。
一貫したデータファブリックの実装: クラウドインフラストラクチャー上で一貫したデータファブリックを実現することで、データの移動や分析がシームレスになり、クラウドリソースを最適化できます。これにより、企業は複数のクラウド環境やオンプレミス環境間でのデータ管理をシンプル化し、アプリケーションのポータビリティを向上させることが可能になります。
一元的なプロビジョニングプラットフォームの活用: 一元的なプロビジョニングプラットフォームを導入することで、マルチクラウド環境へのデータ管理サービスを簡素化し、どのクラウドでもビッグデータワークロードを迅速に実行できるようになります。さらに、ネイティブクラウドリソース(コンピューティング、ストレージなど)をフル活用し、リソース使用を最適化することで、コスト効率を向上させることができます。
データコンサルタントとしての推奨アクション
ハイブリッドクラウド環境の設計と実装: オンプレミスとクラウドの両方でデータを効果的に管理・分析できるように、OSSエコシステムを活用したハイブリッドクラウド環境を設計し、柔軟性とポータビリティを高めます。
一元化されたデータガバナンスの導入: 異なる環境間でデータが移動する際にも、データリネージやセキュリティポリシーを継続的に追跡し、コンプライアンスを確保するためのガバナンスを強化します。
マルチクラウド戦略の最適化: マルチクラウド環境でのデータ運用を最適化し、クラウド間のポータビリティを向上させ、ビジネスニーズに応じた柔軟なデータ戦略を実現します。
これらの戦略と技術的ヒントを取り入れることで、データ運用を効率化し、クラウド環境でもオンプレミスでも一貫したデータ管理と分析が可能となります。
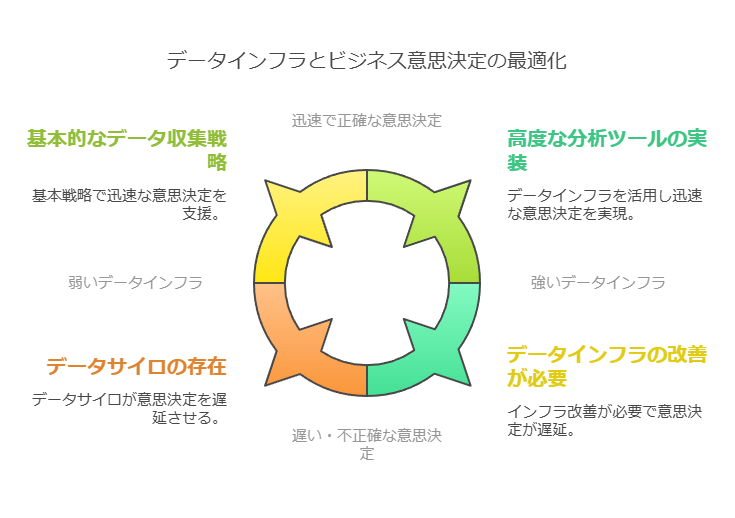
ビッグデータの価値は「量」ではなく「正しい意思決定」を引き出す能力にある
データコンサルタントとしての視点から、ビッグデータの価値を最大限に引き出すためのアプローチを段階的に見直し、戦略的なデータ活用のポイントを強調します。
1. ビッグデータの重要性とその投資状況
現在、データは企業にとって非常に価値の高い資産となっています。NewVantage Partnersが2021年に実施した調査によると、ほぼ全ての大企業がビッグデータの活用に力を入れており、その取り組みはビジネス成果に大きく貢献しています。例えば、**回答企業の99%がビッグデータ活用に注力していることが明らかになり、そのうちの96%**が、AI技術を活用したデータ分析がビジネスに価値をもたらしていると答えています。
データコンサルタントの観点から:
企業は単にデータ収集に投資するだけでなく、データがどのように意思決定に寄与するかを深く考える必要があります。データの量よりも質やその活用方法にフォーカスすることが重要です。
例えば、企業がビッグデータの分析に投資する場合、その投資は正しい判断を支えるためのものであり、ビジネスに直結する戦略的な意思決定を促進する必要があります。
2. ビッグデータの価値は量ではなく、意思決定の質で測られる
ビッグデータの価値は、その量にのみ依存するものではありません。むしろ、企業はデータからどのように洞察を引き出し、それを経営判断にどう結びつけるかが肝要です。ビッグデータの収集と分析が適切に行われれば、企業はそのデータを活用して競争力を高めることができます。
データコンサルタントの観点からの戦略:
データ準備の重要性: ビッグデータ活用の初期段階では、データの収集・整備が不可欠です。データが散在している場合や、フォーマットが統一されていない場合、分析結果に一貫性がなくなる可能性があります。
データガバナンス: 適切なガバナンスを行い、データの正確性と信頼性を高めることが、的確な意思決定を支えるための重要な要素となります。
意思決定支援のためのツール: データの可視化ツールやAI技術を活用し、リアルタイムでビジネスインサイトを提供できる仕組みを構築することが求められます。これにより、データドリブンな意思決定を迅速かつ精度高く行うことが可能となります。
3. ビッグデータの導入における障害とその解決策
Talendのクリストフ・アントワンヌ氏も指摘しているように、大量かつ多様なデータから「価値」を引き出すことは決して容易ではありません。特に、データの多様性や増加速度が急速に進んでいる現代において、効果的なデータ収集と分析が難しくなることが多々あります。
データコンサルタントの視点での解決策:
データ統合の自動化: ビッグデータが複数のシステムやプラットフォームに分散している場合、データ統合を自動化することが求められます。これにより、リアルタイムにデータを収集・統合し、分析に適した形で提供できます。
スケーラブルなデータアーキテクチャの導入: クラウドベースのデータ管理や、柔軟に拡張可能なアーキテクチャを採用することで、企業はデータの増加に応じてリソースを適切に調整し、パフォーマンスを最適化することが可能です。
推奨されるデータ戦略
データ活用の明確なビジョンを持つ: データがビジネスにどのように役立つかを理解し、それに基づいて適切なツールや技術に投資することが重要です。
AIとデータ分析の統合: AI技術を駆使してビッグデータを分析し、迅速な意思決定をサポートする仕組みを整備することで、競争優位を確保します。
継続的なデータ最適化: ビッグデータの価値を最大限に引き出すためには、定期的にデータ活用プロセスを見直し、必要に応じて改善していくことが不可欠です。
このように、データコンサルタントの視点では、ビッグデータの量そのものよりも、データがどのようにビジネスの意思決定を支え、ビジネス価値を高めるかにフォーカスすることが重要です。適切なデータ収集、統合、ガバナンスを通じて、企業は21世紀における競争力を大きく高めることができます。