目次
DR計画の重要性と落とし穴:復旧順序とテストの徹底
DR計画の優先順位と復旧順序の設定
災害復旧(DR)計画には、各プラットフォームの復旧順序を明確に定義することが必須です。復旧の優先順位はアプリケーションやサービスの重要度に基づいて設定されることが多いものの、企業の主要な拠点の復旧が必要になると、社内の利害関係が影響を与える可能性もあります。また、災害復旧の初動を担当できるリソースや、作業環境の準備状況も重要な検討事項です。
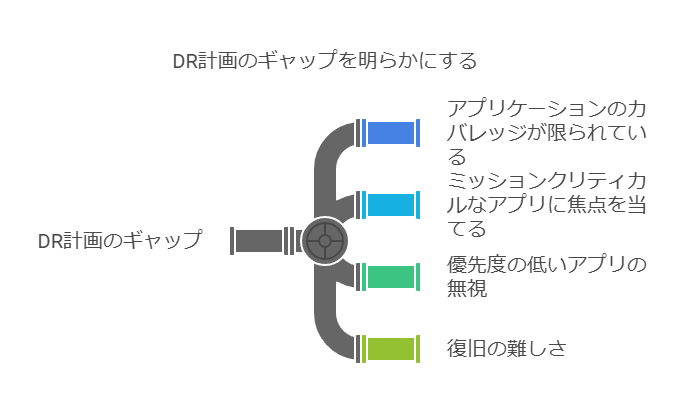
DR計画が用意されていても、対象範囲を過度に限定するのはリスクがあります。IT部門や経営陣が「計画があるから大丈夫」と誤解し、実際には全てのアプリケーションが保護されておらず、重要なシステムの依存関係が見落とされることもあります。
実際に、DR計画で保護対象になっているアプリケーションは約38%程度に過ぎず、多くのIT部門が、主要なミッションクリティカルなアプリケーションのDR計画を策定した後、他の業務に移行してしまいがちです。この結果、重要度がやや低いアプリケーションやデータの接続が失われ、環境全体の早期復旧が困難になるケースも少なくありません。
効果的なDR計画には、目標復旧時点(RPO)や目標復旧時間(RTO)を明確に設定する必要があります。これは、安定した状態のクリーンなデータセットをどの時点まで戻すべきか、また、その作業にどの程度の時間が必要かを明示するものです。
DRの落とし穴:テストの不足
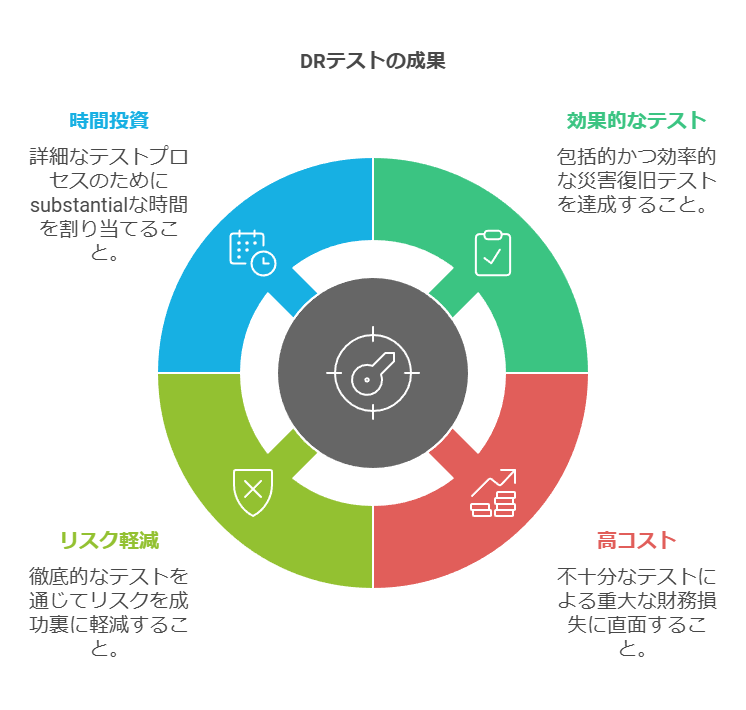
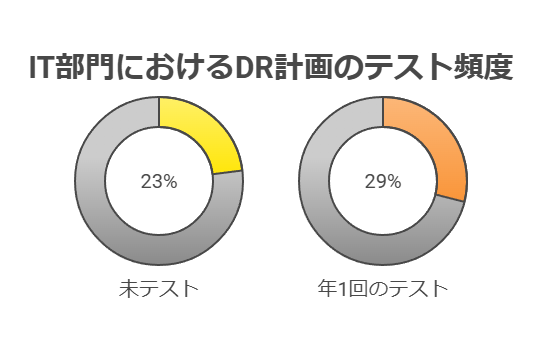
DR計画における最大の落とし穴の一つは、テストの不足です。統計によると、IT部門の約23%がDR計画を一度もテストしておらず、年間1回のテスト実施にとどまる企業も29%程度です。年に1回のテストが十分か否かは、事業の規模や性質に大きく依存しますが、テストされない計画は「無計画」状態から大きく進んでいないのと同様です。
DR計画はテストすることで、初めてその機能性や、保護対象システムが完全にカバーされているかの確認が可能です。Freeform DynamDR計画をテストしなければ、その効果は未知数であり、システム保護の有効性も分からないと思います。
効果的なテスト体制を構築するには、CIO(最高情報責任者)の強力なリーダーシップが欠かせません。DR計画のテストは時間とコストがかかる作業ですが、災害から迅速に復旧できなければ、さらに大きなコストを被る可能性があるため、リスク軽減のために欠かせない投資といえます。
DR計画におけるテストと更新の重要性、およびバックアップ保護の課題
DR計画のテストと継続的な更新
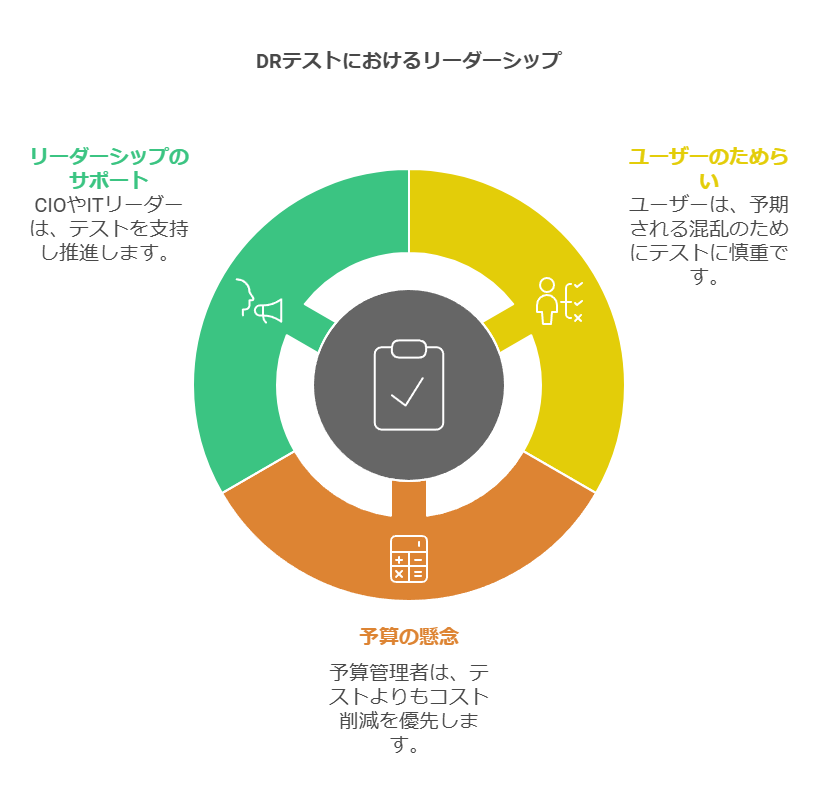
災害復旧(DR)計画の効果を最大化するには、計画のテストが欠かせませんが、事業部門のユーザーや予算管理者がテストの実施に慎重になるケースが多く見られます。そのため、IT部門のリーダーやCIOが率先してテストの実施を支持する強力なリーダーシップが必要です。
また、DR計画は成長、買収、業務プロセスや技術の変化に応じて更新されるべきドキュメントです。計画は一度策定しただけでは不十分で、放置すると状況に対応できなくなり、実質的な効果を発揮できなくなります。実際のテストから得られる教訓をもとに、CIOやITリーダーは定期的な更新を行い、その後も再テストして改良するというサイクルが欠かせません。
データ保護以外の盲点:バックアップの脆弱性
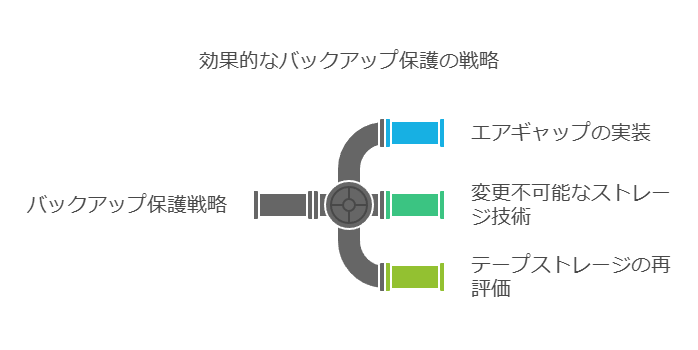
近年、DR対策が再び重要視されている背景には、マルウェア、特にランサムウェアの脅威が増していることが挙げられます。攻撃者がまずバックアップデータを狙うケースが多いため、バックアップの保護も不可欠です。バックアップを守る手段として、運用システムとバックアップコピー間に「エアギャップ」を設けたり、変更できないストレージ技術を使用することが推奨されています。また、オフサイトでのデータ保管としては、コスト効率の面からテープストレージを再評価するIT部門も増えています。
しかし、こうした取り組みも簡単ではありません。特に、事業継続計画(BCP)と目標復旧時間(RTO)の短縮を意識する場合、継続的なデータ保護が必須となります。IDCのグッドウィン氏も指摘する通り、「常時エアギャップを維持することは難しく、12~24時間分のデータ損失を考慮する必要がある」と警鐘を鳴らしています。クリーンなデータを得るための代償として、データの一部が損失する可能性もあるため、計画段階でこれらのリスクを含めたバックアップ保護を強化する必要があります。
DRの課題:指揮、制御、そしてコミュニケーションの重要性
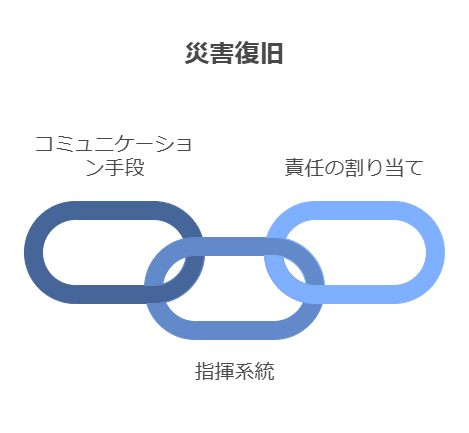
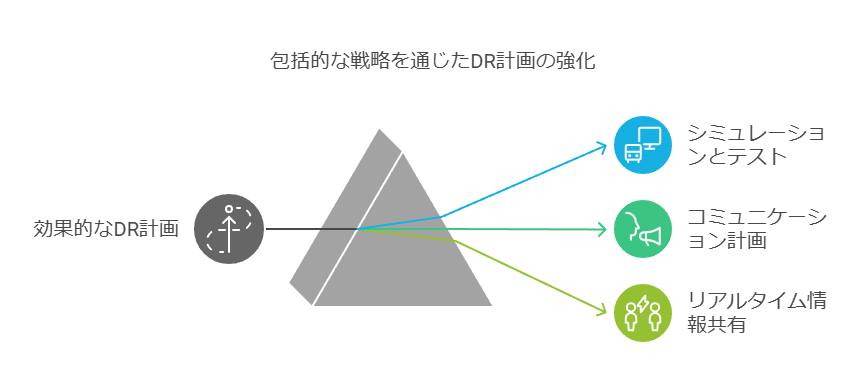
DR(Disaster Recovery: 災害復旧)において、円滑な指揮と効果的な制御を確保するためには、コミュニケーション手段と指揮系統の明確化が不可欠です。まず、DRの発動責任者を明確に設定し、障害発生時には全スタッフが迅速かつ継続的に連絡を取り合うことができる体制を構築する必要があります。
DR計画は、事前のシミュレーションや堅牢なテストを通じて、指揮系統や制御面での不備を洗い出すことが理想的です。特に大企業においては、危機的状況に備えたコミュニケーション計画を包括的に設けることが推奨されます。また、DRと事業継続性に関する情報は、全社員が定期的に把握できるようにし、リアルタイムでの状況共有が行われる体制を整えることが望ましいです。
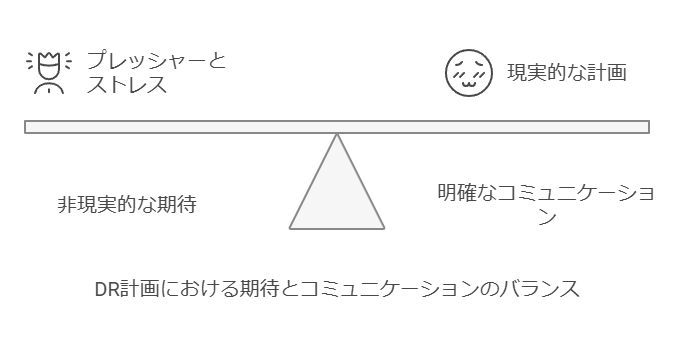
ユーザーはDR発動後、システムが即座に完全復旧するといった過度な期待を抱くことがあります。こうした期待が重圧となることで、事態が予期せぬ方向へと進んでしまうリスクがあります。これに加えて、事前に明確なコミュニケーションを行い、復旧対象のデータやシステムの順序や所要時間について具体的な期待値を設定しておくことが重要です。
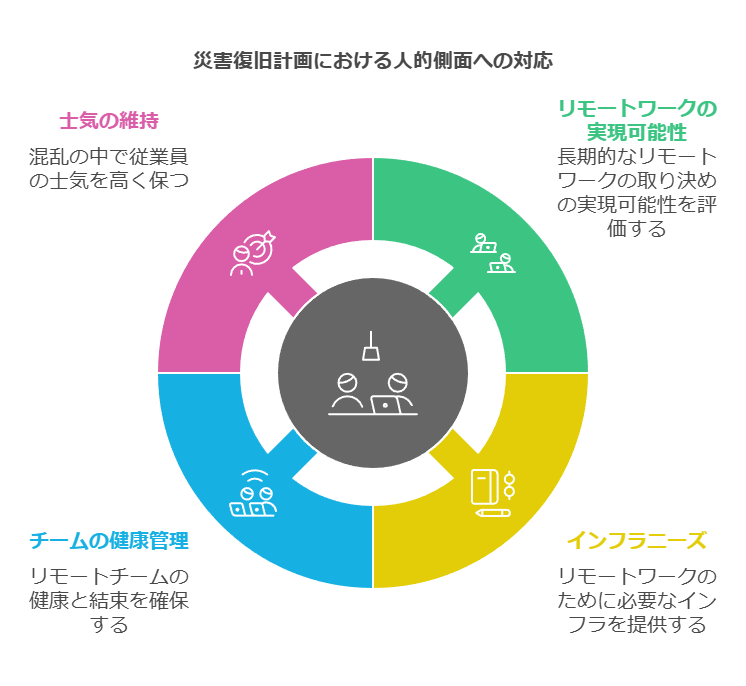
DRの課題:人員に関する考慮不足
IT部門はDR計画の際、通常システムとデータを中心に据えて考える傾向にありますが、効果的なDR計画には人的要素も欠かせません。主要な事業拠点に被害が生じた場合、従業員の就業場所や働き方への対応を含む支援計画が求められます。
一部の従業員は自宅で仕事を続けることが可能かもしれませんが、その状況が長期間持続可能であるかどうかについて検討が必要です。たとえば、デスクトップPCが必要な従業員や、家庭用・モバイル回線よりも広帯域を必要とする従業員に対して、代替手段の提供を考慮する必要があります。また、会議スペース、チームの健康管理、さらに災害時の士気維持も重要な課題です。こうした人的側面に対する十分な配慮は、技術的な復旧計画と同等の重要性を持つことを忘れてはなりません。
クラウド活用におけるディザスタリカバリ(DR)のリスクと考慮点
オンラインバックアップサービスの普及により、クラウドを活用することでDR(ディザスタリカバリ)が一見容易に実現できるように見えます。しかし、ハイブリッドクラウドやマルチクラウドの採用が増える一方で、IT運用は以前よりも複雑化しており、見落とされがちなリスクも少なくありません。例えば、事業部門が独自でクラウドリソースを購入・稼働させるケースでは、IT部門が全体のインフラ構成を把握できていない可能性があります。このような状況では、DR計画にクラウド特有の障害対策が盛り込まれているか確認が必要です。
調査によると、DR計画にクラウドサービスを含めている企業は約3割程度に過ぎず、多くの企業がクラウドプロバイダーのバックアップ機能や事業継続計画に頼りがちです。しかし、例えばユーザーの誤操作でデータが削除された場合など、クラウドプロバイダーだけではカバーしきれないリスクもあります。また、クラウドアプリケーションとオンサイトのデータストアが組み合わされた環境では、障害が部分的に発生するとデータが分散しているため、従来のスタックよりも復旧が複雑化する恐れがあります。
徹底的なDRテストとクラウドのDRソリューション活用
DR計画が効果を発揮するには、継続的なテストが不可欠です。NetApp ONTAPのように、オンプレミスでもクラウド上でもデータ保護が行えるソリューションは、堅牢なDR実現に貢献します。AWS、Google Cloud、Azureといった主要なクラウドプロバイダーが提供するネイティブDRソリューションを組み合わせることで、DR計画の冗長性と確実性を高めることができます。
Cloud Volumes ONTAPの活用により、フェイルオーバーやフェイルバックが迅速に実施できるようになるため、ダウンタイムとデータ復旧にかかるコストを削減できます。
クラウドのアップタイム管理とその重要性
アップタイム(システム稼働時間)は、クラウドサービスのSLA(サービスレベル合意)で重要視される条件の一つであり、サービスへのアクセス可能時間を示します。現在、ほぼ全てのデータがミッションクリティカルとされているため、一般的なクラウドサービスは「99.9%以上の稼働時間」を保証しています。これは年間約9時間の停止を許容する水準にあたりますが、特に業務においてダウンタイムが許されない場合、これをどう補完していくかが企業の課題となります。
クラウド障害とディザスタリカバリ(DR)の準備
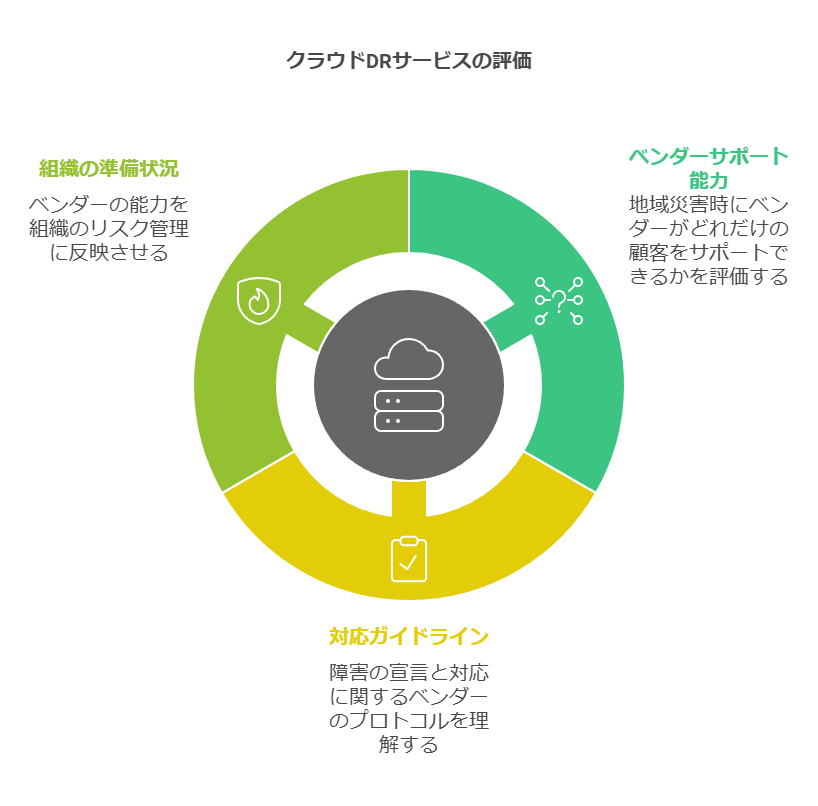
クラウド障害とは、クラウドDR(ディザスタリカバリ)環境にアクセスできない状況を指し、その原因は自然災害からサイバー攻撃まで多岐にわたります。DRサービスを選定する際には、ベンダーがどの程度の顧客を地域災害においてもサポートできるか、また障害の宣言や対応のガイドラインがどうなっているかを確認することが重要です。これにより、組織は障害発生時の対応力を理解し、実際の運用における準備とリスク管理に反映させることができます。
クラウド保険とリスク管理
クラウド保険は、クラウドベンダーが提供するサービスを保証するためのリスク管理の手段であり、サービス停止時の責任を明確にし、顧客に補償を提供するものです。クラウド保険を通じて、DR利用不可やセキュリティ侵害が発生した際に、損失機会や業務停止への補償を受けることが可能です。クラウド保険はクラウドベンダーから提供される場合もありますが、サードパーティの保険会社からも加入でき、企業のリスクヘッジの手段として役立ちます。
テスト不足が招くDR計画の落とし穴
DR計画は、予期せぬ事態が発生してもビジネスを迅速に回復させるために不可欠ですが、テスト不足は計画の実効性を著しく損なう原因となります。計画段階だけでなく、継続的なテストとシミュレーションを通じて、DR計画の中で見落とされがちな脆弱性やクラウド特有のリスクに対処することが、事業継続性の確保には欠かせません。
DR課題と背景の明確化
エンタープライズプラットフォームには、ビジネス継続性の観点からディザスタリカバリ (DR) 環境が不可欠です。プラットフォームがオンプレミスであろうとクラウドであろうと、DR環境の欠如は、大規模なインフラ障害発生時にビジネスクリティカルなサービスの継続性を阻害するリスクがあります。自然災害やサイバー攻撃といった予測不能なリスクによってプライマリサイトがダウンする可能性もあり、その際の迅速なサービス復旧が求められます。こうしたシナリオに備えるため、フェイルオーバー用のセカンダリサイトをあらかじめ確保することが重要です。
DRコストと効率性の課題を整理
しかし、多くの企業にとってDR環境の構築はハードルが高く、特に本番環境とは別に独立したインフラやサイトを維持するためのコストが課題となります。従来、DRサイトはほとんどがアイドル状態であり、コストの割に利用されないリソースとなっていました。こうしたコスト面の課題に対し、クラウドはスケーラブルで柔軟なインフラサービスとして、オンプレミスとクラウド両方に対応したDR環境の構築に役立つ解決策を提供しています。
クラウド利用のメリットと課題の整理
クラウドベースのDRを導入する場合、まずは本番環境データのDRサイトへの同期が必要であり、この継続的なデータ同期もまたDR運用における重要な要素です。本書では、DR環境構築の課題や、AWS、Google Cloud、Azureが提供する主要なDRサービスについて検討します。また、ネットアップの「Cloud Volumes ONTAP」を活用し、エンタープライズ向けに費用対効果の高いデータレプリケーションとDRの実現を図る方法も紹介します。
ネットアップソリューションの利点と価値の提示
Cloud Volumes ONTAPは、既存のネットアップストレージシステムと主要なパブリッククラウドベンダーのクラウドベースシステムを統合し、効率的かつスケーラブルなDR環境を提供します。クラウドを活用したエンタープライズクラスのDRソリューションとして、Cloud Volumes ONTAPはコスト効率とシステムの信頼性を両立し、ビジネス継続性を強化するための実践的な手段となるでしょう。
DRサイトの柔軟な活用による業務継続性の確保
DR(Disaster Recovery)サイトは計画外のシステム停止時だけでなく、計画的なメンテナンスや本番環境の更新時にも活用できます。たとえば、プライマリの本番環境を更新する際に、一時的にDRサイトへ業務を移すことで、ダウンタイムを回避可能です。この場合、DRサイトにフェイルオーバーし、メンテナンス終了後に本番環境へフェイルバックする手順をとります。これにより、DRイベント発生時と同様の手順でサービス移行が実施されるため、DRサイト運用のスムーズさが確保されます。
プライマリサイトとDRサイトの一貫性維持
エンタープライズ環境は日々進化し、ソフトウェアのアップデートやパッチが頻繁にリリースされます。プライマリサイトでの検証は通常、運用の一環として行われますが、DRサイトへのアップデートや検証が不十分なケースは珍しくありません。いざというときにDRサイトが機能しない事態を防ぐために、定期的にDRサイトへのテストを行い、確実に運用可能な状態を維持することが重要です。
DRサイトのリソースの有効活用
DRサイトはほとんどの時間、アイドル状態で待機しています。コスト効率を高めるために、DRサイトを読み取り専用のレポート環境やソフトウェアのテスト開発環境として補助的に利用することで、リソースの対費用効果を高めることができます。
DRサイト管理における重要な要素
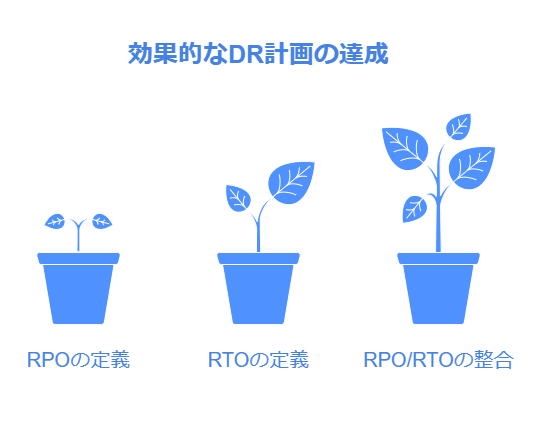
RPO(目標復旧時点): DRイベント発生時に許容可能なデータ損失期間。RPOはデータの重要度に応じて設定し、データ保全を図る指標です。
RTO(目標復旧時間): DRイベント発生後、業務を再開するまでにかけられる時間。業務に及ぼす影響を最小限にするための基準です。
定期的なデータ同期: DRサイトのデータを常に最新に保つために、効率的なデータ同期を定期的に実施します。これにより、緊急時のDRサイト移行が迅速に行えます。
フェイルオーバーとフェイルバック: データの役割を一時的にDRサイトに移し、メンテナンスや障害対応が完了した際にプライマリサイトに戻す機能で、サービスの中断を最小化します。
定期テスト: DRサイトのフェイルオーバーが想定どおりに動作するか、定期的なテストによって検証することが必要です。これにより、DR計画が実効性を伴うものとなります。
コスト管理: DRサイトのコンピューティング・ストレージリソースを有効活用することで、対費用効果を最大化します。
この構成により、DRサイトの活用法、管理上の留意点、コスト最適化までの一連の流れが明確になり、ビジネス継続性を保ちながらDRサイトを有効利用するための戦略がわかりやすく伝わるようにしました。
クラウドベースのDR環境の構築における基本的な考え方
クラウドベースのDR(Disaster Recovery)環境を設計する際には、コンピューティング、ネットワーク、ストレージといった各レイヤにおける冗長性が必要不可欠です。これにより、サービスが中断した際の迅速なリカバリーが可能になります。ここでは、主要なパブリッククラウドプロバイダー(AWS、Azure、Google Cloud)のネイティブサービスを用いて、各レイヤの冗長性を確保する方法を解説します。
DR環境を構成する基本ビルディングブロック
クラウドベースのDR環境における主なビルディングブロックは、コンピューティング、ネットワーク、ストレージの3要素です。これらを効果的に組み合わせ、災害時に即座にリカバリーできるインフラ構成を目指します。
コンピューティング
コンピューティングリソースは、アプリケーションのパフォーマンスを支える要です。AWSのAmazon EC2、Google CloudのCompute Engineインスタンス、Microsoft AzureのVirtual Machinesは、さまざまなインスタンスタイプを提供しており、企業の要件に応じたCPU性能やメモリ容量の調整が可能です。特に、コンテナ化されたアプリケーションには、AWSのAmazon EKS、AzureのAKS、Google CloudのGKEといったKubernetesサービスがサポートされています。これにより、高い柔軟性を持ちながら、アプリケーションの自動拡張や可用性を担保できます。
コスト効率を考慮したDRアーキテクチャ: パイロットライト戦略
一部の企業では、特に重要なアプリケーションとサービスのみをDRサイトで常時稼働させる「パイロットライト」戦略を採用しています。この手法により、インフラの残りの要素はフェイルオーバー時にオンデマンドで立ち上げる仕組みとし、通常時のDRサイトのコストを抑えることができます。パイロットライト戦略は、リソースを平時に最小限に維持することで、予算にやさしいDR環境の実現を可能にします。
データコンサルタントの視点から、以下のように整理し、クラウドDR(災害復旧)環境の構成要素について明確化しました。
1. クラウドリソースの再作成とテンプレート化
AWS CloudFormation、Google Cloud Deployment Manager、Azure Resource Managerを使用することで、定義済みのテンプレートから迅速にコンピューティングやネットワーク、ストレージなどのクラウドリソースを再作成できます。これにより、障害発生時や更新時にもシステム全体を迅速かつ一貫して復旧でき、運用の継続性を確保できます。
2. ネットワーク冗長性とトラフィック管理
プライマリサイトとDRサイト間でのトラフィック管理は、DRソリューションの成功に不可欠です。以下に一般的な技術を示します:
DNSベースのフェイルオーバー管理
DNSを活用することで、クライアント側の設定変更なしにサービスの参照先リソースを変更可能です。Amazon Route 53、Azure DNS、Google Cloud DNSなどを利用することで、必要なときに手動でDRサイトへの切り替えが行えます。
自動フェイルオーバー機能
より高度なフェイルオーバーには、Amazon Traffic Flow、Google Traffic Director、Azure Traffic Managerを使用します。これにより、プライマリサイトに異常が検出された際に、自動的にDRサイトにトラフィックを誘導し、ダウンタイムを最小限に抑えることが可能です。
3. ストレージの最適化と階層化
データリポジトリは使用頻度とコストに基づいて最適化されており、階層化されたストレージソリューションを採用することで、データ保存の効率を高めています。階層化により、データは受信されると同時に適切な容量階層に配置され、コスト効率が向上します。
4. シームレスなフェイルオーバーとフェイルバックの実現
実際にDRイベントが発生した際には、管理者がDRサイトのストレージを迅速かつ確実にオンラインにすることが求められます。以下のツールや方法が有効です:
SnapMirrorによるフェイルオーバーサポート
SnapMirrorのネイティブサポートを活用することで、フェイルオーバーのプロセスが簡素化され、DRサイトのストレージボリュームが迅速にアクティブ化されます。
効率的なフェイルバックとデータ同期
プライマリサイトの復旧後、DRサイトで新たに生成されたデータがソース側に迅速に同期され、完全なデータレプリケーションが再確立されます。この際、ベースラインデータのフルコピーが不要なため、リカバリプロセスが効率化されます。
Cloud Managerによる操作性の向上
Cloud Managerには、フェイルオーバーおよびフェイルバック処理を一元管理できるグラフィカルユーザインターフェイスが搭載されており、管理者が複雑なDR操作を簡単に実施可能です。
この構成により、クラウドDR環境の各要素の役割やその冗長性確保の具体的方法が整理され、クラウドベースのDRアーキテクチャの導入・管理におけるポイントが明確になりました。
データコンサルタントの視点から整理し、DRソリューションを運用する際の課題と解決策を明確にします。
幅広いデータストレージオプションの活用と冗長性
AWS、Google Cloud、Azureは、各種のデータストレージサービスを提供しています。これには、以下のようなオプションが含まれます:
ブロックレベルストレージ
Amazon EBS、Google Persistent Disk、Azure Diskなど:これらは単一のアベイラビリティゾーン内での冗長性を提供し、重要なデータの一元管理が可能です。
ファイルベースストレージ
Amazon EFS、Google Filestore、Azure Filesなど:ゾーン間の高可用性を実現し、業務を継続しながら複数の場所にデータを保持できます。
オブジェクトストレージ
Amazon S3、Google Cloud Storage、Azure Blob:リージョン全体でデータを管理することで、大規模なデータ冗長性と可用性を確保します。
DRサイトの実装における課題
DRサイトを設計・運用する際、リソースの独立運用や手動プロセスの構築は、運用の複雑化とコストの増大を招く可能性があります。たとえば、Amazon EBSを使用してAmazon EC2のデータをDRサイトで利用する場合、EBSスナップショットによるデータ転送が必要です。しかし、このフェイルオーバーやフェイルバックのプロセスには、手動での開発・テストが伴い、煩雑かつリスクを伴う運用が求められます。
NetApp Cloud Volumes ONTAPを活用した課題解決
NetApp Cloud Volumes ONTAPは、これらの課題を簡素化し、運用効率を向上させるソリューションです。以下のような特徴により、DRプロセスの自動化とコスト最適化を支援します:
スナップショット自動化
NetAppのスナップショット機能を活用することで、手動設定を省略し、データのフェイルオーバーを迅速に実施可能です。
管理コストの低減
クラウドネイティブな統合インターフェースで、リソースの一元管理を実現します。これにより、DRソリューションの構築と運用にかかる管理者の負担を軽減し、コストとリスクの抑制に貢献します。
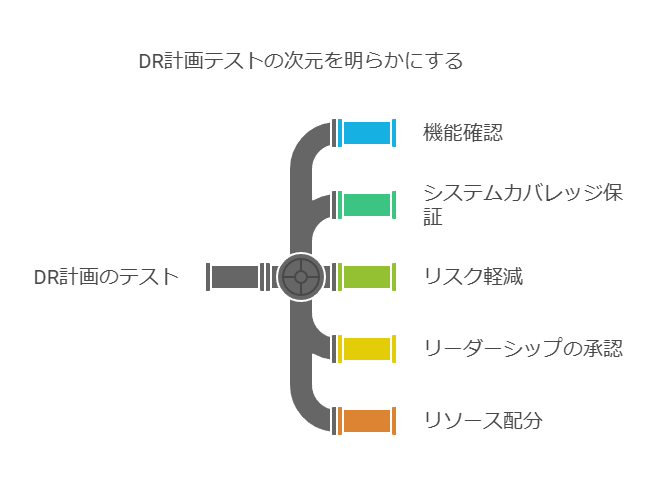
DRプランとプロセスにおけるテストの重要性
DRプロセスが複雑化する中、手順の細分化や煩雑なプロセスにより、DR計画が形骸化しやすいリスクがあります。特にテストが実施されない場合、本番環境での障害発生時に期待通りに機能しない可能性が高まります。効果的なDR戦略では、テストの頻度と精度を確保し、実運用の妨げを最小限に抑えながら計画の実効性を検証することが不可欠です。
このような構成により、クラウドDRの設計・運用におけるリスク軽減と、シームレスなフェイルオーバー管理が実現可能となります。